はじめに
こんにちは。はなたと申します。元々はてなブログをやっていたのですが、プログラミングに関する記事はqiitaで公開しようということで、書いてみようと思います。
ツタヤの在庫検索システム
突然ですが皆さん、TSUTAYAの在庫検索システムを利用したことがありますか?
https://store-tsutaya.tsite.jp/item.html
これはCDやDVDの在庫を、店舗を指定して調べることができるスグレモノです。
しかし1つだけ欠点があります。。。
このシステム、在庫がある店だけを絞り込むことができません。そのため、在庫がある店を探し出すには、全ての店のページを見る必要があります。
5店舗ぐらい調べてみるものの、どこも取扱していないから「この商品はレンタル終わったんだ…」って諦めることが多々あります。
というわけで今回は、在庫がある店の情報のみを抽出し表示するGUIアプリを作ってみました。pyinstallerでexe化もしました。長い記事になりそうなので、最初に動作の様子を貼っておきます。こんな感じです↓
完成GUIプログラムの実際の動作
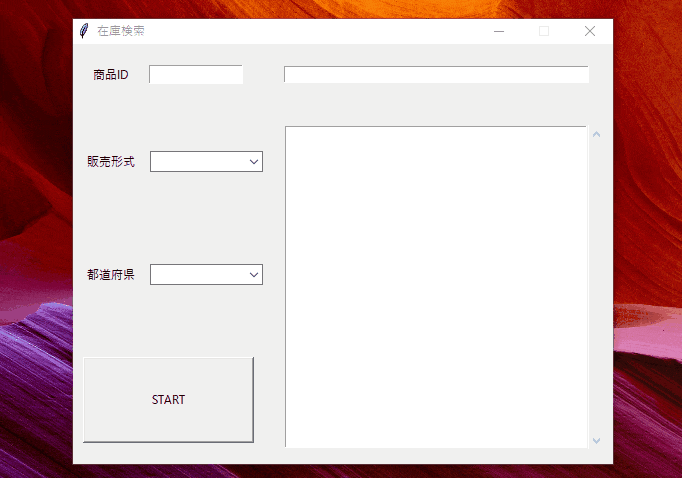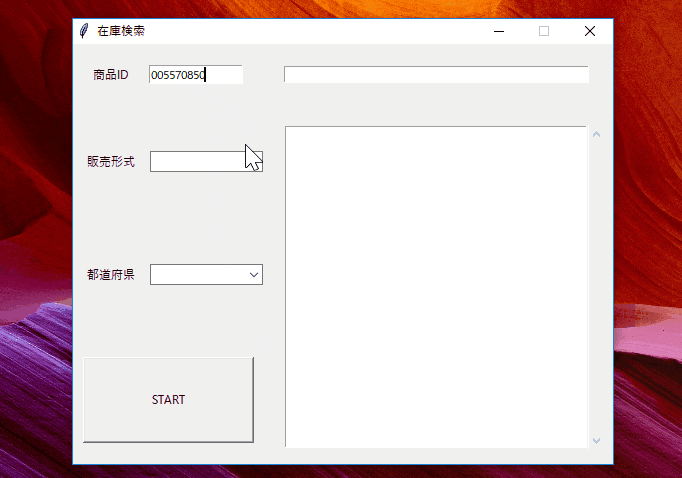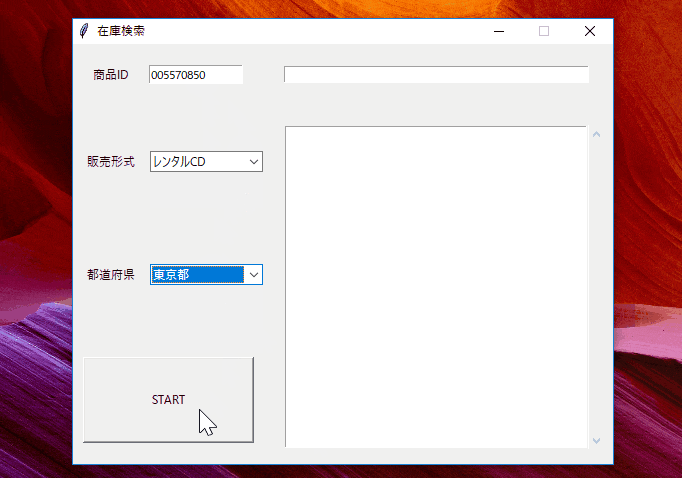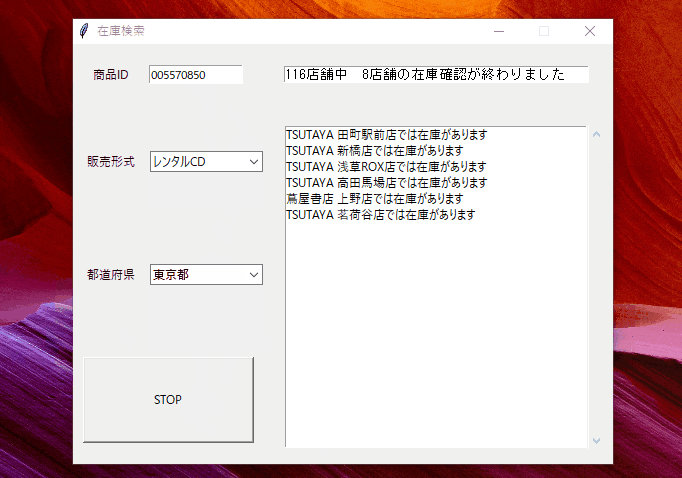
意外と便利ですよね。どうですか?
プログラムの概要はスクレイピングのコードと一緒に後ほど解説します。
GUI部分は…あまり良く分かっておらず、見よう見まねで書いてみたので触れません。
コードの説明
コードの説明をしていきます。頑張って細かく書くつもりですが、たぶん途中で雑になります。予めご了承ください。
完成したコードはgithubにて公開しております。
https://github.com/hatena-hanata/Search_zaiko_app/tree/develop
ライブラリ
from tkinter import *
from tkinter import messagebox
from tkinter import ttk
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
import time
import threading
GUI部分はtkinterを使用しています。
スクレイピングですが、今回は目的のページがJavaScriptでレンダリングされていたので、seleniumを利用します。ブラウザはPhantomJSを使用しました。
ただし、PhantomJSは更新が終了してしまい、現在使用が推奨されていないので、他のヘッドレスブラウザを使用したほうが良いと思います。
threadingはスクレイピングを並列処理させるためです。
スクレイピングの流れ
このアプリの一番の根幹をなす、スクレイピング部分について記述します。
在庫検索には「商品ID」「販売形式(CD or DVD)」「都道府県ID」が必要になります。都道府県IDについては、ひとまず関東地方の4件だけにしています。
1. PhantomJSを起動して商品名を取得
def scraping(self, item_id, item_type, prefecture_id):
# ---ブラウザの起動---
self.print_msg('ブラウザを起動しています…')
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # 要素が見つかるまで10秒待機
self.print_msg('ブラウザを起動しました')
# ---商品名の取得(商品IDの正誤検知)---
self.print_msg('商品名を取得しています…')
item_url = 'https://store-tsutaya.tsite.jp/item/{0}/{1}.html'.format(item_type, item_id)
driver.get(item_url)
item_html = driver.page_source
item_soup = BeautifulSoup(item_html, 'html.parser')
if item_soup.find('div', id='errorBlock') is not None:
self.print_msg('商品ID、販売形式をもう一度確認してください')
driver.quit() # ブラウザを閉じる
self.start_btn['state'] = NORMAL
return
item_title = item_soup.find('div', class_='header').find('h2').find('span').string
self.print_msg('タイトル:{} の在庫を検索します'.format(item_title))
入力された商品ID・販売形式から、商品ページのURLを開きます。こんなページです。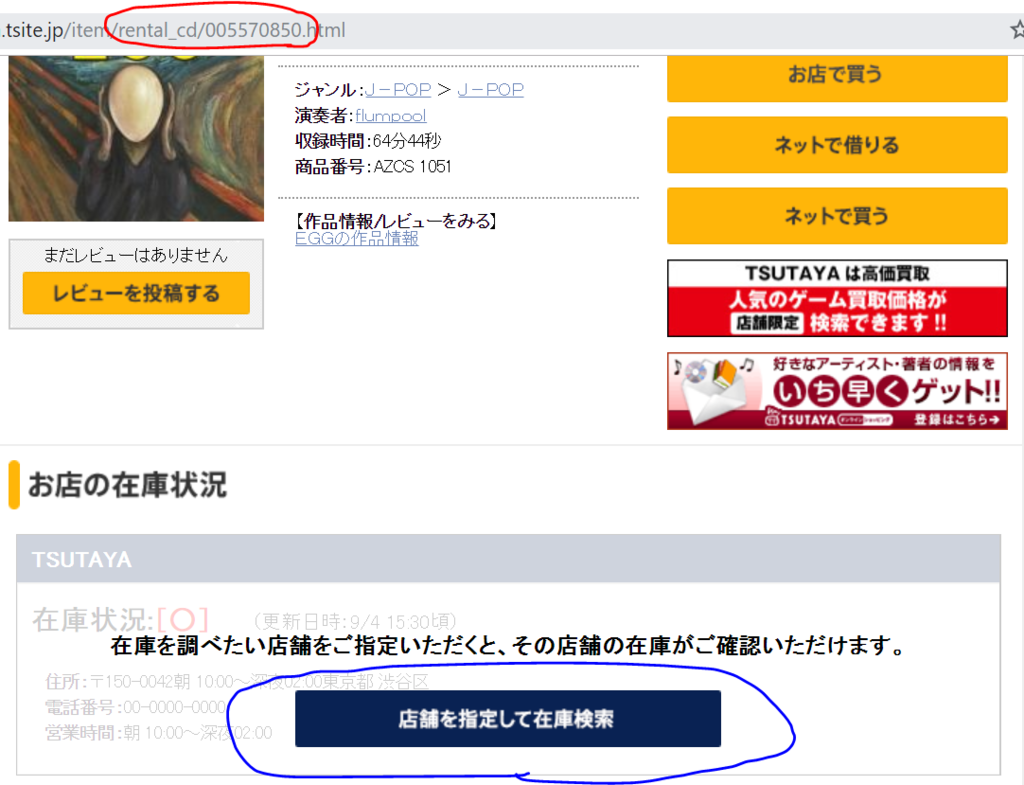
URLのうち、赤い丸で囲まれているところから、商品IDと販売形式が分かります。
そしてこのページから商品名を取得し、表示させます。
ぶっちゃけ商品名取得はそこまで重要ではなく、入力された商品IDのバリデーションチェックを行うのが目的です。もし移動したURL先がエラーページであれば、その旨を表示してスクレイピングを中止します。
2. 店舗一覧ページに移動、掲載ページ数を求める
上の画像の青丸で囲まれているボタンを押して、都道府県を指定したページに移動します。
総店舗数しか分からず、何回ページ送りすれば良いかわからないので、総店舗数から掲載ページ数を求めいています。
ここのコード、ダサいですね。いつか修正します。
def scraping(self, item_id, item_type, prefecture_id):
####
# 店一覧のページをsoupへ
self.print_msg('店舗一覧を取得しています…')
shop_search_url = 'https://store-tsutaya.tsite.jp/tsutaya/articleList?account=tsutaya&' \
'accmd=1&arg=https%3A%2F%2Fstore-tsutaya.tsite.jp%2Fitem%2F{0}%2F{1}' \
'.html&ftop=1&adr={2}' \
.format(item_type, item_id, prefecture_id)
driver.get(shop_search_url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
self.print_msg('店舗一覧の取得が完了しました')
# 掲載ページ数を求める
search_result_num = soup.find(class_='txt_k f_left').string
total_shop_num = int(search_result_num.split('件')[1].split('全')[-1])
if total_shop_num % 20 == 0:
lastpage = total_shop_num / 20
else:
lastpage = int(total_shop_num / 20) + 1
3. ページに掲載されている全店舗のURLを取得する
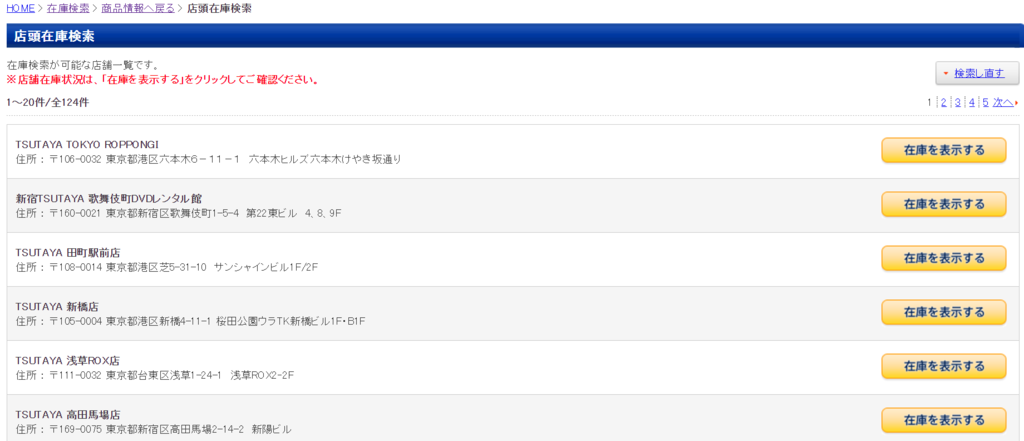
このページの「在庫を表示する」ボタンを押すと、その店舗での商品の在庫状況が書かれたページに移動します。というわけで、このボタンのリンクを取得します。
def scraping(self, item_id, item_type, prefecture_id):
####
# ページごと処理
for page in range(1, lastpage + 1):
# stopボタンが押された
if self.is_active is False:
self.print_msg('作業を中断しました')
return
# 店舗一覧ページに戻る
driver.get(shop_search_url)
# ページを更新
driver.execute_script("ExecuteAjaxRequest('./articleList', 'account=tsutaya&accmd=1&" \
"arg=https%3a%2f%2fstore-tsutaya.tsite.jp%2fitem%2f{0}%2f{1}.html" \
"&searchType=True&adr={2}&pg={3}&pageSize=20&pageLimit=10000&" \
"template=Ctrl%2fDispListArticle_g12', 'DispListArticle'); return false;" \
.format(item_type, item_id, prefecture_id, page))
# ページのsoupを取得する
p_html = driver.page_source
p_soup = BeautifulSoup(p_html, 'html.parser')
# ページに掲載されている全店舗のURL取得
table = p_soup.find('div', id='DispListArticle').find('table')
links = table.find_all('a')
4. 各店舗の在庫情報を取得する
ようやく在庫情報が書かれた、目的のページに到達します。ここで在庫情報を取得します。
商品の取扱がされていない場合、店舗名は表示されません。
def scraping(self, item_id, item_type, prefecture_id):
####
# ページごと処理
for page in range(1, lastpage + 1):
####
for link in links:
# stopボタンが押された
if self.is_active is False:
self.print_msg('作業を中断しました')
return
shop_url = link.get('href')
cnt += self.get_zaiko_info(driver, shop_url) # 在庫情報を取得
self.print_msg('{}店舗中 {}店舗の在庫確認が終わりました'.format(total_shop_num, cnt))
def get_zaiko_info(self, driver, url):
# urlを開いてsoupへ
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 店の名前と在庫情報を取得
shop_name = soup.find('h3', class_='green clearfix').find('a').string
zaiko = soup.find('div', class_='state').find('span').string
# 取扱がない場合1をreturnするだけ、取扱がある場合は在庫情報を表示する
if '-' in zaiko:
return 1
else:
if '○' in zaiko:
self.textField.insert('end', '{}では在庫があります'.format(shop_name))
else:
self.textField.insert('end', '{}では取扱していますが、現在在庫がありません'.format(shop_name))
return 1
pyinstallerを利用してexe化してみる
GUI部分は割愛!ひとまず完成したので、pyinstallerを利用してexe化してみます。
予めpipでpyinstallerやプログラムで使用している外部ライブラリをインストールしておく必要があります。今回だとbeautifulsoupやrequestsですね。
コマンドプロンプトにて
pyinstaller main_app.py --onefile --noconsole
を実行するとexeが作成されます。--onefileオプションを付けたことで、exeのみで動作するようになっています。
ただ、今回のプログラムではPhantomJSを利用します。私の環境ではpathを通しているため、PhantomJSの起動は問題ありませんでした。
配布することを考えたら、プログラムでPhantomJSの場所を指定してあげたほうが良さそうです。
おわりに
初めてqiitaの記事を書きましたが、すごい疲れました。人にプログラムの説明をするのってすごい大変です。
質問やこのコードダサくね?などあれば気軽にコメントください。豆腐メンタルなので、誹謗中傷は受け付けません。