はじめに
最近機械学習のアルゴリズムを数式を理解しながら実装して書き溜めていくことをやっています。
よければ見てください
その中でSVMを実装した際にその中身が数学的に説明されているソースが少なかったので備忘録も含め、書いて行きたいと思います。
以下は『統計的学習の基礎』を参考にしています。自分の解釈なのでミスや誤解を含んでいると思います。気づいたことがあれば指摘していただけると嬉しいです。
SVMとは?
SVMはサポートベクトルマシンの略称で、クラス分割を行うにあたって最も大きいマージンを確保するように分類を行おうと言う考え方です。SVMでは未知のデータに対する分類性能は分離境界ができる限り大きなマージンを持つと良くなると言う考え方の元、分類を行います。分類の境界線に最も近いデータ点をサポートベクトルと呼びます。
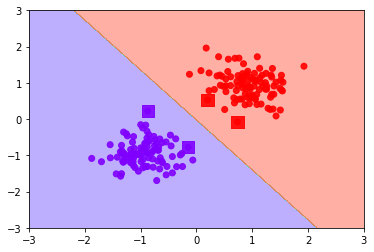
上の図はSVMで分類した例です。サポートベクトルは四角のマーカーで表された4点になります。クラス同士を最もよく分割する直線で分類されていることが感覚的にもよくわかると思います。
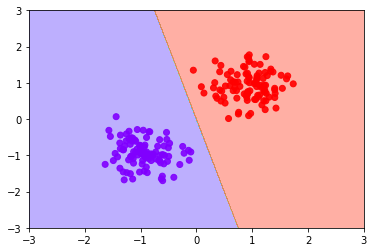
このような分割も可能ですが、SVMによる分類結果と比べると分離境界線からの距離が近くなってしまっています。
線形分離可能な分類タスクにおけるSVM
まずは上の例でもみたような線形境界で完全に分離可能な場合のSVMについて考えます。
$\mathbb{R}^{n}$ 上の超平面 $L$ は $\boldsymbol{x} \in \mathbb{R}^{n}$ を用いて$f(x) = \beta_{0} + \beta^{T} \boldsymbol{x} = 0$と表せます。ここで$\beta_{0}$はスカラー、$\beta$は$\mathbb{R}^{n}$上のベクトルとします。
ここで、$L$上に2点$\boldsymbol{x}_{1}$と$\boldsymbol{x} _{2} $をとると、$\beta _{0} + \beta^{T} \boldsymbol{x} _{1}= 0$と$\beta _{0} + \beta^{T} \boldsymbol{x} _{2}= 0$ より、$\beta^{T} (\boldsymbol{x} _{1} - \boldsymbol{x} _{2}) = 0$なので$\beta$は$L$に垂直なベクトルであることがわかります。
すると、$L$と$\mathbb{R}^{n}$上の任意の点$\boldsymbol{x}$との距離$d$は正射影の考え方から
\begin{align}
d &= \frac{\beta^{T}}{\|\beta\|}(\boldsymbol{x} - \boldsymbol{x} _0) \\
&= \frac{1}{\|\beta\|} f(\boldsymbol{x})
\end{align}
と表せます。
よってマージン$M$を最大化する分離超平面を求めるには以下の最適化問題を解けば良いことがわかります。
\begin{align}
\max _{\beta, \beta_{0}, \|\beta\| = 1} &&& M \\
\text{subject to} &&& y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) \geq M, i=1, 2 ... , N
\end{align}
ここで $\boldsymbol{x_{i}}$は$i$番目の観測値、$y_{i}$は$i$番目の正解ラベルで-1 or 1をとるものとします。
上の最適化問題は$\beta$と$\beta_{0}$を定数倍しても$L$は変化しないので$|\beta|=1$の制約を取り払って
\begin{align}
\max _{\beta, \beta_{0}} &&& M \\
\text{subject to} &&& \frac{1}{\|\beta\|}y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) \geq M, i=1, 2 ... , N
\end{align}
と書き換えることができます。ここで$$M = \frac{1}{|\beta|}$$と置くことで$M$を消去し、$|\beta| > 0$であることから同値な最適化問題
\begin{align}
\min _{\beta, \beta_{0}} &&& \frac{1}{2} \|\beta\|^{2} \\
\text{subject to} &&& y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) \geq 1, i=1, 2 ... , N
\end{align}
を得ることができます。
これは凸最適化問題であり、ラグランジュ関数を
L_{p} = \frac{1}{2}\|\beta\| - \sum^{N}_{i=1}\alpha_{i}[y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) - 1]
とおいてその偏微分
\begin{align}
\frac{\partial L_{p}}{\partial \beta} &= &&\beta - \sum^{N}_{i=1}\alpha_{i}y_{i}\boldsymbol{x}_{i} &= 0\\
\frac{\partial L_{p}}{\partial \beta_{0}} &= &&\sum^{N}_{i=1} \alpha_{i} y_{i} &= 0
\end{align}
を用いて元のラグランジュ関数から$\beta$と$\beta_{0}$を消すと、
L_{D} = \sum^{N}_{i=1}\alpha_{i} - \frac{1}{2}\sum^{N}_{i=1}\sum^{N}_{k=1}\alpha_{i}\alpha_{k}y_{i}y_{k}\boldsymbol{x}_{i}^{T}\boldsymbol{x}_{k}
と変形でき、
\begin{align}
\max _{\beta, \beta_{0}} &&& L_{D} \\
\text{subject to} &&& \alpha_{i} \geq 0\text{ and } \sum^{N}_{i=1} \alpha_{i}y_{i} = 0
\end{align}
が得られます。これはウォルフ双体問題と呼ばれ、この最適化問題は二次計画法によって解くことができます。
この解は元のラグランジュ関数$L_{p}$の条件
\alpha_{i}[y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) - 1] = 0~~~\forall i
を満たす必要がありますが、この条件は以下のように2つに分けることでSVMの概念と結びつけて考えることができます。
- $\alpha_{i} > 0$ の時は $y_{i}(\beta^{T}\boldsymbol{x_{i}} + \beta_{0}) = 1$ となり、点 $\boldsymbol{x_{i}}$ はマージンの境界線上にある。
- $y_{i}(\beta^{T}\boldsymbol{x_{i}} + \beta_{0}) > 1$ の時、点 $\boldsymbol{x_{i}}$ はマージンよりも離れたところにあり、$\alpha_{i}=0$となる。
こうして得られた $\alpha$ から $\hat{\beta}, \hat{\beta}_{0}$ を求めることができ、最適な分離超平面は
\hat{f}(\boldsymbol{x}) = \hat{\beta}^{T}\boldsymbol{x} + \hat{\beta}_{0}
であり、分類は $G(\boldsymbol{x}) = \text{sign}(\hat{f}(\boldsymbol{x}))$で行うことができます。
線形分離不可能な分類タスクにおけるSVM
上記のような線形分離可能なタスクにおけるマージンは絶対的なものとして扱われ、この内部に点があることは許されません。このようなSVMをハードマージンSVMといいます。
それに対して、線形分離不可能な分類タスクに適用するためのSVMは多少のエラーを許容するようになっていなければなりません。具体的に言うと、マージンの端より誤分類側にある一部の点について、その距離に応じたペナルティを与え、このペナルティの最小化とマージンの最大化を行うようなモデルを考えれば良いです。
このモデルを考えるために各点についてペナルティを格納するスラック変数$\xi=(\xi_{1}, \xi_{2}, ... \xi_{N})$を導入します。
このスラック変数を用いて最適化問題の制約条件 $y_{i}(\beta^{T}\boldsymbol{x_{i}} + \beta_{0}) \geq M$ を書き換えてみます。
- $y_{i}(\beta^{T}\boldsymbol{x_{i}} + \beta_{0}) \geq M - \xi_{i}$
- $y_{i}(\beta^{T}\boldsymbol{x_{i}} + \beta_{0}) \geq M(1 - \xi_{i})$
直感的なものは前者ですね。一部の点についてマージンからの距離$\xi_{i}$を許容すると言う形になっています。しかし、ここから導かれる最適化問題は非凸の最適化問題になってしまいます。
これに対して後者は凸最適化問題を解くことになり、標準的なSVMではこちらを用います。
$\sum\xi_{i}$の値を上から抑えることでマージンの端より誤分類側になってしまう点を減らし、誤分類される点を減らすことができます。この考え方から、解くべき最適化問題が導かれ、
\begin{align}
\min _{\beta, \beta_{0}} &&& \frac{1}{2} \|\beta\|^{2} + C \sum^{N}_{i=1}\xi_{i}\\
\text{subject to} &&& y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) \geq 1 - \xi_{i}\\
&&& \xi_{i} \geq 0
\end{align}
のようになります。スラック変数の重みを抑えるパラメータは$C$であり、$C = \infty$の時、誤分類を認めないハードマージンSVMになり、$C$が小さくなるほど誤分類に寛容なモデルになります。
ラグランジュ関数は
L_{p} = \frac{1}{2}\|\beta\| + C \sum^{N}_{i=1}\xi_{i} - \sum^{N}_{i=1}\alpha_{i}[y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) - (1-\xi_{i})] - \sum^{N}_{i=1} \mu_{i}\xi_{i}
であり、これを$\beta, \beta_{0}, \xi_{i}$について最小化する問題になりました。偏微分を0と置くことで
\begin{align}
\beta &= \sum^{N} _{i=1} \alpha_{i}y_{i}\boldsymbol{x}_{i} \\
0 &= \sum^{N}_{i=1} \alpha_{i}y_{i} \\
\alpha_{i} &= C - \mu_{i} ~~~ \forall i
\end{align}
の条件が得られ、先ほどのように元のラグランジュ関数に代入することで双体問題を得ることができます。
実は先ほど導入した$C$や$\xi_{i}$などの変数は計算の過程で消え、結果えられるラグランジュ関数は
L_{D} = \sum^{N}_{i=1}\alpha_{i} - \frac{1}{2}\sum^{N}_{i=1}\sum^{N}_{k=1}\alpha_{i}\alpha_{k}y_{i}y_{k}\boldsymbol{x}_{i}^{T}\boldsymbol{x}_{k}
となります。
先ほどと全く同じ形ですね。ただし制約条件が
0 \leq\alpha_{i} \leq C , \sum^{N}_{i=1} \alpha_{i}y_{i} = 0
のように変化しています。これでソフトマージンSVMについても簡単な二次の凸最適化問題に変換し、二次計画法などによって解くことが可能になりました。
この最適化問題にはKKT条件として
\alpha_{i}[y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) - (1-\xi_{i})] = 0~~~\forall i \\
\mu_{i}\xi_{i} = 0\\
y_{i}(\beta^{T}\boldsymbol{x} _{i} + \beta_{0}) - (1-\xi_{i}) \geq 0
が含まれています。先ほどと同じように解釈してみると以下のことが言えます。
- $\xi_{i} > 0$ の点については$\mu_{i}=0$であり、$\alpha_{i}=C$ である。このような点はマージンの端よりも誤分類側にある。
- $\xi_{i} = 0$ の点については $0 < \alpha_{i} < C$ であり、マージンの端に乗っている。
- その他の点については $\xi_{i},~ \alpha_{i} = 0$であり、マージンよりも離れたところの点である。
この分離超平面を決定するサポートベクトルは上記3つのうち、上2つの点となります。
分類はハードマージンSVMと同様に行え、得られた $\alpha$ から $\hat{\beta}, \hat{\beta}_{0}$ を求めて分離超平面
\hat{f}(\boldsymbol{x}) = \hat{\beta}^{T}\boldsymbol{x} + \hat{\beta}_{0}
を作り、分類は $G(\boldsymbol{x}) = \text{sign}(\hat{f}(\boldsymbol{x}))$で行うことができます。
まとめ
今回は、SVMを数学的に理解してみようということで学習したことをまとめてみました。
機械学習を学ぼうと思ってwebで情報を探すと、9割くらいがモデルの概念の説明からいきなりライブラリを用いた実装になっていて、その背景の数学的な考え方を知りたいひとが情報に行きつきにくい状況にあると感じます。(数式で理解したい人は少数派なのかな、、、)
ちなみに改行が完全におかしいのはなんでなんでしょうか?解決方法がわかりません。
数式で見るとモデルの概念やなぜ学習がうまくいくのかなどが非常にわかりやすくなるのでそんな情報に簡単にアクセスできるようになるといいなというポエムでしめくくりたいと思います。
長い記事でしたがお読みいただき、ありがとうございました。