レコメンドアルゴリズムの協調フィルタリングと内容ベース(コンテンツベース)フィルタリングについて、それぞれの長所と短所・実装方法をまとめたときの学習メモです。協調フィルタリングのレコメンドエンジンを以前開発したので、つぎは内容ベースのレコメンドエンジンを開発したいです。( ・ㅂ・)و
内容ベースと協調フィルタリングの長所と短所
■ 長所と短所の一覧表
| 分類 | 協調フィルタリング | 内容ベース |
|---|---|---|
| 多様性 | o | x |
| ドメイン知識 | o | x |
| スタートアップ問題 | x | △ |
| 利用者数 | x | o |
| 被覆率 | x | o |
| 類似アイテム | x | o |
| 少数はの利用者 | x | o |
| ※この表は神嶌 敏弘先生が人工知能学会誌に連載した解説記事『推薦システムのアルゴリズム』から転載したものです。 |
アルゴリズムの説明
■ 協調フィルタリングとは
アイテム利用者の行動履歴を元にレコメンドする方法です。Amazonの『この商品を買った人は、こんな商品も』機能が有名です。協調フィルタリングによるレコメンドはユーザの行動を元にレコメンドする方法です。
■ 内容ベース(コンテンツベース)フィルタリングとは
アイテムの特徴ベクトルで類似度ソートしてレコメンドする方法です。
グルメサイトでユーザが入力した『新宿・エスニック料理』というキーワードに関連付けられたお店が表示される場合が該当します。内容ベースによるレコメンドはアイテムの特徴を元にレコメンドする方法です。
特性の詳細について
■ 多様性
協調: o 内容ベース: x
内容ベースでは商品内容に記載されていない情報はレコメンドされませんが、協調フィルタリングでは他の利用者を通じてレコメンドされるため自身がしらない情報でもレコメンド出来ます。
■ ドメイン知識
協調: o 内容ベース: x
協調フィルタリングでは対象アイテムについて情報や知識が一切なくとも他の利用者の行動履歴を通じてレコメンド可能です。一方内容ベースではアイテムの特徴を特徴ベクトルに変換する設計が必須です。
■ スタートアップ問題
協調: x 内容ベース: △
新規システムで他の利用者がいない状況や、利用者のプロファイル取得が難しい状況では協調フィルタリングを利用できません。内容ベースではアイテムの特徴さえ取得できれば利用者プロファイルを取得できない状況でもレコメンド可能です。
■ 利用者数
協調: x 内容ベース: o
協調フィルタリングではまだ誰も評価していないアイテムの評価ができません。一方内容ベースでは利用者がいなくても特徴からレコメンドが可能です。
■ 被覆率
協調: x 内容ベース: o
利用者数と同様に、協調フィルタリングではまだ誰も評価していないアイテムの評価ができないため、全ての商品を網羅してレコメンドすることができません。
■ 類似アイテム
協調: x 内容ベース: o
アイテムの特徴を一切考慮しない協調フィルタリングでは例えばマグカップの色違いについて見分けることが出来ません。内容ベースでは類似度が高すぎるアイテムを足切りすることで色違い問題を防ぐことが出来ます。
■ 少数派の利用者
協調: x 内容ベース: o
協調ベースでは特定アイテムの利用者が極めて少数の場合、類似したアイテムを予想できないためレコメンドできません。内容ベースではアイテムの特徴によってレコメンドできます。
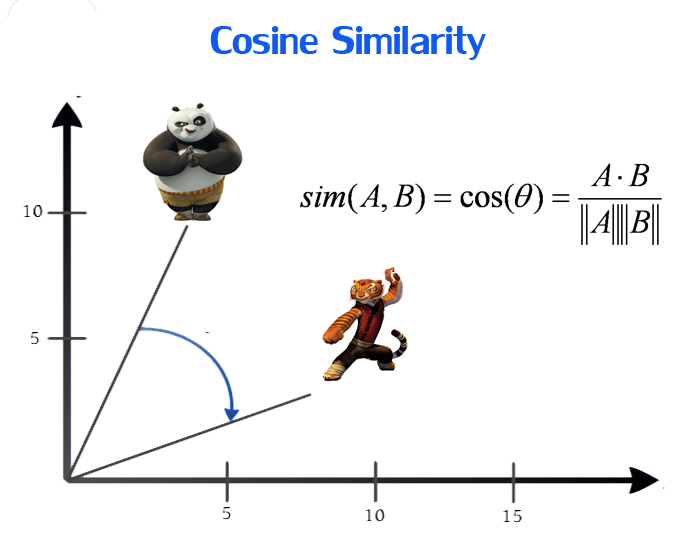
内容ベースフィルタリングの類似度計算方法
アイテムの特徴を抽出してベクトル化してしまえばCosine Similarityによって類似度を計算することが出来ます。商品Xと商品A-Fの類似度を計算してソートすれば内容ベースフィルタリングによるレコメンドが実現します。
転載:Five most popular similarity measures implementation in python
# -*- coding: utf-8 -*-
from math import sqrt
def similarity(tfidf1, tfidf2):
"""
Get Cosine Similarity
cosθ = A・B/|A||B|
:param tfidf1: list[list[str, float]]
:param tfidf2: list[list[str, float]]
:rtype : float
"""
tfidf2_dict = {key: value for key, value in tfidf2}
ab = 0 # A・B
for key, value in tfidf1:
value2 = tfidf2_dict.get(key)
if value2:
ab += float(value * value2)
# |A| and |B|
a = sqrt(sum([v ** 2 for k, v in tfidf1]))
b = sqrt(sum([v ** 2 for k, v in tfidf2]))
return float(ab / (a * b))
内容ベースフィルタリングの実装方法
今いくよ・くるよ師匠とコロコロチキチキペッパーズのWikipedia文章から形態素解析して名詞を抽出し頻出名詞数/全名詞数を特徴ベクトルとしました。この手法をTF-IDFと呼びます。
# -*- coding: utf-8 -*-
from math import sqrt
def similarity(tfidf1, tfidf2):
"""
Get Cosine Similarity
cosθ = A・B/|A||B|
:param tfidf1: list[list[str, float]]
:param tfidf2: list[list[str, float]]
:rtype : float
"""
tfidf2_dict = {key: value for key, value in tfidf2}
ab = 0 # A・B
for key, value in tfidf1:
value2 = tfidf2_dict.get(key)
if value2:
ab += float(value * value2)
# |A| and |B|
a = sqrt(sum([v ** 2 for k, v in tfidf1]))
b = sqrt(sum([v ** 2 for k, v in tfidf2]))
return float(ab / (a * b))
# 今いくよ・くるよ師匠
ikuyo_kuruyo = [
['京都', 0.131578947369],
['漫才', 0.122807017544],
['お笑い', 0.122807017544],
['ラジオ', 0.105263157894],
['吉本興業', 0.09649122807],
['芸人', 0.09649122807],
['いくよ', 0.0701754385966],
['コンビ', 0.0701754385966],
['大阪', 0.0526315789474],
['名人', 0.0438596491229],
['上方', 0.0438596491229],
['花王', 0.0438596491229],
]
# コロチキ
chikichiki = [
['お笑い', 0.169014084507],
['西野', 0.12676056338],
['大阪', 0.112676056338],
['ナダル', 0.0845070422536],
['コンビ', 0.0845070422536],
['優勝', 0.0704225352114],
['コロコロチキチキペッパーズ', 0.0704225352114],
['ネタ', 0.0704225352114],
['芸人', 0.056338028169],
['吉本興業', 0.056338028169],
['漫才', 0.056338028169],
['キングオブコント', 0.0422535211267],
]
# 類似度の計算
print similarity(ikuyo_kuruyo, chikichiki)
"""
>>>実行結果
0.521405857242
"""
内容ベースフィルタリングをCosineSimilarityで実装する利点
特徴ベクトルで内容ベースフィルタリングを実装すると、重み付けを変更したいときにベクトルを1つ追加してすれば簡単に反映できるため柔軟な運用が可能になります。たとえば『DVD』という特徴を2割追加して類似度を引き上げてみます。
# 今いくよ・くるよ師匠
ikuyo_kuruyo = [
['DVD', 0.2],
['京都', 0.131578947369],
['漫才', 0.122807017544],
...
]
# コロチキ
chikichiki = [
['DVD', 0.2],
['お笑い', 0.169014084507],
['西野', 0.12676056338],
...
]
# 類似度の計算
print similarity(ikuyo_kuruyo, chikichiki)
"""
>>>実行結果
0.661462974013
"""
ライブラリありますよ
Webの文章を形態素解析して名詞の数をカウントするTF-IDF機能とCosineSimilarityを計算するライブラリsimple_tfidf_japaneseをPyPiで公開しています。実装142行なので短時間でソースコードを読めると思います。
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
from simple_tfidf_japanese.tfidf import TFIDF
ikuyo_wikipedia_url = 'https://ja.wikipedia.org/wiki/%E4%BB%8A%E3%81%84%E3%81%8F%E3%82%88%E3%83%BB%E3%81%8F%E3%82%8B%E3%82%88'
korochiki_wikipedia_url = 'https://ja.wikipedia.org/wiki/%E3%82%B3%E3%83%AD%E3%82%B3%E3%83%AD%E3%83%81%E3%82%AD%E3%83%81%E3%82%AD%E3%83%9A%E3%83%83%E3%83%91%E3%83%BC%E3%82%BA'
ikuyo_tfidf = TFIDF.gen_web(ikuyo_wikipedia_url)
chiki_tfidf = TFIDF.gen_web(korochiki_wikipedia_url)
# 類似度計算
print TFIDF.similarity(ikuyo_tfidf, chiki_tfidf)
協調フィルタリングの類似度計算方法と実装方法
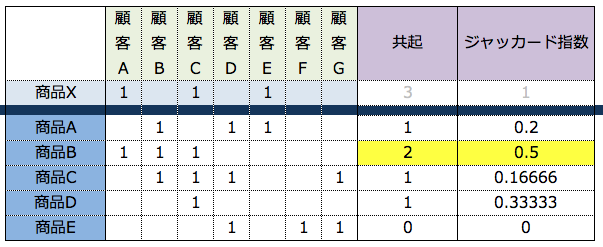
協調フィルタリングの類似度計算方法は複数存在します。今回は共起とジャッカード指数を使う例を紹介します。
■ サンプルデータ
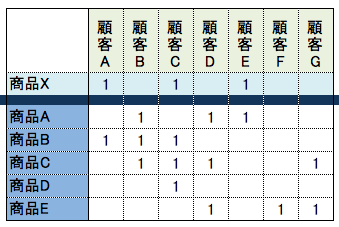
■ 共起
商品Xを買った顧客が他の商品を何個買ったかで計算します。ジャッカード指数より精度が低いですが、簡単に計算できます。たとえば商品Xと商品Aの共起値を計算すると顧客Eのみ両商品を購入しているので共起値『1』となります。特徴は計算時間がちょっぱやなこと。
■ ジャッカード指数の計算方法
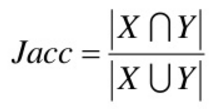
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import unicode_literals
from collections import defaultdict
def jaccard(e1, e2):
"""
ジャッカード指数を計算する
:param e1: list of int
:param e2: list of int
:rtype: float
"""
set_e1 = set(e1)
set_e2 = set(e2)
return float(len(set_e1 & set_e2)) / float(len(set_e1 | set_e2))
# 商品Xを購入した顧客IDが1,3,5ということ
product_x = [1, 3, 5]
product_a = [2, 4, 5]
product_b = [1, 2, 3]
product_c = [2, 3, 4, 7]
product_d = [3]
product_e = [4, 6, 7]
# 商品データ
products = {
'A': product_a,
'B': product_b,
'C': product_c,
'D': product_d,
'E': product_e,
}
# Xとの共起値を計算する
print "共起"
r = defaultdict(int)
for key in products:
overlap = list(set(product_x) & set(products[key]))
r[key] = len(overlap)
print r
# Xとのジャッカード指数を計算する
print "ジャッカード指数"
r2 = defaultdict(float)
for key in products:
r2[key] = jaccard(product_x, products[key])
print r2
"""
>>> python cf.py
共起
defaultdict(<type 'int'>, {u'A': 1, u'C': 1, u'B': 2, u'E': 0, u'D': 1})
ジャッカード指数
defaultdict(<type 'float'>, {u'A': 0.2, u'C': 0.16666666666666666, u'B': 0.5, u'E': 0.0, u'D': 0.3333333333333333})
"""
■ 結果まとめ
共起と比較してジャッカード指数の方が、商品Xと商品A,C,Dの類似度が詳細に計算できています。その分計算コストが高いです。