アップルすごい5203倍
このプログラムを使うとリーマンショック前夜の2008年1月にインと2009,2010年にインでリターンがどれくらい変化するか計算できるようになります。この記事は2020年5月3日バフェット氏が米4大航空会社の株を全部売った時期に書いた記事です。
米国株式3182種について、2000年からの配当と株式分割込みリターンをPythonで計算する方法です。
YahooFinanceのデータを使っています。検算は数値データ検索エンジンの quandl.com にある WIKI/PRICES データセットを使っています。前半では個別銘柄のリターン調査、後半では3182種一括調査しています。
start_date = '2001-01-01'
end_date = '2020-05-01'
# サンプル
アップル(AAPL): 5203.19倍
マイクロソフト(MSFT): 44.28倍
ウォルマート(WMT): 5.02倍
フェイスブック(FB): 5.34倍
アマゾン(AMZN): 178.12倍
グーグル(GOOG): 53.94倍
この記事は2020年5月コロナショックでカブ暴落して航空株を買う事は宝くじと呼ばれていた時期に書いた
 WTIの原油先物2020年5月限がマイナスになった
WTIの原油先物2020年5月限がマイナスになった
ゴール
次のようなシートを作って遊びます

1万ドル投資したときの2020年5月1日の倍率
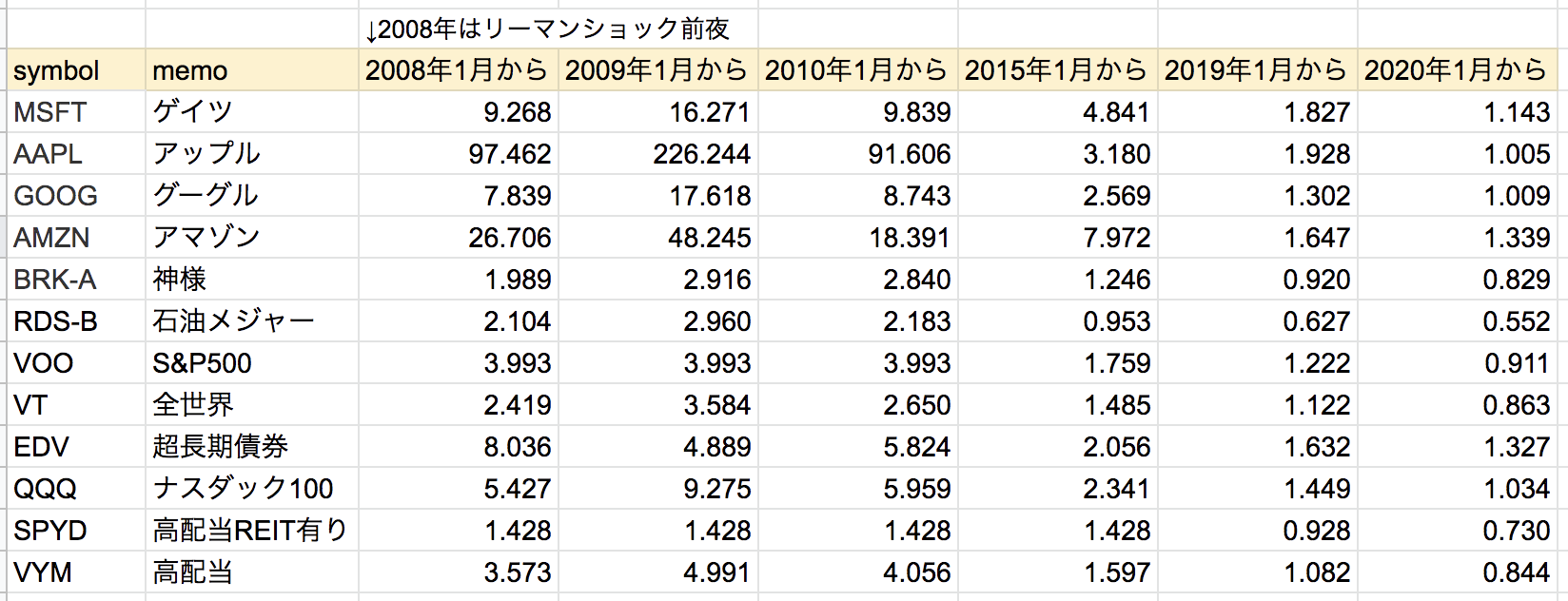
※SPYDは2015年10月開始のETFです。
使っている手法
Yahoo!Financeのデータセットにはデイリー米株取引データがあります。その中から株価、配当、株式分割データを抽出して1万ドル投資時リターンを計算します。
株を買って余ったお金は次の配当まで持ち越します。また配当金は当日余ったお金と一緒に再投資しています。
$ python test_y.py
スタート: 10869株, 余り$0.5200000000004366
2005-02-28 00:00:00:株式分割 2.0倍. 10869株 -> 21738株
2012-08-09 00:00:00:配当ゲット $8229.35466. 再投資 106株追加 合計21844株, 残キャッシュ36.07466000000204$
2012-11-07 00:00:00:配当ゲット $8269.48308. 再投資 118株追加 合計21962株, 残キャッシュ67.97774000000209$
2013-02-07 00:00:00:配当ゲット $8314.154340000001. 再投資 142株追加 合計22104株, 残キャッシュ15.492080000003625$
2013-05-09 00:00:00:配当ゲット $9630.93384. 再投資 166株追加 合計22270株, 残キャッシュ41.6659200000031$
2013-08-08 00:00:00:配当ゲット $9703.2617. 再投資 165株追加 合計22435株, 残キャッシュ46.22762000000148$
2013-11-06 00:00:00:配当ゲット $9775.153849999999. 再投資 147株追加 合計22582株, 残キャッシュ0.31147000000055414$
2014-02-06 00:00:00:配当ゲット $9839.20322. 再投資 148株追加 合計22730株, 残キャッシュ53.754689999999755$
2014-05-08 00:00:00:配当ゲット $10683.099999999999. 再投資 140株追加 合計22870株, 残キャッシュ57.65468999999757$
2014-06-09 00:00:00:株式分割 7.0倍. 22870株 -> 160090株
2014-08-07 00:00:00:配当ゲット $75242.3. 再投資 873株追加 合計160963株, 残キャッシュ21.164689999990514$
2014-11-06 00:00:00:配当ゲット $75652.61. 再投資 759株追加 合計161722株, 残キャッシュ47.014689999996335$
... 略
2019-08-09 00:00:00:配当ゲット $135115.75. 再投資 676株追加 合計176151株, 残キャッシュ14.854689999949187$
2019-11-07 00:00:00:配当ゲット $135636.27. 再投資 524株追加 合計176675株, 残キャッシュ29.444689999945695$
2020-02-07 00:00:00:配当ゲット $136039.75. 再投資 425株追加 合計177100株, 残キャッシュ56.444689999945695$
_/_/_/_/_/_/_/_/_/_/_/_/_/
スタート: 10869株
ゴール: 177100株
スタート株価: $0.92
ゴール株価: $293.8
最終資産: 52031980.0ドル, 余り56.444689999945695ドル
倍率: 5203.198倍
配当回数: 31回
直近配当利回り: 0.0024060244352091995
実装 Yahoo! Finance market data downloader利用
yfincanceも検算のquandleも pandas.DataFrame なので似た実装になります
yfincance からウォルマートのデータ取得して2000年から2020年のリターン計算実装(クリックで開く)
フィジビリ確認する実装なのできちゃない...
# -*- coding: utf-8 -*-
import math
import yfinance as yf
# WMT, GOOG, RDS-B, BRK-A, VOO
msft = yf.Ticker("AAPL")
print(msft.info)
start_date = '2001-01-01'
end_date = '2020-05-01'
data = msft.history(start=start_date, end=end_date)
date = 'Date'
price = 'Close' # 価格
dividend = 'Dividends' # 1株 配当
splits = 'Stock Splits' # 株式分割数
print("********")
print("data.head()")
print(data.head())
# 日付で逆順ソート
data = data.sort_values(date)
tail = data.tail(1)
head = data.head(1)
print("********")
print("tail")
print(tail)
print(float(tail.Close))
print("********")
df = data[(data[dividend] > 0) | (data[splits] > 0)]
print(df)
# 計算するマン
# 最終日の価格データをとる
base = float(10000) # 1万ドルスタート
v = math.floor(base / float(head.Close))
v_start = v
cache = base - v * float(head.Close)
print("スタート: {}株, 余り${}".format(v, cache))
ct = 0 # 配当回数
yi = 0 # 直近配当利回り
for index, row in df.iterrows():
# 配当もらう
if row[dividend] > 0:
# 配当もらう
ct += 1
d = v * row[dividend]
cache += d
yi = row[dividend] / row[price]
# 配当再投資
v2 = math.floor(cache / row[price])
v += v2
cache = cache - v2 * row[price]
print("{}:配当ゲット ${}. 再投資 {}株追加 合計{}株, 残キャッシュ{}$".format(
row.name, d, v2, v, cache))
# 分割
if float(row[splits]) != float(0.0):
before_v = v
v = int(v * row[splits])
print(
'{}:株式分割 {}倍. {}株 -> {}株'.format(row.name, row[splits], before_v, v))
# 最終日処理
print("_/_/_/_/_/_/_/_/_/_/_/_/_/")
total = v * float(tail.Close)
print("スタート: {}株".format(v_start))
print("ゴール: {}株".format(v))
print("スタート株価: ${}".format(float(head.Close)))
print("ゴール株価: ${}".format(float(tail.Close)))
print("最終資産: {}ドル, 余り{}ドル".format(total, cache))
print("倍率: {}倍".format(total / base))
print("配当回数: {}回".format(ct))
print("直近配当利回り: {}".format(yi))
Quandleで検算実装(クリックで開く)
# -*- coding: utf-8 -*-
import quandl
import math
quandl.ApiConfig.api_key = '*****' # Quandlから取得した自分のAPIキー
# pandas dataframe
# 'AAPL', 'MSFT', 'WMT', GOOG, FB, AMZN
data = quandl.get_table('WIKI/PRICES', ticker=['WMT'],
qopts={'columns': [
'ticker', 'date', 'adj_close', 'Ex-Dividend', 'split_ratio']},
date={'gte': '2000-01-01', 'lte': '2020-04-31'},
paginate=True)
date = 'date'
price = 'adj_close' # 価格
dividend = 'ex-dividend' # 1株 配当
splits = 'split_ratio' # 株式分割数
print("********")
print("data.head()")
print(data.head())
# 日付で逆順ソート
data = data.sort_values('date')
tail = data.tail(1)
head = data.head(1)
print("********")
print("tail")
print(tail)
print(float(tail.adj_close)) # 最終日データといっても2018年
print("********")
df = data[(data['ex-dividend'] > 0) | (data['split_ratio'] > 1)]
print(df)
# 計算するマン
# 最終日の価格データをとる
base = float(10000) # 1万ドルスタート
v = math.floor(base / float(head.adj_close))
v_start = v
cache = base - v * float(head.adj_close)
print("スタート: {}株, 余り${}".format(v, cache))
ct = 0 # 配当回数
yi = 0 # 直近配当利回り
for index, row in df.iterrows():
# 配当もらう
if row[dividend] > 0:
# 配当もらう
ct += 1
d = v * row[dividend]
cache += d
yi = row[dividend] / row[price]
# 配当再投資
v2 = math.floor(cache / row[price])
v += v2
cache = cache - v2 * row[price]
print("{}:配当ゲット ${}. 再投資 {}株追加 合計{}株, 残キャッシュ{}$".format(
row[date], d, v2, v, cache))
# 分割
if float(row[splits]) != float(1.0):
before_v = v
v = int(v * row[splits])
print(
'{}:株式分割 {}倍. {}株 -> {}株'.format(row[date], row[splits], before_v, v))
# 最終日処理
print("_/_/_/_/_/_/_/_/_/_/_/_/_/")
total = v * float(tail.adj_close)
print("スタート: {}株".format(v_start))
print("ゴール: {}株".format(v))
print("スタート株価: ${}".format(float(head.adj_close)))
print("ゴール株価: ${}".format(float(tail.adj_close)))
print("最終資産: {}ドル, 余り{}ドル".format(total, cache))
print("倍率: {}倍".format(total / base))
print("配当回数: {}回".format(ct))
print("直近配当利回り: {}".format(yi))
$ pip freeze(クリックで開く)
$ pip freeze
autopep8==1.5.2
beautifulsoup4==4.9.0
certifi==2020.4.5.1
chardet==3.0.4
idna==2.9
inflection==0.4.0
lxml==4.5.0
more-itertools==8.2.0
multitasking==0.0.9
numpy==1.18.2
pandas==1.0.3
pandas-datareader==0.8.1
pycodestyle==2.5.0
python-dateutil==2.8.1
pytz==2019.3
Quandl==3.5.0
requests==2.23.0
six==1.14.0
soupsieve==2.0
urllib3==1.25.9
yfinance==0.1.54
米株3000社の会社コード取得
WikiPricesの会社一覧から米株3000社の会社コード取得
# -*- coding: utf-8 -*-
import math
import yfinance as yf
def main():
print("start")
companies = showCode()
total = len(companies)
ct = 0
path = "result.csv"
# code, total / base, total, ct, v_start, v, float(head.Close), float(tail.Close), cache
with open(path, mode='w', encoding="utf-8") as f:
f.write("{}\n".format("code,倍率,合計金額($),配当回数,初期株数,最終株数,初期株価($),最終株価($),余剰キャッシュ($),直近配当利回り"))
for code in companies:
ct += 1
if ct % 100 == 0:
print("{}/{}".format(ct, total))
try:
r = analytics(code)
except:
continue
print(r)
f.write("{}\n".format(r))
def showCode():
path = 'companiex.txt'
with open(path) as f:
c = [s.strip() for s in f.readlines()]
return c
def analytics(code):
t = yf.Ticker(code)
start_date = '2000-01-01'
end_date = '2020-05-01'
data = t.history(start=start_date, end=end_date)
date = 'Date'
price = 'Close' # 価格
dividend = 'Dividends' # 1株 配当
splits = 'Stock Splits' # 株式分割数
# 日付で逆順ソート
data = data.sort_values(date)
tail = data.tail(1)
head = data.head(1)
df = data[(data[dividend] > 0) | (data[splits] > 0)]
# 計算するマン
# 最終日の価格データをとる
base = float(10000) # 1万ドルスタート
v = math.floor(base / float(head.Close))
v_start = v
cache = base - v * float(head.Close)
ct = 0 # 配当回数
yi = 0 # 直近配当利回り
for index, row in df.iterrows():
# 配当もらう
if row[dividend] > 0:
# 配当もらう
ct += 1
d = v * row[dividend]
cache += d
yi = row[dividend] / row[price]
# 配当再投資
v2 = math.floor(cache / row[price])
v += v2
cache = cache - v2 * row[price]
# 分割
if float(row[splits]) != float(0.0):
v = int(v * row[splits])
# 最終日処理
total = v * float(tail.Close)
return ",".join([str(i) for i in [code, total / base, total, ct, v_start, v, float(head.Close), float(tail.Close), cache, yi]])
if __name__ == '__main__':
main()
素人が個別銘柄を吟味する投資手法は正しいか?
ここは個人の運用メモです。
市場予測は難しく、株式の売買手数料は馬鹿になりません。
S&P500 をベンチマークとして、個別銘柄吟味が長期でベンチマークをアウトパフォームできるとはとても思えません。正しいかは不明、リスクとリターンが高いため立場によって異なると思います。退職した人には間違いなくお勧めできない手法です。
一方で新型肺炎が株式に大きな影響をあたえるなか、特定セクターは大揺れしています。REIT、人によっては石油株、航空株、クルーズ船株といったセクターの銘柄はできればお断りしたく、長期の経済低迷する可能性を考えると、バリュー投資に回帰したくなってyfinanceでポチポチしらべていました。
個別物色するまえに、まずは現金&株式&債権の資産分配比率を決定し、その中でも成長株対割安株、大型小型、国内と海外といった運用方針策定しましょう。それこそが将来のリターンに直結します。またアクティブ投資は手数料と情報速度と理解度でファンドに敗北するためパッシブ投資(絶対に売らないマンになって握力勝負)が良いです。握り続けるために最低15年以上は利益を出し続けているバリュー銘柄、もしくはETFで広く分散しましょう。(個人の見解です。)
なぜ握り続けるのか、それは1年間でトップ20以上の上昇を記録した日を2-3日ノーポジで過ごすだけで株式のリターンは大幅に低下するからです。だけど株ってとにかく面白いから個別物色をライブドアのころから、ついやらかしてしまうーー。
2020年5月の運用方針例(個人の見解です。)
# 暴落時は株式比率は100%にする
S&P500 30%
VYM 30%
配当個別バリュー株 20%
新興国 インド 10%
フリー 10%
# 通常時
長期債券(EDV)の比率を15%にする
株式比率は85%にする
S&P500 25%
VYM 25%
配当個別バリュー株 20%
新興国 インド 10%
フリー 5%
# 暴落と通常の判定
定義: 暴落相場
株価が暴落前高値から35%以上の下落
FRB, 日銀, ECBが利下げをした。政策金利が0.5%未満
定義: 通常
株価が暴落前高値の70%以上を回復して1年が経過
FRB政策金利が1.5%以上
株式と長期債券のポートフォリオは株式クラッシュのヘッジになる
ここは個人の運用メモです。
よくある株式と債券のポートフォリオの話です。
EDVに代表される超長期米国債ETFは政策金利が下がると価格が上がる特性があります。EDVはデュレーション25年あるため、金利感応が高く1%政策金利が変化すると25%価格が動きます。株式暴落時はFRBは政策金利を大きく引き下げる傾向にあります。結果として株式暴落時はEDVは価格を大きく上げる負の相関になっています。
政策金利が値ごろ感で高い4-6%のときにEDVを仕込み、株式暴落時に高くなったEDVを売ることで現金を確保し安くなった株を仕込むコンボは強力です。
この手法が破綻する方法があります。金利感応が高いため過去の米国超インフレ時期(1970-1980年代)のように政策金利が10+%になるとEDVは紙くずになります。ただ超インフレ = 株高だしきっと大丈夫なはず。大丈夫だよね?政策金利が0%のときに考えることじゃないか。
さいごに
バークシャーハサウェイ(BRK-A)は配当を出さないことで有名です。5年間のリターンは今回のツールで計算するとリターンは1.24倍。一方S&P500 ETF VOOは1.73倍です。10年間リターンでも2.83倍と3.95倍とS&P500がアウトパフォームしています。バークシャーハサウェイ率いるバフェット氏は御年89歳。彼の目線は長期なのか短期なのかどちらなんでしょう。
たくさんのファンに囲まれコークを飲みながら年次総会(今年はオンライン!)する投資の神様は今回も楽しそうでした。
