1. 目的
Elasticsearch公式サイトの情報をもとに、enrich processorの仕組みと簡単な判例について解説します。単に和訳するだけではなく、説明が不足していると私が感じたところは逐次情報を追記しています。
2. enrich processorとは
enrich processorは、 ElasticsearchのIndexにこれから格納される(incoming)documentに対して、既存のIndexからdocumentを追加するための機能です。 Elasticsearchがもつingest pipelineの仕組みの1つです。 Elasticsearchにおいて、Ingest pipelineとは、Elasticsearchのインデックスとしてドキュメントを登録する前に、 Elasticsearch自身で前処理(データ整形)を行う仕組みをさします。enrich processorは Elasticsearch Version 7.5より導入されました。X-Packを有効にした Elasticsearchのみ実施することが可能です。
その利用用途のユースケースの例を以下に示します。
- Webサーバ と IPアドレス
- プロダクトID と プロダクト名称
- e-mailアドレス と 顧客の購買情報
- 郵便番号 と 顧客の居住地区
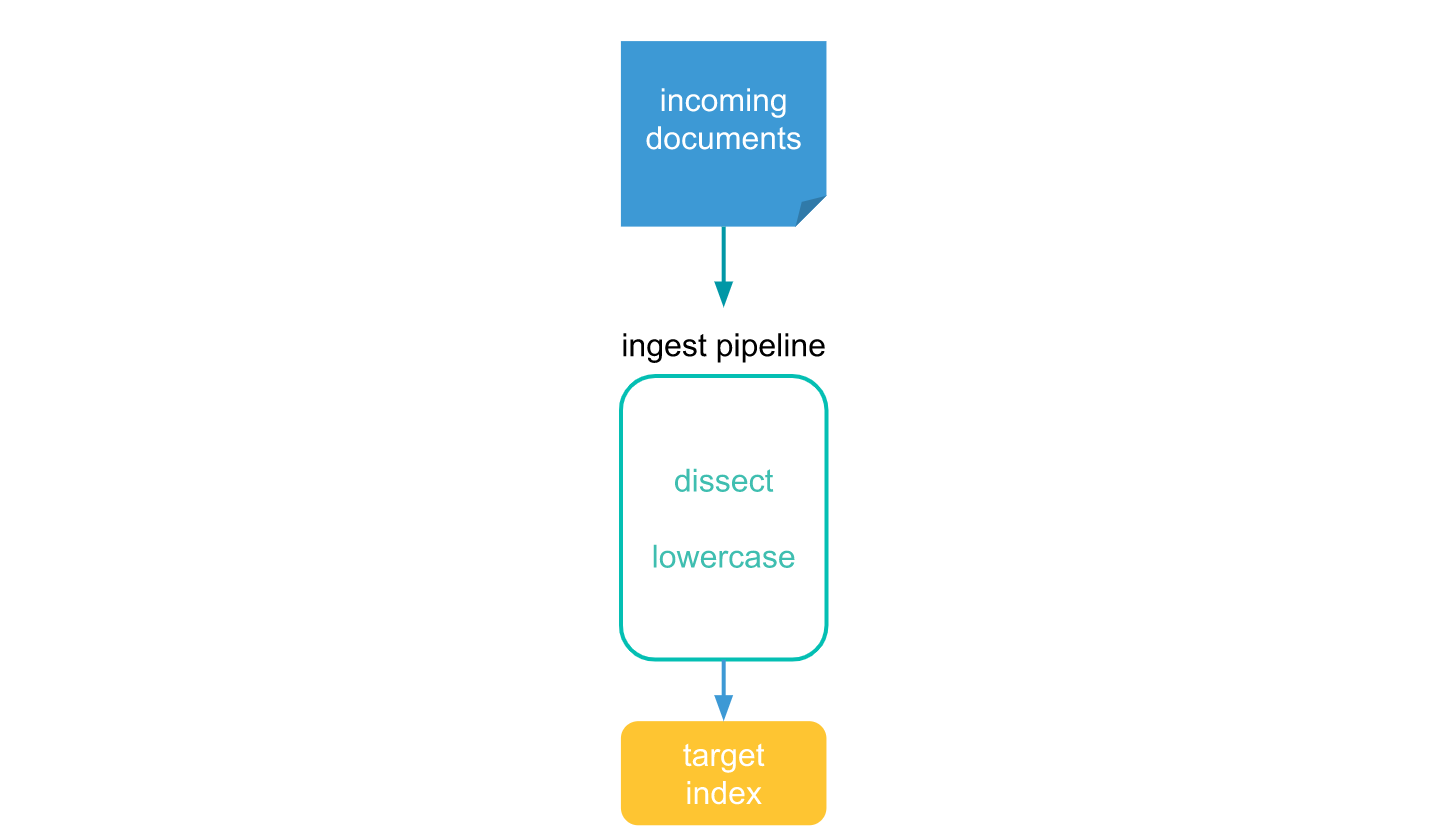
3. enrich processorはどのように動作するのか
以下の図に示す通り、enrich processorは実際には、Ingest pipelineを作成することで実装することができます。既存のindexの中のに対して情報を付け加えるという訳ではなく、これからindexingされるdocumentが対象となります。逆に言えば、indexingされる時点で結合されるためのIngest pipelineは生成されている必要があり、indexingされた後に紐付けは行うことができません。
4. enrich processorを実現するための構成要素

-
source index
- enrich dataを含むindex。通常のElasticsearchのindexと同様の生成方法で作成することができます。enrich dataは複数のsource indexから抽出することができます。また、単一のsource indexに対して複数のenrich policyを適応することも可能です。
-
enrich data
- source indexから抽出されるデータセット。
-
incoming document
- enrich dataが結合されるdocument。indexingされる前の状態をさす。
-
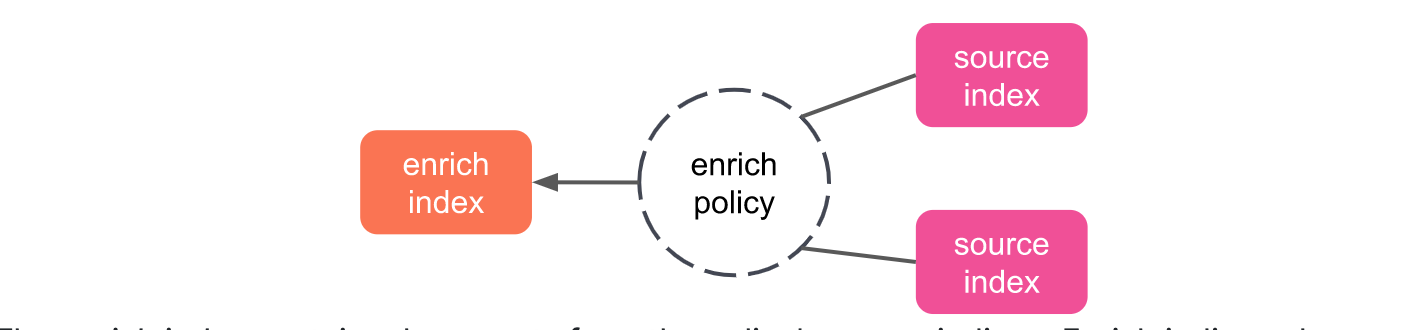
enrich policy
- enrich policyにしたがって、 enrich data(*1)をindexingするdocumentを付与します。
- enrich policyには以下の設定情報が含まれます。
- source index list: enrich dataを抽出するElasticsearchに既にindesingされているindexとなります。少なくとも1つ以上のindexが必要となります。
- policy type: incoming documentにenrich dataをmatch(結合)するかを決める識別子となります。
- match field: source indexのfieldです。incoming documentのfieldとmatchするfieldとなります。matchはString
- enrich field: source indexから抽出されるenrich data(fieldの集合)です。
enrich processorを使用する前に、enrich policyは必ず定義される必要があります。enrich policyが一度定義されると、source indexをもとにenrich indexと呼ばれるsystem indexが作成されます。enrich processorは、このenrich indexとincoming documentを結合する処理を行います。
- enrich index
- enrich policyと紐付くsystem indexの一種となります。system indexとは、 Elasticsearch内部処理するために利用するためのindexであり、通常のindex(visualizationでしようするindex)とは異なります。
enrich indexはsource indexからのenrich dataが含まれますが、enrich processorを実行するための(Elasticsearch内の内部処理を実施するためのプロパティも含まれます。)enrich indexそのものはRead-onlyであり、enrich dataおよびプロパティを意識する必要はありません。enrich policyを参照することでenrich processorの挙動を理解することができます。
5. enrich processorの設定手順
enrich processorを設定するためには、以下設定手順で行います。
5-1. enrich policyを作成する
enrich policyをAPIを用いて作成します。DevtoolなどでCUI操作で作成することができ、GUI操作で行うことができません。一度作成したenrich policyは、変更を行うことができません。更新はできませんが、削除はできませんので、enrich policyを作り直す必要があります。enrich policyは、jsonファイルで定義する必要があり、以下のフォーマットで作成されます。
{
"<enrich_policy_type>": {
"indices": ["..."],
"match_field": "...",
"enrich_fields": ["..."],
"query": "..."
}
}
}
enrich policyのパラメータについては、英語をそのまま記載した方が(個人的に理解しやすいので)そのまま掲載することとします。
-
enrich policy types
-
geo_match
- Matches enrich data to incoming documents based on a geographic location using a geo_shape query. For an example, see Example: Enrich your data based on geolocation.
-
match
- Matches enrich data to incoming documents based on a precise value, such as an email address or ID, using a term query. For an example, see Example: Enrich your data based on exact values.
-
-
indices
- (Required, String or array of strings) Source indices used to create the enrich index.
- If multiple indices are provided, they must share a common match_field, which the enrich processor can use to match incoming documents.
-
match_field
- (Required, string) Field in the source indices used to match incoming documents.
-
enrich_fields
- (Required, Array of strings) Fields to add to matching incoming documents. These fields must be present in the source indices.
-
query
- (Optional, string) Query type used to filter documents in the enrich index for matching. Valid value is match_all (default).
5-2. enrich policyを適応する。
enrich policyを Elasticsearchに以下APIコマンドで適応します。このAPIコマンドを実行することで、enrich indexと呼ばれる特殊なindexが生成されます。
PUT /_enrich/policy/my-policy/_execute
or
POST /_enrich/policy/<enrich-policy>/_execute
5-3. enrich processorをingest pipelineに加える
enrich processorを定義して、pipeline APIを用いてingest pipelineを作成します。enrich processorを定義する際は、少なくとも以下を定義する必要があります。
- 適応するenrich policy
- enrich indexとincoming documentを紐づけるfield情報。
- incoming documentに付与するfield(target field)。target fieldはenrich policy内のenrich fieldに含まれている必要があります。
- enrich document内の最大match数。デフォルトの値(1の場合)、enrich dataはjsonデータとして付与される。それ以外の場合は、matchしたenrich dataをリストで付け加えられます。
より具体的には、以下のようにingest pipelineを生成します。
PUT /_ingest/pipeline/<my_pipeline_name>
{
"description" : "Enriching user details to messages",
"processors" : [
{
"enrich" : {
"policy_name": <my_enrich_policy>,
"field" : "email",
"target_field": "...",
"max_matches": "..."
}
}
]
}
5-4. 実行する。
APIで実行する場合は、通常のpipelineと同様に以下のようなコマンドで実行するか、あるいはindex templateで適用するdefault pipelineとして定義します。Kibanaで設定する例を以下に示します。
- KibanaのDevToolで定義する例
PUT /<my_index_name>/_doc/<my_document_id>?pipeline=<my_pipeline_name>
{
"<my_key1>": "<my_value1>",
"<my_key2>": "<my_value2>",
"<my_key3>": "<my_value3>"
}
- KibanaのIndex Template
{
"index": {
"default_pipeline": "<my_pipeline_name>"
}
}
6. ハンズオン
やはり実際に触った方が感覚をつかめると思いますので、以下URLを参考にKibanaのDevtoolで操作を実感してみてください。
-
Ex 1
-
Ex2
7. enrich processorの注意事項
- Elastic社の公式の見解によると、enrich processorはリアルタイム処理には適さないと記載がある。enrich processor自体は頻繁な処理を追いきれない可能性がある。