1. 目的
LogStashの Input Plugin(File Module)、Filter Plugin(csv)、Output Plugin(elastic Module)を活用して、ローカルディレクトリに格納のcsvファイルをelasticsearchに格納する。
2. 設定方法
読み込むCSVファイルは以下とする。
20160117,001,Train,Akihabara,Tokyo,200
20160118,001,Taxi,Tokyo,Akihabara,730
20160118,002,Train,Oita,Akihabara,20000
File Input Pluginを参照して、各種項目を設定する
Normally, logging will add a newline to the end of each line written. By default, each event is assumed to be one line and a line is taken to be the text before a newline character. If you would like to join multiple log lines into one event, you’ll want to use the multiline codec. The plugin loops between discovering new files and processing each discovered file. Discovered files have a lifecycle, they start off in the "watched" or "ignored" state. Other states in the lifecycle are: "active", "closed" and "unwatched"
By default, a window of 4095 files is used to limit the number of file handles in use. The processing phase has a number of stages:
input{
file{
path => "/home/ec2-user/csvfile/keihi.csv"
start_position => "beginning"
tags => "CSV"
}
}
- pathは必須項目。絶対パスにてファイルを指定する。ワイルドカードによるファイル指定は可能。
path
edit
This is a required setting.
Value type is array
There is no default value for this setting.
The path(s) to the file(s) to use as an input. You can use filename patterns here, such as /var/log/.log*. If you use a pattern like /var/log/**/*.log, a recursive search of /var/log will be done for all *.log files. Paths must be absolute and cannot be relative.
- start_positionでファイルの読み込み位置を指定する。今回は初回読み込みかつ追記を予定していないので、beginningを選択した。
start_position
edit
Value can be any of: beginning, end
Default value is "end"
Choose where Logstash starts initially reading files: at the beginning or at the end. The default behavior treats files like live streams and thus starts at the end. If you have old data you want to import, set this to beginning.
- tagsでパイプライン処理に対してタグ付けすることができる。後の処理で活用できるらしい(例えば、outplugin時にIF文にてtagを認識し所定の宛先に送る等
tags
edit
Value type is array
There is no default value for this setting.
Add any number of arbitrary tags to your event.
csv filter plugin、mutate filter plugin、date filter pluginを参照して、Filter項目を設定する。
filter {
csv {
columns => ["date","user_id","transfer","source","destination","price"]
separator => ","
}
date {
match => [ "date", "YYYYMMdd" ]
}
mutate {
convert => { "price" => "integer"}
}
}
- columnsにて列名を指定する。デフォルトは、columnXととなっている。
columns
edit
Value type is array
Default value is []
Define a list of column names (in the order they appear in the CSV, as if it were a header line). If columns is not configured, or there are not enough columns specified, the default column names are "column1", "column2", etc. In the case that there are more columns in the data than specified in this column list, extra columns will be auto-numbered: (e.g. "user_defined_1", "user_defined_2", "column3", "column4", etc.)
- separatorにてcsv識別子を設定する。デフォルトは、「,」となっている。
separator
edit
Value type is string
Default value is ","
Define the column separator value. If this is not specified, the default is a comma ,. If you want to define a tabulation as a separator, you need to set the value to the actual tab character and not \t. Optional.
- mutatefilterのconnvertにて型名を明示的に指定する。何も設定しない場合はElasticsearch側のスキーマレスの指示に従う。
convert
edit
Value type is hash
There is no default value for this setting.
Convert a field’s value to a different type, like turning a string to an integer. If the field value is an array, all members will be converted. If the field is a hash no action will be taken.
outputpluginにて、elasticsearchの宛先を指定する。なお、Indexについてもこのタイミングで付与することができる。
詳細はelasticsearch output pluginを参照すること。
output{
elasticsearch{
hosts => "http://localhost:9200/"
index => "keihi"
}
}
index
edit
Value type is string
Default value is "logstash-%{+YYYY.MM.dd}"
上記設定を記載したconfファイルをetc/logstash配下のpipelines.ymlで指定したディレクトリ名に格納されるように配置する。下記の例では、/etc/logstash/conf.d/配下のconfファイルは全て読み込むように設定している。
# This file is where you define your pipelines. You can define multiple.
# For more information on multiple pipelines, see the documentation:
# https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
- pipeline.id: main
path.config: "/etc/logstash/conf.d/*.conf"
logstashを実行する。
systemctl start logstash
すると、指定したIndex(= keihi)でデータが蓄積されていく。
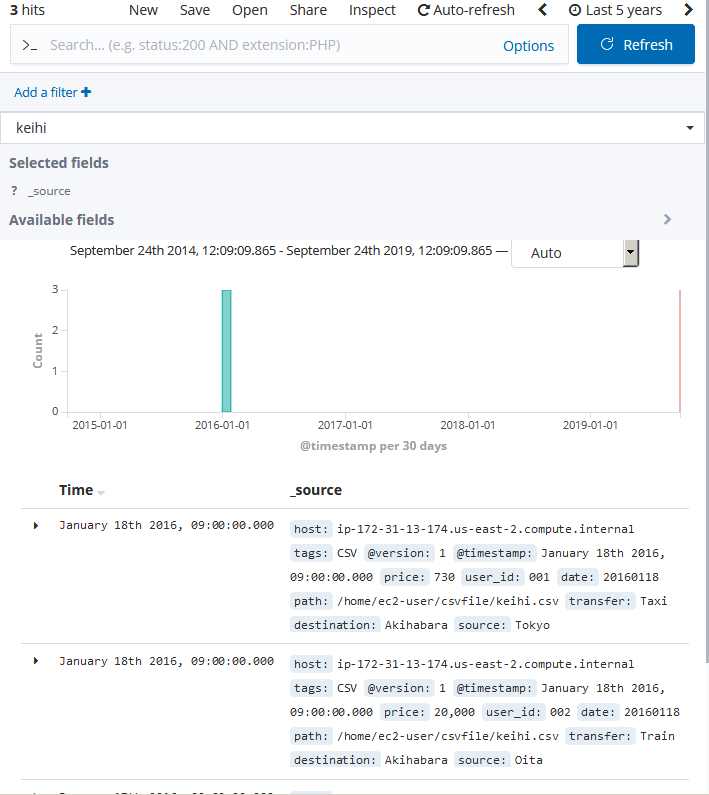
以上