1.目的
Kafkaは、ProducerとConsumerのAPIを利用することにより、Kafka Brokderに対して、Topicの生成と受信などの操作を行うことが可能です。ElatticStackのコンポーネントの1つであるLogstashには、これらAPIを実装したプラグインが存在します。
本投稿では、それらのプラグインをlogstash kafka producerとlogstash kafka consumerと呼ぶこととします。本投稿では、あるユースケースを実現するための基本設定と基本パラメータについて解説します。
2.基本設定
2-1.前提構成
基本設定では、下記構成(ユースケース)に対するLogstashのconfファイルの設定方法について説明します。
このユースケースでは、syslog clientから受信したsyslogデータを下記経路を通じて、最終的にKibanaにて可視化を行います。
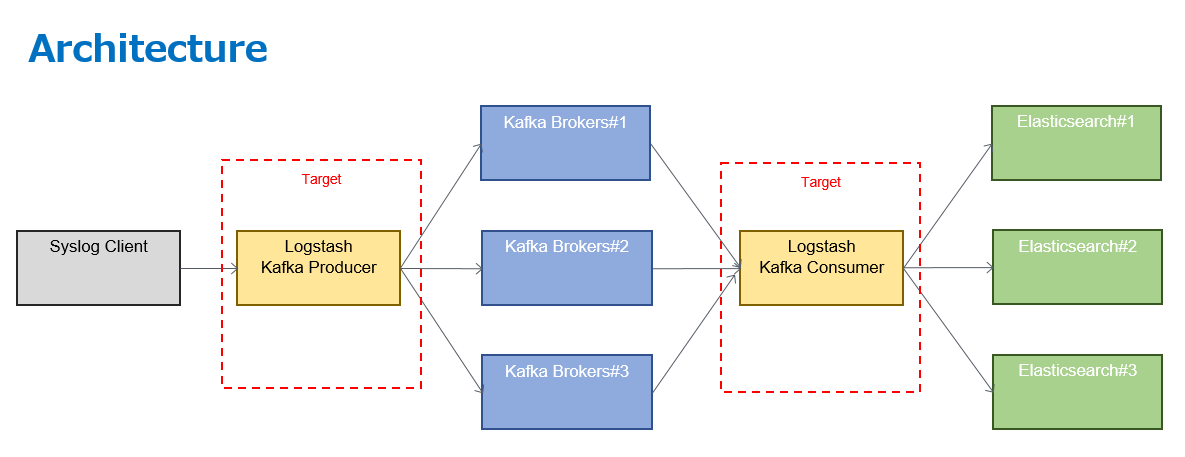
本投稿では、Logstashの設定に主眼を置いているため、太字の箇所(logstash kafka producer/logstash kafka consumer)の基本設定について解説し、その他コンポーネントについては解説しません。
2-2.logstash kafka producerの基本設定
logstash kafka producerの基本設定は以下の通りです。input pluginにはTCP/UDPプラグインを使用して、output pluginにはKafkaを利用しています。
### in Kafka producer
input {
#TCP input moduleにてport5005をlisten
tcp {
host => "0.0.0.0"
port => "50005"
type => "syslog"
}
#udp input moduleにてport5005をlisten
udp {
host => "0.0.0.0"
port => "50005"
type => "syslog"
}
}
output {
kafka {
#Kafka broker serverのIPアドレスを記載する。
bootstrap_servers => "broker1:9092,broker2:9092,broker3:9092"
topic_id => "syslog"
}
}
TCP/UDP portがListenしているがどうかは下記コマンドで確認することが可能です。
### in Kafka producer
ss -nltu | grep 50005
udp UNCONN 0 0 0.0.0.0:50005 0.0.0.0:*
tcp LISTEN 0 128 *:50005 *:*
TCP/UDP input pluginを使用しなくても、syslog pluginでも設定できます。その場合の設定はこちらです。
### in Kafka producer
input {
syslog {
#syslogの受信ポートを設定する。
port => 50006
}
}
output {
kafka {
#Kafka broker serverのIPアドレスを記載する。
bootstrap_servers => "broker1:9092,broker2:9092,broker3:9092"
topic_id => "syslog"
}
}
2-3.logstash kafka consumerの基本設定
Input plugin(logstash kafka consumer)の基本設定は以下の通りです。
input {
kafka {
#Kafka broker serverのIPアドレスを記載する。
bootstrap_servers => "broker1:9092,broker2:9092,broker3:9092"
#Consumerが取得するtopic名称を記載する。
topics => ["topic"]
}
}
output {
#elasticsearchのIPアドレスを記載する。
elasticsearch {
hosts => ["localhost:9200"]
}
}
2-4.動作確認
syslog clientにてloggerコマンドを入力すると、
# syslog client
logger default-log_777
kafka brokerにてtopicの一覧を確認すると、logstashで指定したtopicが生成されていることが確認できます。
# kafka broker
# kafka-topics --zookeeper broker1:2181,broker2:2181,broker3 --list
syslog
また、kibanaにてdashboard画面を確認すると、syslog clientにて送出したsyslog message(logger default-log_777)を受信していることも確認できます。
4.logstash kafka producerのパラメータ
4-1.kafka producerとは
- ProducerはメッセージをTopicに書き込むためのクライアントライブラリです。ユーザアプリケーションはProducerを使用して、Brokerクラスタ上に構成されたTopicの各Partitionにメッセージを書き込みます。
- Producerは定期的にいずれかのBrokerからメタデータを取得することで、各Brokerのホスト名、接続先ポート、各Topic PartitionのLeader Replicaの場所など把握します。Producerはこの情報を元に、どのメッセージをどのBrokerに送信するかを決定します。
4-2.logstash kafka producerとは
logstash kafka producerは、Kafka Client 2.1.0の仕様に準じたプラグインとなっています。本プラグインでは、Kafkaがサポートしているなかで、以下セキュリティ通信をサポートしています。
- SSL (requires plugin version 3.0.0 or later)
- Kerberos SASL (requires plugin version 5.1.0 or later)
logstash kafka producerのパラメータ設定について、さらに活用するために本節では主要パラメータについて解説します。セキュリティに関するパラメータについては、本記事の対象外とします。
デフォルトの設定では、セキュリティ通信は無効となっているが、必要に応じて設定をONにすることが可能です。本記事ではセキュリティ設定について触れません。詳細は、kafka output pluginを参照してください。
logstash kafka producerにて、デフォルトで必須で設定しなければならないパラメータは、topic_idのみです。
デフォルトのコーデックはplainとなっておるが、ユーザー自身で変更することも可能であります。
例えば、イベント内のすべてのコンテンツをjson形式で送信したい場合は、outputのコンフィグレーションを
下記の通り設定する必要することで実現が可能となります。
output {
kafka {
codec => json
topic_id => "mytopic"
}
}
4-3.主要パラメータ
logstash kafka producerの主要パラメータについて下記で解説します。
また、構成図とのマッピングを下記に載せます(図の関係上、すべてのパラメータを載せることはできなかったので主観で重要そうなパラメータをpick upした)。
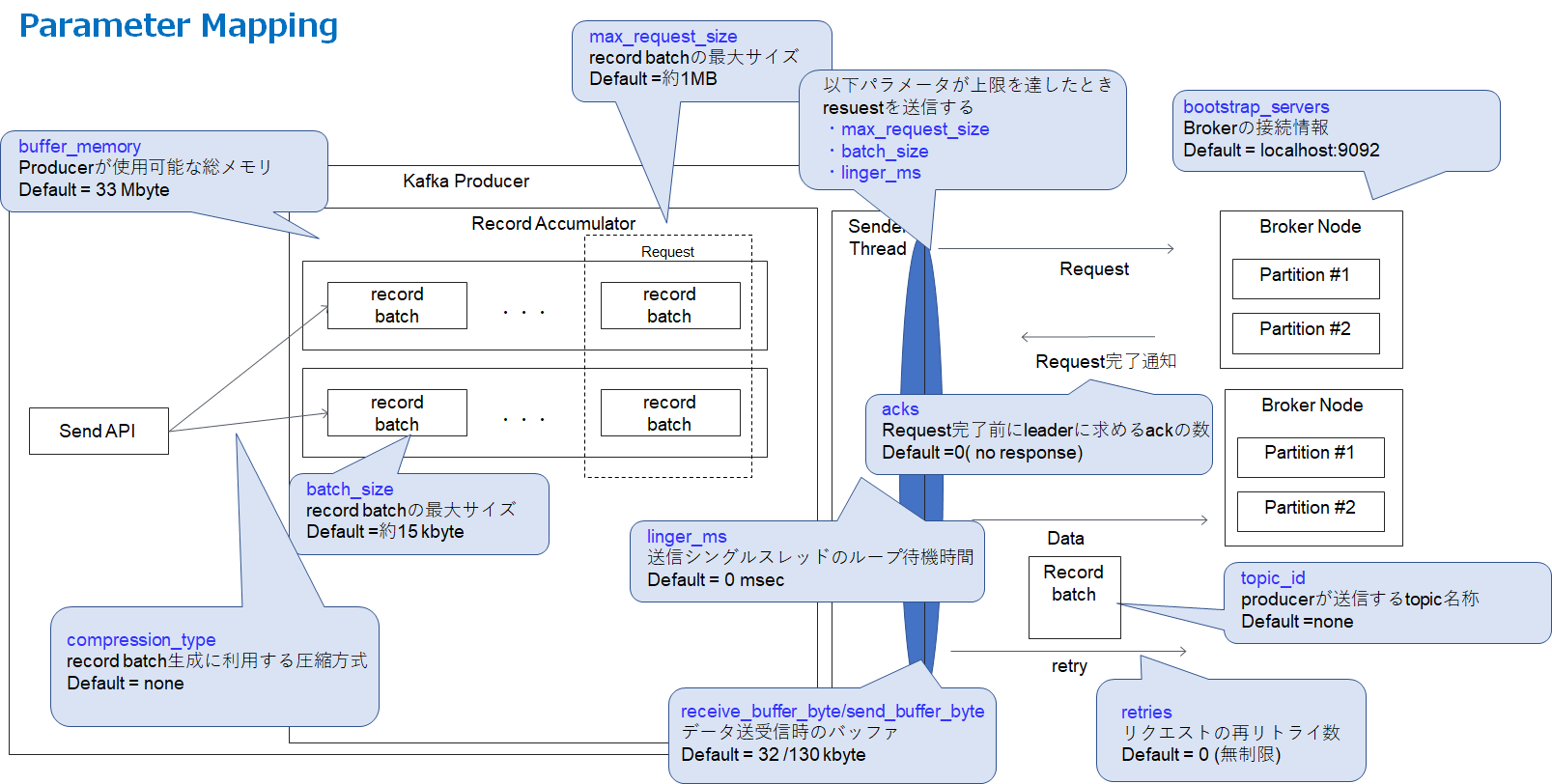
- bootstrap_servers
- topicを送信するkafka brokderの接続情報(IPアドレス等)を記載する。producerは、メタデータ(topic,partition,replica)の情報を得るために使用する。producerは受信したメタデータをもとに、kafka brokderに対して実データを送信する。フォーマットの記載の仕方は、host1:port1,host2:port2である。
- client_id
- client idは、kafka brokerへとrequestを作成する際に通知される。request内に含めることでrequest sourceをトラッキングできることがメリットである(IP/Port以外のトラッキング情報として)。デフォルトでは設定する必要はない。
- security_protocol
- 各kafka producer~kafka broker間で使用するセキュリティプロトコルである。PLAINTEXT, SSL, SASL_PLAINTEXTの選択肢から選択することができる。デフォルト値は、PLAINTEXTである。
- topic_id
- producerが送信するtopic名称
- value_serializer
- Messageに使用するSerializerクラス。メッセージをエンコードするクラスを指定する。
- buffer_memory
- producer自身が使用可能な自身の最大メモリサイズ。recordをバッファする為に使用することができ、kafka brokerへの送信前に蓄積するための領域となる。デフォルト値は33,354,432 byte(= 33 Mbyte)となる。
- acks
- ProducerがRequest完了前にleaderに求めるackの数。ackが「0」の場合は、すべてのbroker serverからのackを受け取らずにrequestが完了したと判断する。 ackが「1」の場合は、leaderが自身のlogに書き込みが完了したが、すべてのfollowerからのackを返信されていない状態を指す。ackが「all」の場合は、すべてのin-sysnc replicaからレコードを完了した旨のackを受信した状態でrequestが完了したと判断する。
- batch_size
- producerが送出するrecord batchの最大サイズ。このパラメータは、Kafka producerとKafka Serverの両方の性能値に影響を大きく与える。デフォルトのbatch sizeは、16384 byteとなる。この値がkafka brokerが許容する受信サイズを超えることができない。
- compression_type
- producerがrecord batchを送信する際に利用する圧縮方式。選定する圧縮方式に応じて、record batchのoverheadの値が変化する。圧縮方式としては、none、gzip、snappy、lz4を選択することができる。
- key_serializer
- デフォルト値は"org.apache.kafka.common.serialization.StringSerializer"となる。producerがmessageのkey値をシリアライズするためのSerializer Classを指定する。
- linger_ms
- 送信待機時間。送信シングルスレッドのループ待機時間。prodecer側で指定した最大のRequestサイズ(max_request_size)に達しなくても、この時間が経過したら送信される。
- max_request_size
- request最大サイズ。producerが送信するrecord batchの最大サイズ。この上限値に達したとき、producerはrequestを送出する。デフォルト値は、1.048,576 byte(=約1MB)である。
- metadata_fetch_timeout_ms
- initial meta data requestのさいに、topicのメタデータをfetchするためのタイムアウト値。デフォルトは60,000 msec(=60 sec)である。
- metadata_max_age_ms
- メタデータを強制リフレッシュするための最大待ち時間。デフォルト値は300,000 msec(= 5 min)である。
- receive_buffer_bytes
- データ読み込み時に指定するTCP receive bufferの最大サイズ。デフォルト値は、32,768 byte(=約32 kbyte)である。
- reconnect_backoff_ms
- Connection failが発生した際に、Kafka brokerにreconnectを実施するための待ち時間。デフォルト値は、10msec。
- request_timeout_ms
- このパラメータは、kafka producerがrequestのレスポンスを待つために使用する最大待ち時間をコントロールする。もしレスポンスがこのタイムアウト内に到着しない場合は、kafka producerは、必要に応じてrequestを再送信する。
- retries
- デフォルトのリトライの挙動は、成功するまでリトライをし続けるというものである。リトライ回数はユーザー自身で設定することが可能であるが、送信データの損失を防ぐために、このパラメータを調整することは推奨されない。もし、このリトライ回数を設定した場合(0以上の整数値を設定する)、kafka producerはその設定値しかリトライを実施しないという挙動となる。 0より小さい値を設定した場合はコンフィグレーションエラーとなる。
- retry_backoff_ms
- topic partitionへのrequestが失敗した場合にretryし続ける最大待ち時間である。デフォルト値は100であり、最大100回リトライを実施することとなる。
- send_buffer_bytes
- TCPデータ送信する際に使用する最大バッファサイズ。
5.logstash kafka producerのパラメータ
5-1.kafka consumerとは
- ConsumerはメッセージをTopicから読み出すためのクライアントライブラリです。ユーザアプリケーションはConsumerを使用して、Brokerクラスタ上に構成されたTopicの各Partitionからメッセージを読み出します。
- ConsumerもProducerと同様に、定期的にいずれかのBrokerからメタデータを取得することで、各Brokerのホスト名、接続先ポート、各Topic PartitionのLeader Replicaの場所など把握します。Consumerはこの情報を元に、どのBrokerからRecordを取得するのか決定します。
- ConsumerがRecordをどこまで読みだしたのかを示すOffsetはConsumer側で管理し、Broker側では排他制御を行いません。そのためConsumer数が増加しても、Broker側の負担は少なく済みます。Consumerはアプリケーションの再起動時に、自身のOffsetから再開できるようOffsetを永続化する必要があります。そのため、Consumerは自身のOffsetをKafka上のOffset用Topicや、任意のデータストアに保存します。
- ユーザアプリケーションは、1つ以上のConsumerでConsumer Groupを構成することで、1TopicのデータをGroup内のConsumerで分散読み出しできます。このようにデータを分散読み出しできるため、KafkaはHadoop/Spark/Stormなどの並列分散処理フレームワークと相性が良いです。また、Topicのデータは読み出されてもすぐには削除されないため、同じTopicのデータを複数のConsumer Groupから読み出すことができます。
5-2.logstash kafka consumerとは
logstash kafka consumerは、group management(group idを用いた論理的なグループ管理)を取り扱うことができる。異なる物理マシン上のLogstashインスタンスにて、同じgroup_idを付与することでデータ受信速度を向上させることができます。デフォルト設定では、Logstashインスタンスは1グループにしか所属していません。各コンフィグレーション上のgroup_idを同一の値に設定する必要があります。
Topicに含まれるmessageは、同一のgroup_idをもつ全てのLogstashインスタンスに送信されます。
以下に含まれるKafka brokerからのメタデータは、@metadata fieldに含まれる。メタデータは、decorate_eventオプションが「true」に設定された場合のみ送信されます。デフォルトでは、decorate_eventオプションは、falseとなっています。
- [@metadata][kafka][topic]: Kafkatトピック名称
- [@metadata][kafka][consumer_group]: Consumerグループ
- [@metadata][kafka][partition]: messageが含まれていたpartition情報
- [@metadata][kafka][offset]: messageのrecord offset
- [@metadata][kafka][key]: record keyの情報
- [@metadata][kafka][timestamp]: Recordのタイムスタンプ情報。ただし、この情報は、Kafka brokerの設定に依存するので注意が必要です。デフォルトでは、recordが生成されたタイミングのタイムスタンプを意味します。kafka brokerのより詳細な仕様を理解する為には、log.message.timestamp.typeのパラメータ仕様を確認する必要があります。
5-3.主要パラメータ(編集中)
logstash kafka consumerの主要パラメータについて下記で解説します。
また、構成図とのマッピングを下記に載せます(図の関係上、すべてのパラメータを載せることはできなかったので主観で重要そうなパラメータをpick upしました)。
-
auto_commit_interval_ms
ConsumerがもつoffsetがKafkaにコミットする周期間隔。デフォルト値は、5,000 msec。 -
auto_offset_reset
ConsumerがFetchリクエストを出した場合に、initial offsetがなかった場合、あるいはoffsetが範囲外だった場合に、Consumerがもつoffset情報をどのように設定し直すかを、このパラメータで決定することができる。- earliest: earliest offsetに自動的にリセットする。
- latest: latest offsetに自動的にリセットする。
- none: consumerグループ内に以前のOffsetが無い場合、exception(例外通知)をconsumerに送付する。
- anything else: グループ内に問い合わせを問い合わせず、exception(例外通知)consumerに送付する。
-
bootstrap_servers
Kafka brokerクラスタに対しての初回接続の際に使用されるKafkaインスタンスのリスト。複数のKafka borkerを指定する場合は、「host1:port1,host2:port2」の形式で記載します。すべてのクラスタメンバーシップを検知するためのInitial Connectionのみで使用されるため、この値は必ずしもすべてのKafka brokerの値を入力する必要はないです。Initial Connectionが完了したのち、すべてのKafka brokderと通信することが可能です。しかし、念のため(単一のKafka brokderがDownしているケースを考慮して)複数のKafka brokderを記載したほうが耐障害性を考慮すると無難な選択肢となります。 -
check_crcs
record内のCRC32を自動的にチェックする機能である。このチェック機能はオーバーヘッドが存在するため、パフォーマンスを最優先する場合は機能をOFFすることを推奨する。 -
client_id
このパラメータを設定した場合、requestを作成するタイミングでKafka serverに対して、client_idをKafka brokerに通知されます。client_idを設定することで、ip/port情報以外の情報でトラッキングすることができる。 -
connections_max_idle_ms
このパラメータで指定した時間後、idleコネクションを閉じます。 -
consumer_threads
デフォルト値は1である。完全なバランスを保つためには、この値はKafka partitionの数と理想的な設定である。 -
decorate_events
デフォルトは、falseである。この設定をtrueにすることで、以下のKafkaのメタデータをlogstashのイベント内に含めることができる。 -
enable_auto_commit
デフォルト値はtrueである。このパラメータをtrueに設定すると、kafka brokerに対して定期的にコミットを行う。このコミットのは、プロセス失敗が発生した場合に発生する。 -
exclude_internal_topics
internal topic(offsetなど)を取り除くかどうかを設定する。 -
fetch_max_bytes
fetchリクエストで取得可能なデータ最大量。デフォルト値は、52,428,800(50 MB) -
fetch_max_wait_ms
fetch_min_byteによって設定した条件を満足しないデータが存在しない場合、fetchリクエストを応答する前にkafka brokerがブロックする。そのブロックを行うまでの最大時間。デフォルトでは、500msec(=5 sec)である。 -
fetch_min_bytes
consumerからのfetch requestに対してkafka brokerが応答するための最小データ容量。 -
group_id
デフォルト値は、「logstash」である。consumerが所属するグループ識別子である。トピック内のMessageは同一group_idのすべてのlogstashインスタンスに通知される。 -
heartbeat_interval_ms
同一グループ内のconsumerに適用されるハートビート。ハートビートはconsumerのセッションの正常動作性を確認することに使用される。また、新しいconsumerがjoinしたりleaveした場合のリバランシングに使用される。この値は、session_timeout_msより必ず小さく設定する必要がある。ただし、session_time_outの値の3分の1より大きくするのを推奨するので注意が必要となる。デフォルト値は、3,000
msec (= 3 sec)である。 -
key_deserializer_class
デフォルト値は、"org.apache.kafka.common.serialization.StringDeserializer"である。record keyのシリアル化をデコードするさいに使用されるJavaクラスである。 -
max_partition_fetch_bytes
pertitionごとの最大フェッチバイト数。 -
max_poll_interval_ms
consumerグループ管理をおこなうときにpoll起動間の最大待ち時間。 -
max_poll_records
1処理で取得可能な最大record数。 -
metadata_max_age_ms
kafka brokerのメタデータを強制リフレッシュする最大待ち時間。 -
partition_assignment_strategy
デフォルト値は、「org.apache.kafka.clients.consumer.RangeAssignor」である。kafka consumerとpartitonの配布のために使用される。 -
poll_timeout_ms
topicから新しいメッセージを受信するための最大待ち時間。この時間間隔で指定topicからデータを受信する。 -
receive_buffer_bytes
データ受信時に使用するTCP受信バッファ。 -
reconnect_backoff_ms
kafka brokerに李コネクトするための最大待ち時間。 -
request_timeout_ms
requestのタイムアウト値。kafka clientが投げたrequestのレスポンスの待ち時間。 -
retry_backoff_ms
fetchリクエストが失敗したときにtopic partitionに他しいてトライするまでの待ち時間。 -
security_protocol
利用するセキュリティプロトコル。PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSLのいづれかを使用する。 -
send_buffer_bytes
データ送信時のTCPバッファサイズ。 -
session_timeout_ms
consumerがdead状態と認識してリバランシングの操作を実施するためのトリガー値である。 -
topics
定期購読するtopicsのリストである。デフォルト値は、["logstash"]である。 -
topics_pattern
定期購読するtopicのパターンを記載します。この値を設定すると、topicsの値が無視されるので注意が必要である。 -
value_deserializer_class
デフォルト値は、"org.apache.kafka.common.serialization.StringDeserializer"である。recordのvalueをデコードする際に資料されるJavaクラス。
4.Kafkaの基礎概念
上記パラメータを理解するための、Kafkaの基礎概念を下記に示す。(気が向いたら編集予定)
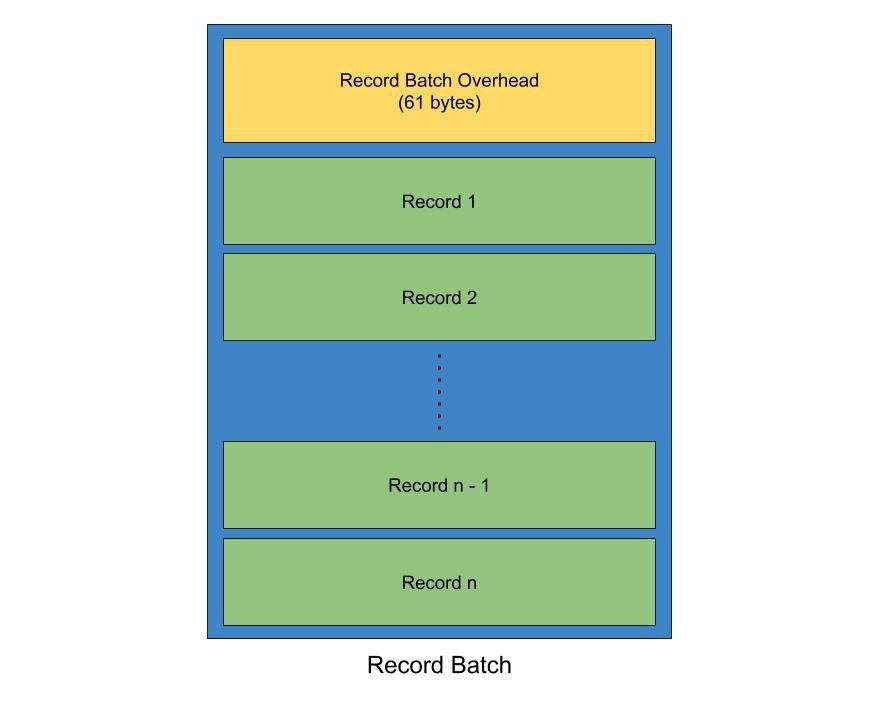
4-1.Record batch
- Record: messageの最小単位。keyとvalueのペアで構成される。
- Record batch: recordの集合。producerがtopic partitionに送信する際は、record batchの単位で送信される。それぞれのreord batchは複数のrecordで構成される。record batchはrecordに加えて、後述されるoverheadも含まれる。
- Record batch overhead:messageのバージョンによってoverheadの大きさが変化する。producer側の設定では、overheadのサイズは3つの方法により、増減させることとが可能である。linger time、compression、スキーマ定義(valueとkey)である。