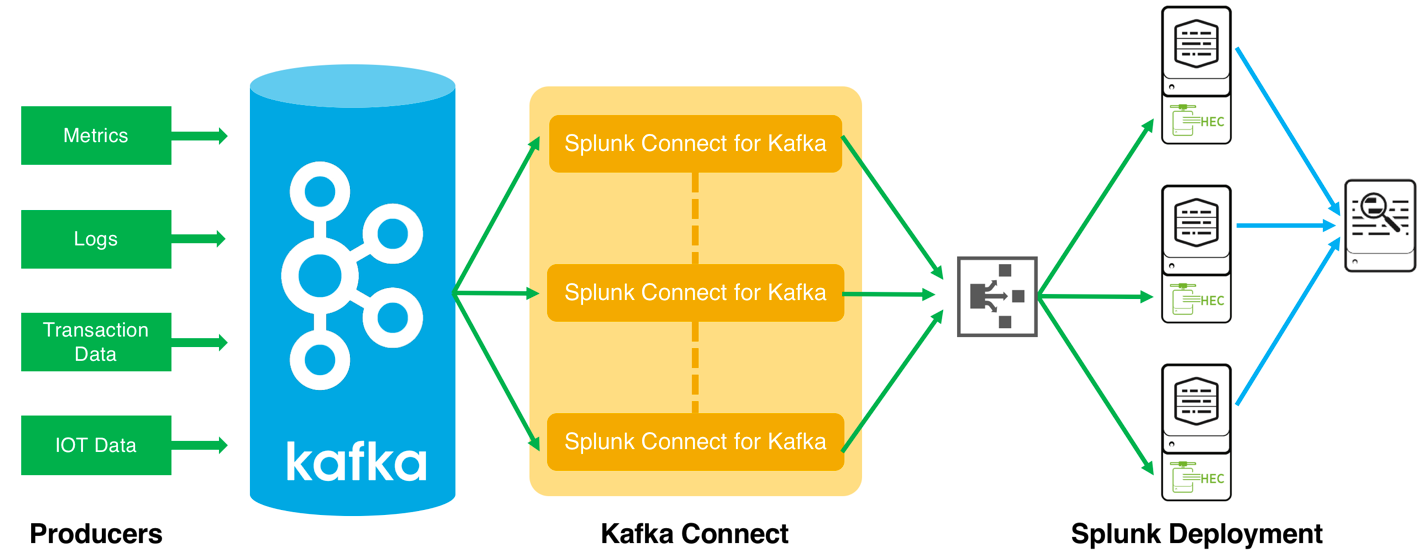
Kafka Connect
Kafka Connectとは、Apache Kafka に含まれるフレームワークであり、Kafka と他システムとのデータ連携に使うことができます。Kafka にデータをいれたり、Kafka からデータを出力したりスケーラブルなアーキテクチャで複数サーバでクラスタを組むことができます。Kafka と Kafka Connect が接続する部分を Connector と呼び、Producer 側の Connector は SourceConsumer 側の Connector は Sinkと呼びます。Splunk Connect for Kafkaとは、Kafka Connectのプラグインを拡張して、Splunkに対して、データを送信できるようにしたものです。
Splunk Connect for Kafka
Splunk Connect for Kafkaは、sink Connectorであり、このアプリケーションを使用すると、KafkaのTopic情報をSplunk HTTP Event Collectorにて購読することができます。Splunk PlatformにEventとしてIndexさえすれば、他のSplunk内に含まれるデータ含めた複合的な分析を行うことができます。
Splunk Connect for Kafkaは、Splunk Baseからダウンロードすることができます。
| Item | Information |
|---|---|
| Version | 1.1.1 |
| Vendor Products | Kafka Connect |
| Visible in Splunk Web | No. This product does not contain any views. |
Plan your deployment
以下の2つのデプロイメントオプションが選択です。Splunk Connect for Kafkaは、コンテナ、仮想マシン、物理マシンで動作するため、動作環境の選択肢は多いですが、既存のKafak Connect Clusterと同期させることはお勧めしません。
- Splunk Connect for Kafka in a dedicated Kafka Connect Cluster (best practice).
- Splunk Connect for Kafka in an existing Kafka Connect Cluster.
System requirements
Splunk Connect for Kafkaのシステム要件は下記のとおりである。HTTP Event Collector tokenの設定を忘れないように留意する。
- A Kafka Connect environment running Kafka version 1.0.0 or later.
- Java 8 or later.
- Splunk platform environment of version 6.5 or later.
- Configured and valid HTTP Event Collector (HEC) tokens.
Architecture requirements
Splunk Connect for Kafkaは、2つのタイプのシステムアーキテクチャをサポートしています。 一つ目は、Splunkプラットフォームに直接データを送信する方式です。2つ目は、Heavy Forwarderを介する方式です。それぞれのデータフローの流れを示すと以下のようになります。
- A Kafka Connect Cluster-> Splunk Indexer Cluster (HEC)
- A Kafka Connect Cluster -> Heavy Forwarders (HEC) -> Splunk Indexer Cluster
Sizing guidelines
Splunk側の事前設定
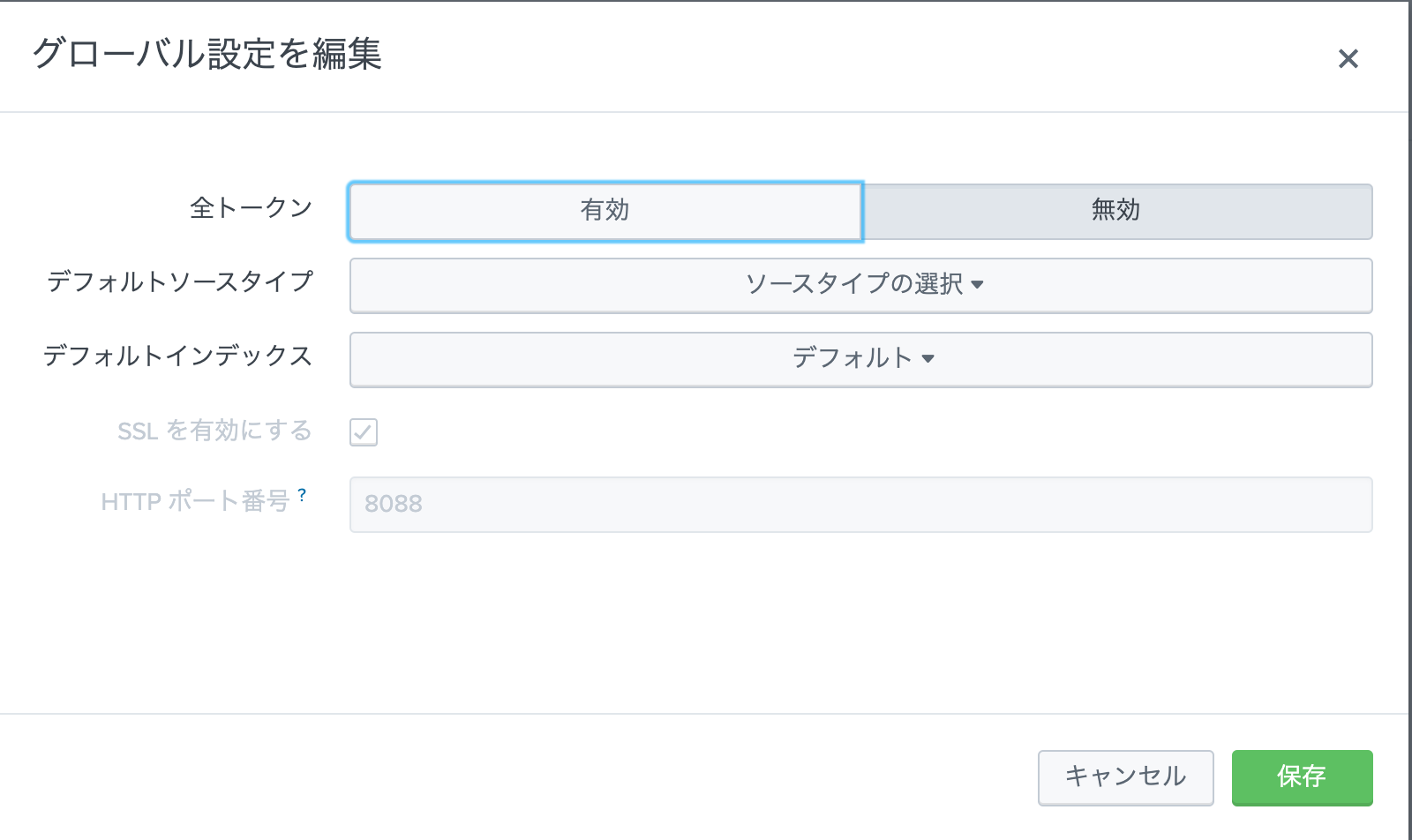
Splunk HEC でデータを受信するように設定する必要があります。Splunk Web にアクセスし、[Settings] メニューから [Data inputs] を選択して、[HTTP Event Collector] を選択します。[Global Settings] を選択して、[All tokens] が [enabled] になっていることを確認してから、[保存] を選択します。
次に、[New Token] を選択して、新しい HEC エンドポイントとトークンを作成します。
事前に決めた ACK ありか ACK なしかに応じて、[Enable indexer acknowledgment] を設定します。ACK ありの場合はこのチェックボックスを選択し、ACK なしの場合は選択を解除します。
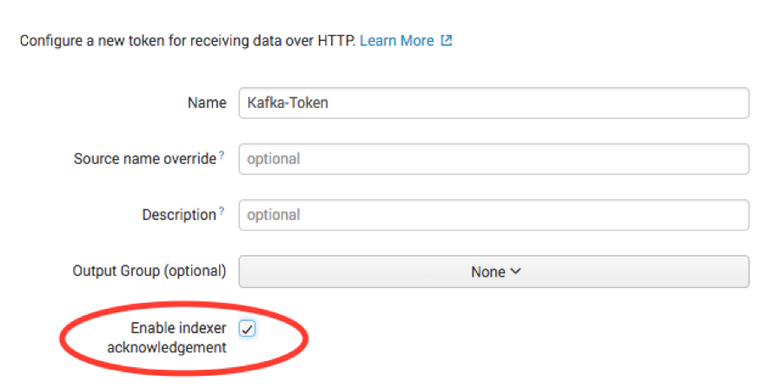
アクセストークンが発行されるので、メモします。
Example Access Token) 60220e79-a5df-491a-9403-8bc825fae3a3
Install to Kafka Connect for Splunk from Splunk Base
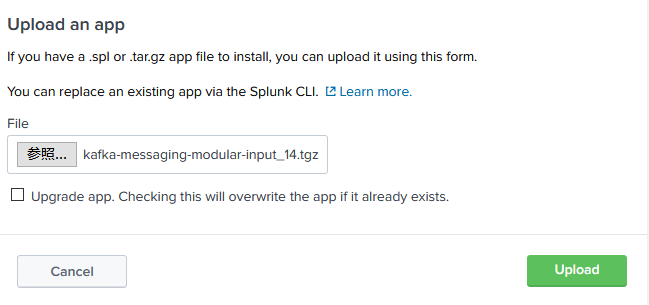
Splunk Baseから、Kafka Connectをインストールするためのファイルをダウンロードする。次にダウンロードしたファイルをアップロードする。
XXXXXXXXXXX
Start your Kafka Cluster and confirm it is running.
curl http://localhost:8083
{"version":"5.3.2-ccs","commit":"7d63e5707dee50f3","kafka_cluster_id":"vr_uG6_ZQk6HxWiwQeqOVg"}