はじめに
ELANのInterlinearization Modeを使わないといけない事情があったので、グロス付けの自動化を試してみた。MacではToolboxを使うことができないが、その代わりにはなるんじゃないか?という感じだった。
以下のような手順で行う。
- ファイルとTierを設定する
- ELANで句 (もしくは適当な発話単位) ごとのセグメンテーションを行う
- 「注釈層の自動分割」を行い、句を形態素単位へセグメンテーションする
- レキシコンを用意する
- 2で用意したセグメンテーションと3で用意したレキシコン情報をもとにグロスづけを行う
この記事では以上のステップに沿ってInterlinearization modeの使い方をまとめる (本記事の内容はほとんど公式マニュアルに載っているけど、Interlinearization Modeに集中したものがないのと、日本語版がないので)。
Step 0: ファイルと言語タイプとtierの準備#
まず、音声(動画)ファイルを読み込んで.eafファイルを作る。
次に、以下のような4つの言語タイプとそれに対応するtierを作る。話者が複数いるならその分だけtierを作る。話者が複数いる場合、まず一人分のtierを全て作ってからそれをコピーすればよい:
- text
- ステレオタイプはNone。上位注釈層はなし。句を入力するTier
- translation
- ステレオタイプはSymbolic Association。上位注釈層はtextにする。テキストの訳を入力する。
- morpheme
- ステレオタイプはSymbolic Subdivision。上位注釈層はtextにする。形態素を入力する。
- gloss
- ステレオタイプはSymbolic Association。上位注釈層はmorphemeにする。グロスを入力する。
(言語タイプとかステレオタイプとかって何?という人は、私が主催して兵庫県立大学の木本幸憲さんに講演いただいた「ELAN講習会」をご覧ください: https://www.youtube.com/watch?v=a4SqxhLGn5Q)
その他、言語や談話の特性に応じて言語タイプとtierを適宜作る。例えば、備考を書き込むためのnoteというtierがあってもいいかもしれない。また、複数の話者がいる場合、tierの名前の最初か最後に話者の名前を書いておくとよい。例えば、"text" tierなら"text@K"のような感じ。
この作業が終わった時点で、各tierの特性は以下の画像のようになっているはず (話者、注釈者、既定言語は設定しなくても良い)。元からあったdefault-ltという言語タイプとdefaultというtierは邪魔なので消しておく。

Step 1: 手動で句ごとのセグメンテーションを行う
適当な発話単位でセグメンテーションを行い、"text" tierと"translation" tierに文字を入力していく。ここで注意することとは以下の2点
- この時点でのテキストの入力はある程度基底形での表示(レキシコンに登録する形)に近づけたほうがよく
- 形態素境界はスペース、ハイフン、イコールサインなどで明示したほうがよい。
1.の理由は、ステップ4で行う自動グロスづけの際に、レキシコンへの登録形と入力された形が異なっていると、手動で語彙素を選ぶ必要があるためである。2.の理由は、次のステップで行う「注釈層の自動分割」で形態素ごとの分割を行う際に、その境界をわかりやすくするためである。
したがって、例えば日本語であれば、「吾輩は猫である」と入力するよりも、「wagahai=wa neko de ar-ru」と入力したほうがよい。もしどうしても基底形と異なる表示を行いたいという場合 (例えば、日本語の漢字仮名交じり文を書いておきたいという場合)は、"text" tierとは別のtierを作ったほうがよいかもしれない。
この作業が終わった時点で下の画像のようになっていればよい (画像ではわかりやすいよう"orthography" tierを用意した)。

Step 2: 形態素への自動分割を行う
このステップでは、Step 1で入力した"text" tierを形態素ごとに分割し、"morpheme" tierに出力する。
メニューバーの「注釈層」>「注釈層内の文字列分割」を選択する。「元の注釈層」にはtext、「分割先の注釈層」にはmorphemeを指定する。「分割する区切り文字」の選択は、形態素境界にスペースキーだけを使っているなら「初期設定」にする。ハイフンなども使っているなら、区切り文字を「カスタム」欄で指定する。
「開始」を選択すると、下の画像のように、"morpheme tier"に形態素ごとのセグメンテーションが挿入される。
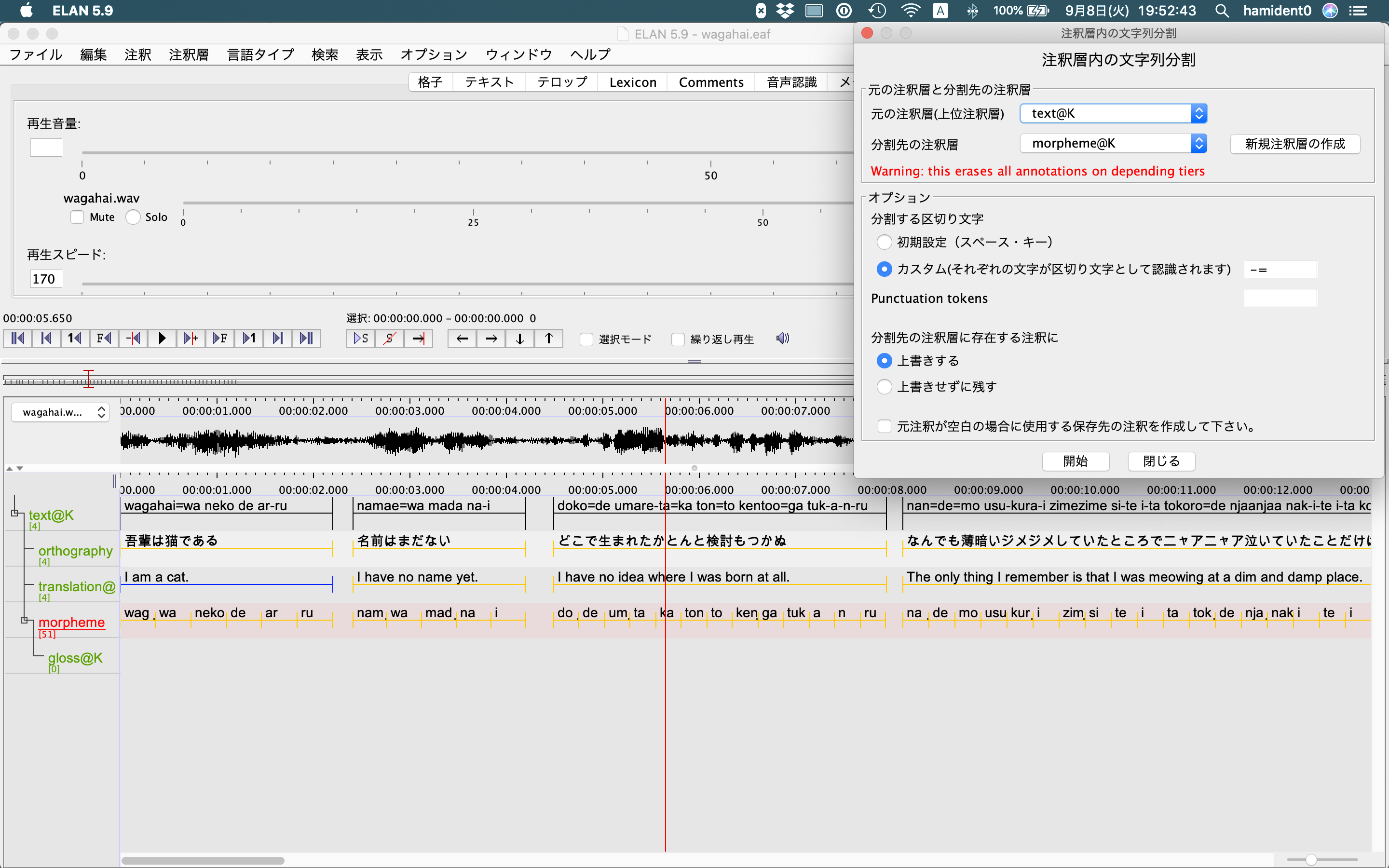
(Interlinearization Modeで辞書情報を用いて形態素への分割を行うこともできるが、日本語ではあまり現実的ではないので、ここでは扱わない)
Step 3: レキシコンを用意する
このステップではグロス付けに使うレキシコン (辞書データ) を用意する。
レキシコンは以下の2通りの方法で準備できる:
- ELANから直接辞書情報を入力する
- 外部で用意したデータ (.txt、.xml、.lift などの形式) を読み込む
1.は、まだ手元に辞書データがない場合やELANでのアノテーションに特化した辞書を新規に作りたい場合に使える。
2.は、すでに別の方法で語彙データを貯めている場合に使える。
ここでは両方の方法を解説する。
Step3-(1): ELANから直接語彙情報を入力する
メニューバーの「オプション」>「Interlinearization Mode」を選択する。するとモードが変更され、注釈画面を離れる。左側のカラムの「Lexicon Actions▼」から、「Create New Lexicon...」を選択し、必要な情報を入力する。すると空のレキシコンが作られる。
ここから語彙素を追加していく。左下の「追加」ボタンを押すと語彙素の情報を入力するウィンドウが現れるので、以下のようにする。
- Lexical Unit
- 形態素境界のマークも含めた形を入力する (自立語の場合、語境界は不要)。
- Morph Type
- 形態素のタイプ (語幹とか接語とか)を入力する。
- Citation
- 見出し形を入力する。
- Variant
- 異形態を入力する。ここでは異形態は1つしか入力できないが、後で2つ以上入力できる。
- Gram. Category
- 品詞を入力する。
- Gloss
- グロスとして表示する形を入力する。ここでは品詞とグロス (これらをまとめてsenseと呼ぶ) を1つしか入力できないが、後で2つ以上入力できる。例えば、"smoke"という1つのLexical Unitに対し、(1)v. 喫煙する (2)n. 煙 という2つのsenseを入力できる。
情報を入力し終わったら「適用」を押して語彙素を登録する。
既に入力した語彙素を右クリック > 「編集」と選択すると、より細かい情報や2通り以上の異形態・senseを入力できる。フィールドを増やすためには右端の+ボタンを押す。
以上の手順を繰り返して必要な分の語彙素を入力し、終了。
Step3-(2): 既存の語彙データを読み込む
元となるデータとして読み込める形式は様々だが、一番扱いやすいであろうToolbox dictionary形式の.txtファイルを用いる方法を解説する。元ファイル > Toolbox dictionary > ELANに読み込み という手順で行う。
語彙データはタブ区切りのテキストファイルや.xlsxファイルとして保管している人が多いと思うので、まずそのデータをToolbox dictionary形式の.txtファイルに変換する。Toolbox dictionaryのファイルは下図のような形である。

まず、元データからタブ区切りテキストを経由してToolbox dictionary形式への変換を行う。Excelにデータを保存している場合、セルをコピーしてテキストエディタに貼り付ける。すると、タブ区切りのテキストになる。タブ区切りテキストからToolbox dictionaryへの変換は、下図のように正規表現による置換を用いて行う (正規表現ってなに?という人は私が行った正規表現講習会をごらんください: https://youtu.be/2U6Xtud-8po )。
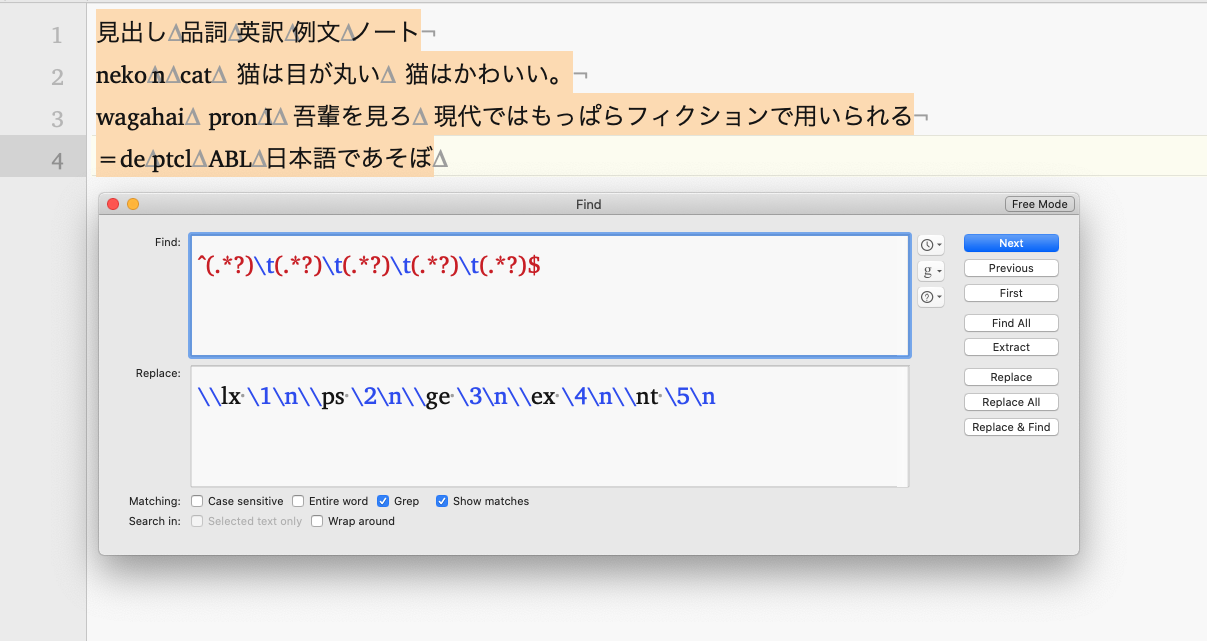
元データの形式は人によってそれぞれだと思うので、この正規表現はあくまで一例である。最終的には、\lxから始まる行に見出し語、\psから始まる行に品詞、\geから始まる行にグロスがあればよい (\exと\ntはあくまでオプション)。この形式にできたら、拡張子を.txtにして適当な場所にファイルを保存する。
最後に、さきほど作ったToolbox dictionaryをELANに読み込む。ELANにもどり、左側のカラムの「Lexicon Actions...▼」から「Import Lexicon...」を選び (「Open Lexicon...」でないことに注意)、先程保存した辞書ファイルを選択する。元ファイルのフィールドにELANでのどのフィールドを対応させるかを選ぶウインドウが出るので、下図のように選択する。
- \lx: Lexical Unit
- \ps: Gram. Category
- \ge: GLoss
- \ex: Example
- \nt: Note

この時、直接入力せず、欄の右側にあるボタンを押して出てくるプルダウンメニューから適当なものを選択すること。
「OK」ボタンを押すと、レキシコンが読み込まれているはず。レキシコンが読み込まれた後は、(1)で解説した方法で新規語彙素を追加したり既存の語彙素を編集したりできる。
Step 4: グロス付けを行う
このステップが一番感覚的に掴みづらい気がする (筆者はここで詰まり3時間くらい潰した)。
まず、各言語タイプにレキシコンのフィールドを紐付けする。別の言い方をすると、"gloss"という言語タイプのtierにはレキシコンのGlossフィールドに入力されている語形を出力してください、ということを指定する。
メニューバーの「言語タイプ」>「言語タイプの変更」を選択する。"morpheme"タイプを選択し、Lexicon connectionの右側の+ボタンを押す。一覧の中からlecical-unitを選択する。
!!この後、必ず画面下部の「変更」を押すこと!!
「変更」を押さないまま次の操作を行うと選択がキャンセルされてしまう。次に、同様の手順で"gloss"タイプにsense/glossのフィールドを割り振る。これで言語タイプとレキシコンフィールドの紐付けが完了した。

次に、どのtierの情報を読みこんでどのtierに出力するかを設定する。今回の場合、"morpheme" tierの形態素情報を読み込んで、"gloss" tierにそのグロスを出力したい。
画面左上の「Analyzer & Source-Target Configuration」を選択し、出てきたウィンドウ右下の「Edit configurations...」ボタンを押す。図のようにAnalyzerには"Gloss Analyzer"を、Sourceには"morpheme"を、"Target1"にはglossを選択する。「適用」ボタンを選択し、ウインドウをAnalyzerのウインドウも閉じる (このステップでLexicon Analyzerを選択することで、文の形態素への分割も行える。ただ、あまり使いやすくないと感じたため、この記事では始めから形態素境界を明示しておく手法をとった)。

これでやっと準備が完了したので、グロスを付ける。グロスをつけたい文のmorpheme tierの最初の形態素をクリックし、Enterを押す。すると該当の形態素が青い四角で囲まれる。この状態で画面上部の「Analyze/Interlinearize」ボタンを押すと (場合によってはなぜか2回押す必要がある)、自動でグロス付けが行われる。

やっとできた!!!!!!!!!!!
(追記) できたグロスを論文に転写する方法
ELANで行ったグロスづけを論文 (Word形式) に転写する方法を解説する。
メニューバーから「別ファイル形式で保存」 > 「インターリニアー文書」を選択する。
「文書出力の内容」では「空白の行を隠す」のみに選択を入れ、その他のチェックボックスは外す。「文書出力の形式」では、「行ごとに折り返す「各注釈の間にタブを挿入する」「Tabs Instead of Spaces」にチェックを入れる。「名前をつけて保存」を選択し、保存する。タブ区切りの.txtファイルとして保存されるので、コピーしてWordに貼り付ける (例文番号などは適宜入れてください)。

LaTeXでgb4eなどを使う場合、正規表現で変換すればよい。
残った課題
・レキシコンの"Lexical Unit"と"Citation"フィールドの使い分けがよくわからない (ここを理解すると形態素分割も自動でいけるかも?)。
・全ての文が自動でグロス付けされるときと単文しかされない時があるが、なぜかはわからない。
・日本語のように同音異義語が多いといちいち候補の選択が必要で煩雑。
・ラテン語のように屈折した語形が多い場合、全ての形をVariantフィールドに登録する必要があり煩雑 (というか日本語も表層と見出し語形が異なることが多いが、今回の場合予めtext tierに基底形を示しておくという荒業を取った)。
・バントゥー諸語のように超文節的な形態素がある場合、まったく歯が立たないのではないか。
・筆者は普段XeLaTeXのgb4eとleipzigを使っているので、その形でも出力できるようにしたい。
感想
・筆者のように日琉語族を専門にしている場合はそこそこ使える。
・屈折や文法的な超文節要素の少ない言語の場合はめちゃくちゃ使いやすいと思う。
・MacではToolboxが使えない場合があるので、「レキシコンを見やすいGUIのツールで管理する」という目的のためだけでも使う利点はあり!