TL;DR
シンプルな仕様のSinatra+ThinによるAPIサーバアプリを実装し、それらをEC2にデプロイ。同VPC内の別のEC2からApache Benchによる性能試験を行い、どれほどのスループットを達成できるか検証した。また、CPU負荷およびI/Oウェイトがスループットに与える影響について調査した。
本調査の目的
シンプルなアプリに対して負荷試験を行い、"素"の状態でどれほどの性能が出せるのか 10のx乗のオーダーでよいので知っておく。つまり、パフォーマンスの上限のようなものが知りたい。
アプリケーションコード
実験に用いたコードは以下のとおり。
require 'sinatra/base'
class MyApp < Sinatra::Base
get '/load' do
wait = params['wait'].to_f || 0
sleep wait
count = params['weight'].to_i || 100
pw = [*(1..count)]
pw.product(pw).inject(0) { |a, e| a + e[0] * e[1] }.to_s
end
end
このアプリはただ一つのアクセスポイント /load を持つ。ここにパラメータを与えると、内部で擬似的な負荷がかかる。
waitに実数を設定すると、指定秒数処理を止める。これは擬似的なI/O負荷を実現するための設定である。
weightに正の数を設定すると、O(n^2)のオーダーの計算が走るようになっている。
実験環境
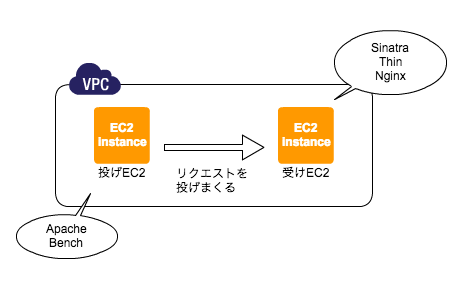
AWS上にVPCを用意し、その中で2つのEC2を作成。以降、リクエストを投げる方のEC2を「投げEC2」、リクエストを受ける方のEC2を「受けEC2」と呼称する。
受けEC2 では上述のSinatraアプリを動かしておく。バックエンドサーバはThin、リクエストを受けるサーバはnginxを利用する。
この状態で、投げEC2 からベンチマークツール、Apache Benchを実行する。
以上をまとめると図のようになる。
また、用いているソフトウェアのバージョンは以下の通り。
| name | version |
|---|---|
| nginx | 1.8.0 |
| Thin | 1.6.4 |
| Sinatra | 1.4.6 |
| ruby | 2.2.1 |
実験1
投げEC2 にSSHで入り、ab(Apache Bench)をインストール。受けEC2 で動いているアプリに対してアクセスする実験を行った。リクエスト数(-n)は一律1000とし、多重度(-c)を以下のように変化させた。記録したのは requests/sec という値で、これは1秒あたりに捌いたリクエストの数を意味している。
| key | value |
|---|---|
| 投げEC2 | m3.medium |
| 受けEC2 | m3.medium |
| リクエスト数(-n) | 1000 |
| 多重度(-c) | 1,5,20,50 |
試験する(wait,weight)の組み合わせは以下の通り。どちらも負荷が軽めのパターン1、CPU負荷を100倍に増やしたパターン2、擬似I/O負荷を10倍に増やしたパターン3を用意した。
| Parameter set | URL | wait | weight |
|---|---|---|---|
| パターン1 | http://(host)/load?wait=0.01&weight=100 | 0.01 | 100 |
| パターン2 | http://(host)/load?wait=0.01&weight=1000 | 0.01 | 1000 |
| パターン3 | http://(host)/load?wait=0.1&weight=100 | 0.1 | 100 |
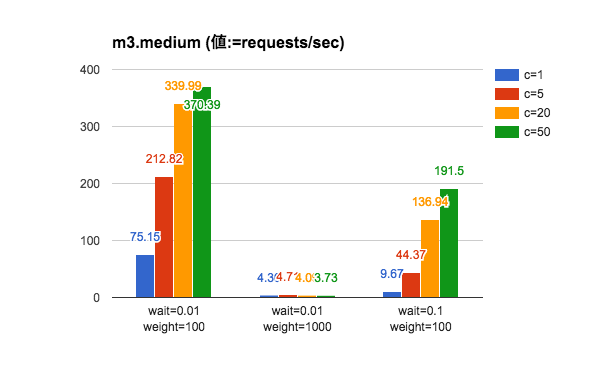
実験結果
考察
ほぼ想像通りの結果。リクエストを処理する際、CPUにリソースが食われるような状況だとマズイことが分かる。また、Thinはマルチスレッドモード(--threaded)で動かしているので、I/Oウェイトを増やしても多重アクセスに対してスケールするようになっている。Thinが生成するスレッド数はデフォルトで20になっているが、この数を増やしても実験結果に大差はなかった。
実験2
CPUにリソースが多く割かれる場合、辛いことが分かった。そこで、CPUの性能を上げるべく、受けEC2 のインスタンスタイプを c4.8xlarge に置き換えて同様の実験を行った。
| key | value |
|---|---|
| 投げEC2 | m3.medium |
| 受けEC2 | c4.8xlarge |
| リクエスト数(-n) | 1000 |
| 多重度(-c) | 1,5,20,50 |
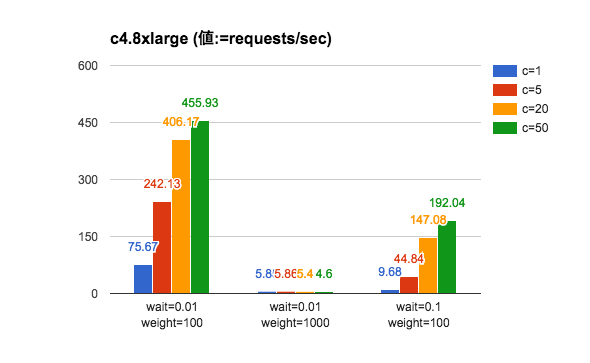
実験結果(1)
考察(1)
あれ・・・?実験1の図とあまり変化がないような。m3.mediumとc4.8xlargeで使っているCPUが別物なので多少速くなっているが、ほぼ誤差の範囲。
パターン2(wait=0.01/weight=1000)のベンチマーク実行中の様子を dstat 等で調べてみると、ほとんど CPU を使っていないことが分かった。どうやら、プロセスを複数起動しないと高性能なインスタンスの恩恵に預かることはできないようだ。
そこで、Thinのワーカーの数を 36(c4.8xlargeのvCPUと同数) に変え再度実験。
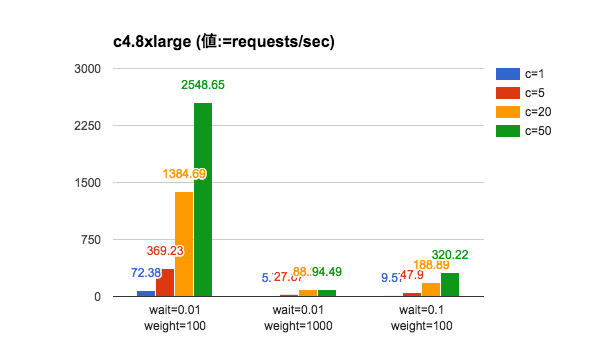
実験結果(2)
考察(2)
期待通りの結果が出た。改めて実験1の図と比較すると、CPU負荷やI/Oウェイトが増えた時の影響がより厳しくなっている。いくらサーバの性能を上げても限界はある、ということだろう。
実験3
ちなみに、c4.8xlarge で Thin の worker数 36 の状態でCPU負荷、I/Oウェイト共に軽くするとどうなるだろうか・・・?
m3.mediumと比較して試してみた。
| key | value |
|---|---|
| 投げEC2 | m3.medium |
| 受けEC2 | m3.medium(w=1), c4.8xlarge(w=36) |
| リクエスト数(-n) | 1000 |
| 多重度(-c) | 1,5,20,50 |
| Parameter set | URL | wait | weight |
|---|---|---|---|
| パターン1 | http://(host)/load?wait=0&weight=0 | 0 | 0 |
実験結果
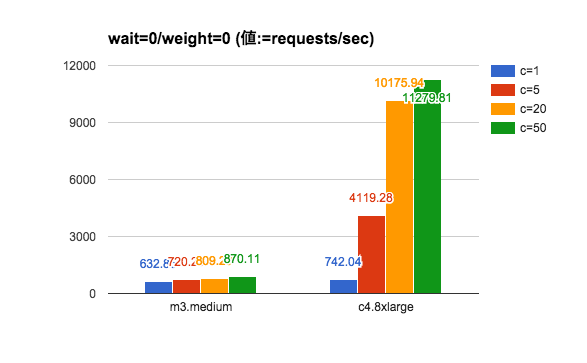
考察
爆速。今まではI/OウェイトとCPU処理がボトルネックとなり、レスポンス生成に時間がかかっていたということが分かる。
個々の処理が重くない 多重アクセスに対してはインスタンスを性能のよい物に置き換え、かつ適切にワーカー数を設定することでスループットが上がるようだ。
まとめ
Sinatra+Thin環境で負荷が軽い場合、m3.medium で およそ500リクエスト/秒を捌けるようだ。c4.8xlargeだと1万リクエスト/秒を処理できる。もちろんこれは上限の値であり、実際のアプリでは別の要因による制限を受けうることに注意。