はじめに
本資料は、文字コードについてよく知らないニューカマーに向けて説明するために、個人的にまとめた資料である。
まず第一に、文字コードの海に入ったが最後、溺れることを覚悟すること。
#文字コードの海には、多数の座礁ポイントに加え、数多のクラーケンが存在する。
#しかも、共に海を渡るはずの仲間たちは、この資料を読んだ人を容赦なく生贄にささげようとするだろう。
#この海には、敵しかいない、強くなれ。
何はともあれ、良き船出に、よき後悔を。
注意事項
本書は以下2種類にレベリングして記載している。
入門: 基礎基本。
初級: 入門の一つ上。実践時によく話題になるモノなど。
おっと、忘れるとこだった、あとひとつ、大事な注意事項がある。
ここから先は、「B級アメリカ映画なノリ」「鼻についた表現」に耐性のないヤツはどっかいきな。
そう言うノリも含めて、この記事だ。大丈夫な奴だけ進んでくれ。
用語
入門編
日頃「文字」とか「文字コード」とかテキトーに使っているが、厳密には以下に記載した専門用語を駆使しないと、適切な表現にはならない。
逆に言えば、これが分別できてないヤツと会話するのは不毛だ。砂漠なんて目じゃねぇくらいだ。
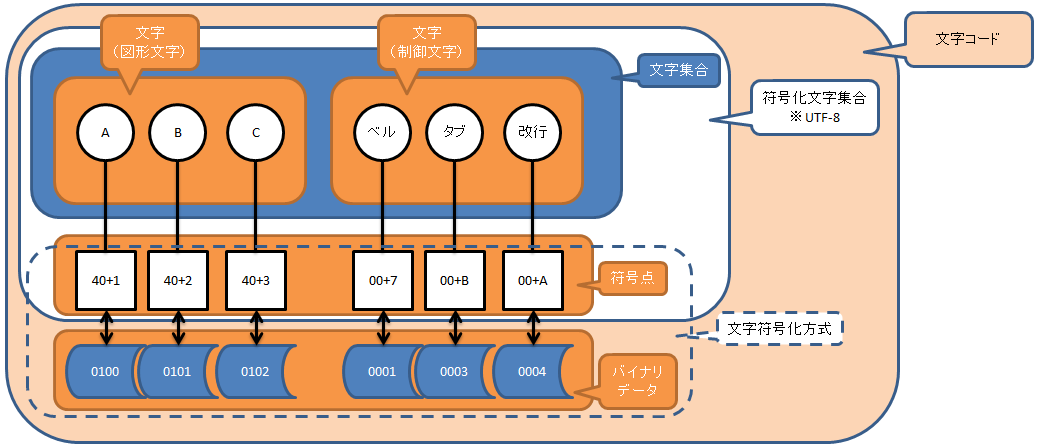
文字(character):「A」や「B」などの言語を書き記すための記号・図形。図形文字と制御文字がある。
符号点(code point):「U+3042」などの文字を割り当てうる個々の点(16進数を用いて表現される)。バイナリデータとは異なる。
バイナリデータ:バイトの組み合わせ。符号点とは異なる。ビット列とも呼んだりする。
フォント(font):文字の表示の仕方。「MS ゴシック」だとか、「MS 明朝,平成明朝」とかのこと。
文字集合(character set):文字の集まり
文字コード:一般的には「符号化文字集合」に同じ。「文字符号化方式」を指す場合もある。
符号化文字集合(coded character set):符号点と文字を一対一に対応付ける、あいまいでない規則の集合
文字符号化方式(character encoding scheme):符号点を、バイナリデータに変換する方式
※符号化文字集合と文字符号化方式を兼ねる体系もあるし、それぞれ独立存在している体系もあるため、明確に定義がされているわけでは無かったりする。
図形文字:一般的な文字のこと(「あ」とか「い」とか「A」とか)
制御文字:改行コードなど、出力・表示を制御するための役割を持つコード
※制御文字例:ベル(ビープ音)、水平タブ、改行、エスケープ
※スペース(空白)は現行の規格では、「図形文字」扱い。
イメージ図
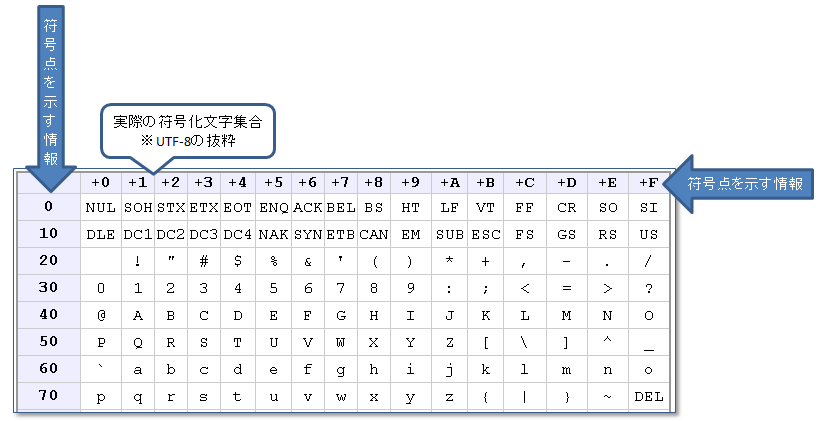
符号化文字集合の例:「JIS X 0208」など
文字符号化方式の例:「ISO-2022-JP」「EUC-JP」「Shift_JIS」など
初級編
ここで紹介するのは、イかれたヤツらさ。
特にBOMなんて、普段は潜んでやがるから、爆発しないと気づけない。
そう、名実ともに爆弾(bom)なんだ。
BOM(byte order mark:バイトオーダーマーク:バイト順マーク):
Unicodeの符号化形式で符号化したテキストの先頭につける数バイトのデータ。
このデータを元に符号化の種類の判別を行う。
※BOMは必須ではない。そのため、unicode系の文字コードで作成されたデータでも、BOM付きとそうでないデータが存在する。
サロゲートペア:UTF-16において、16ビットで表せる範囲を越えて、文字を表示するために用いられている方式。16ビットUnicodeの領域1024文字分を2つ使い、各々1個ずつからなるペアで1024 × 1024 = 1,048,576文字を表す。
※文字コードの海において、よく座礁した船が見つかる海域。(遠浅の海)
文字が表示される仕組み
入門編
チョー基本的な仕組みだ。押さえとけ。
これがワカらねぇなら、家に帰ってママのミルクでも飲むんだな。
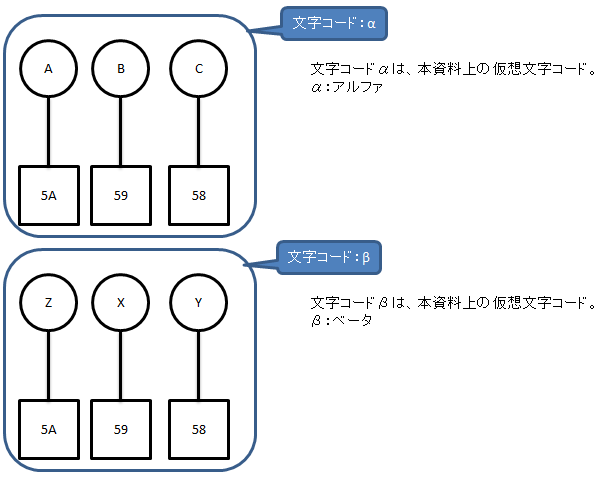
バイナリデータ「5A 59 58」を、文字コードαだとして解釈して表示した場合
→「A B C」と表示される。
バイナリデータ「5A 59 58」を、文字コードβだとして解釈して表示した場合
→「Z X Y」と表示される。
※バイナリデータを変換するわけではなく、バイナリデータに対応する文字として何を表示するかが異なる。
イメージ図
初級編
ちょっとレベルアップするが、大した話じゃない。
複数バイト文字コード:複数バイトで1文字を表現する文字コードのこと。1バイトで表現できる文字数には限り1があるため、文字数の多い文字体系(漢字など)に対応するために生まれた。
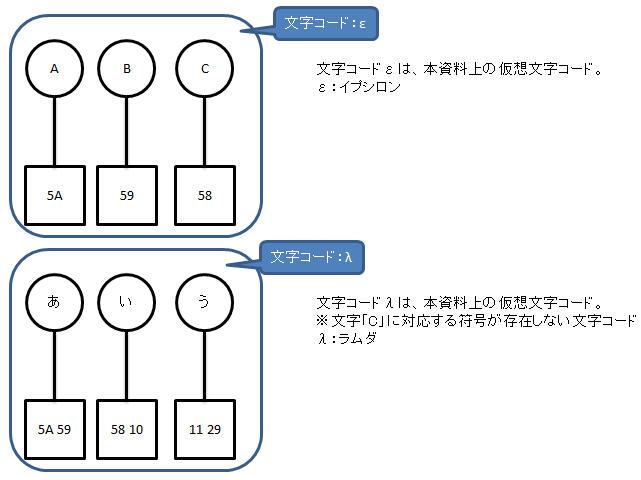
文字コードεで作成された文字「A B C」を、文字コードλで解釈すると。
→符号「5A 59 58」 →文字「あ ■」 となる。
※文字化けした「■」(符号:58)が実際にどう表示されるかはシステムによる。
※汎用機系では、よく「全角文字(ひらがなとか漢字とか)」を「2byte文字」なんて表現する人がいるが、全角だからとか/文字が大きいからといって、「2byte文字」かどうかとは直接関係はない。
文字化けの仕組み
こいつは厄介だ。一番厄介なのは、何も分かってねぇヤツに説明しなきゃならんところだ。
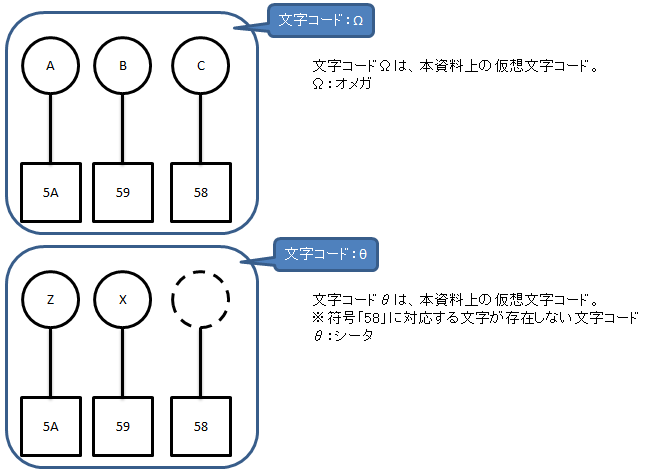
パターンA
バイナリデータ「5A 59 58」を、文字コードΩだとして解釈して表示した場合
→「A B C」と表示される。
バイナリデータ「5A 59 58」を、文字コードθだとして解釈して表示した場合
→「Z X ■」と表示される。
※文字化けした「■」(符号:58)が実際にどう表示されるかはシステムによる。
※文字集合が同じ場合でも発生しうる。(バイナリデータと文字の対応の違い)
※バイナリデータは変換しないが、対応する文字が変わるパターン。
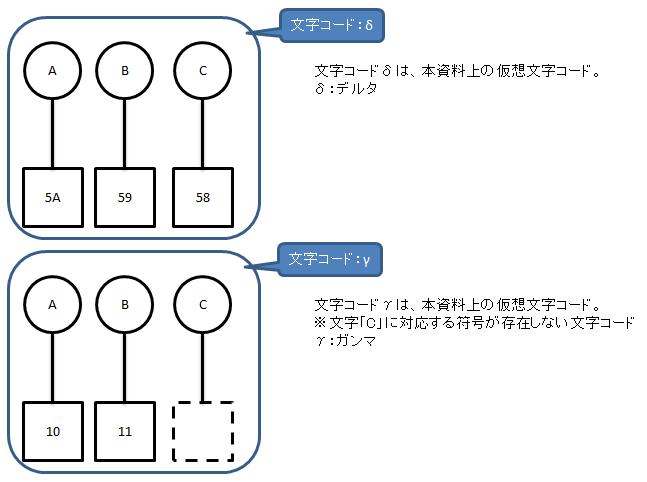
パターンB
文字コードδで作成されたバイナリデータ「5A 59 58」を、文字コードγに変換した場合。
→符号「10 11 ??」に変換される。
→結果、文字「A B ■」と表示される。
※文字化けした「■」(符号:58)が実際にどう表示されるかはシステムによる。
※文字集合が異なる場合に発生しうる。
※バイナリデータを変換するパターン。
文字コードの理解を阻む問題
相手にとっちゃ、このマリアナ海溝は見えてないんだ。一緒に沈んで、相手が窒息するのを待つしかない。
何?自分は溺れたくないって?それじゃぁ別のヤツを探すしかねぇな。
誤った用語の使用
エンコード(encode:符号化):
この用語自体は、文字コード変換以外の場面でも使われる。(エンコードは「文字コード変換」だけを示すものではない。)
エンコードの厳密な意味は、「特定の方法で、可逆的な変換を加えること」だ。
例えば「Base64にエンコードする」というのは、「Base64に文字コード変換する」という意味ではない。
なお、文字コードやバイナリデータを指すつもりで利用しているのを聞いたことがあるが、それは完全に誤り。
文字コード:
だいたいは、「Shift_JIS」なのかとか、「UTF-8」とかってレベルで会話するので、この単語の定義自体が問題になるケースは少ないはず。
そもそもの定義自体も少し曖昧なので、厳密な定義を気にする場面が来たなら、ちゃんと確認しましょう。
文字の量が膨大
よく文字コードが絡むと、「何が使えない文字なの?」と聞かれるが、人力でやって終わるものじゃない。
(理屈を理解して)プログラムを組んで比較するか、世間に落ちている落とし所のパターンを活用するなどをした方が良い。
エクセルに一覧化して・・・とかは、くれぐれも止めてくれよ。
よくある文字コードの問題
入門編
こんなのが分からないって言うのは、学生さんまでだ。
改行コード:大きく3種類ある
CR/LF/CRLF
→混在もしくは、想定外の改行コードを使用している場合、コンパイルがうまく通らなかったりする。
→見た目は問題ないのに、コンパイルできなかったり、処理がエラーになるので、はまる。抜け出せない。
→いろいろ試した結果、ここが原因であると知ったときの徒労感はすごい。ものすごい。
全角・半角
由来:全角・半角は、印刷の用語。横幅が全角の半分のサイズの文字を半角と呼んでいる。
PC上での表示サイズが半分だからといって、半角というわけではない。
PC上での表示サイズは、フォントによって規定されるため、文字コードが文字幅を規定しているわけではない。
とはいえ、「ア」も「ア」も文字コードの中には存在している。
ちなみに、「ア」で検索した場合、「ア」もヒットさせたい!という要求があるが、
結構面倒なことを考え始めないといけないので、注意すべし。
※シフト演算とかでうまいことできるかもしれないが、よく知らないので、調べてください。
※そもそもの話だが、「ア」も「ア」もそれぞれ別の文字コードが割り当てられている。
初級編
これらを本当に理解できるのは、自分で地雷を踏んでからだろうがな。
円記号問題
バックスラッシュと円記号が、互いに入れ替わることのある問題。
\:バックスラッシュ
¥:円記号
結構根深い問題なので、直面しないように避けること。
両者ともにエスケープ文字として使用される場面もあるため、特殊な記号として扱われがちなため、要注意。
波ダッシュ問題
https://ja.wikipedia.org/wiki/%E6%B3%A2%E3%83%80%E3%83%83%E3%82%B7%E3%83%A5
「波ダッシュ」を入力しようとすると、「全角チルダ」が入力されてしまったり、
そもそもの文字コードの対応が間違っていたりと散々な話。
波ダッシュに類する問題
http://d.hatena.ne.jp/sardine/20060214/p1
- (マイナス)
∥ (二重垂直線)
¢ (セント)
£ (ポンド)
¬ (否定)
tips
tipsっつーか、テメーが生きていく上で、よく聞くであろう文字関連の用語たちだ。
どいつもこいつも、本当の理解者がいない、孤独なヤツばかりさ。
優しくしてやってくれ。
入門編
unicode:世界で使われる全ての文字を共通の文字集合にて利用できるようにしようという考えで作られた文字コード
UTF-8:ASCIIと互換性があることから広く使われている文字コード。
UTF-16:UTF-8の次ぐらいに有名。サロゲートペアを用いることが特徴。
※文字コードの海で出会ったらとりあえず逃げよう。
unicodeに存在しない文字:https://ja.wikipedia.org/wiki/Category:Unicode%E3%81%AB%E5%AD%98%E5%9C%A8%E3%81%97%E3%81%AA%E3%81%84%E6%96%87%E5%AD%97
下記「たいと」など、普段使わないような文字。

「unicodeは『全ての文字』が対象じゃないのか?」だって?
何事にも例外はつきものって言うだろ?
坊やの見えている範囲だけが世界じゃないのさ。
初級編
SJIS/Shift_JIS:よくある勘違いだが、「SJIS」は「Shift-JIS」ではない。
MS932/CP932/Windows-31J
MS932は、「Microsoftコードページ932」「CP932」「Windows-31J」と呼ばれたりする。
全部一緒。Windowsの入力パターン。
「SJIS」にいくつかの文字集合を加えた文字コード。
この、追加された「いくつかの文字集合」が厄介。
「①」などの機種依存文字がそれに該当し、よく問題を引き起こす。
CP943C
文字集合レベルではMS932と同じだが、符号点レベルではMS932と一部異なる。(紐付が異なる)
※ちなみに、CP943Cは、CP943を拡張した文字コード。
※下記がMS932と紐付けが異なる部分。
-(FULLWIDTH HYPHEN-MINUS)
―(HORIZONTAL BAR)
~(FULLWIDTH TILDE)
∥ (PARALLEL TO)
¦(FULLWIDTH BROKEN BAR)
※テストする際は、波ダッシュ問題と併せて検証するとよい。
最後に
ここまで付き合ってくれてありがとな。
でも言っちゃあ悪いが、こんなB級記事なんかじゃなくて、ちゃんとした本を読むのが、正しい道だぞ。
例えば、「文字コード技術入門」は、オススメだ。
おっと、どうやらここでお別れみたいだ。
もうこんなとこには来ちゃダメだぞ。
どうしても戻って来たくてもダメだ、その時は正しい道を行け。
ここに解決策は無い。
寂しいもんだが、別れがあれば、出会いもあるさ。
もう二度と会わないことを願ってるぜ。
じゃあな
更新履歴
2017/12/03:コメントでいただいた指摘を取り込みました。
-
1byteで表現できる図形文字は、96文字までしかない。 ↩