昨今、継続的にプロダクト開発していくことが主流となり、Four Keysなどの開発パフォーマンスを測る指標なども出てきており開発生産性を向上させることが注目されています。
しかし、かつての開発現場では今では信じられないような開発生産性を爆下げするようなことをやっていました。
この記事では10年以上前に私が経験した開発生産性を爆下げする事例を書いていこうと思います。
(私が体験したことをベースに書いているので10年前は全てがこうだったということではないのでご留意ください ![]() )
)
修正前のコードはコメントアウトで残す
当時、ウォーターフォールで開発していました。
ウォーターフォールでは開発工程とテスト工程が分かれています。
開発工程で一通りコーディングして、テスト工程で動作確認を行いバグを潰します。
問題はここからです。
とある現場では、テスト工程でバグを直すときにコードを破壊的に直すのではなく、元のコードをコメントアウトで残すというルールがありました。
簡単な例を使って説明します。
引数を3倍にして返却するメソッドを実装するとします。
# iを3倍にして返す
def hoge(i)
i * 2
end
上記は3倍にしないといけないのに2倍にしてしまっています。
このバグをテスト工程で見つけた直す場合は下記のように修正します。
def hoge(i)
# 2023/03/15 修正者: ham
# i * 2
i * 3
end
元の実装は削除せずにコメントアウト、その上に対応日と担当者を追記します。
この現場ではコードのあらゆる箇所に上記のようなコメントが散在しているため、コードの可読性がかなり悪いです。
コードは書くより読むことの方が多いので可読性を上げることは生産性向上の第一歩ですが完全に逆行してしまっています。
ちなみに、もしかしてコードのバージョン管理ツールがない時代の話?と思われた方もいるかもしれませんが、CVSやSVNなどのバージョン管理ツールは使っていたので変更履歴などは確認できる現場でした。
IDがついたクラス名
とある現場では画面や機能にユニークなIDをつけていました。
例えば、「DISP001: ユーザー登録画面」「DISP002: ユーザー編集画面」のような感じです。
IDは連番であり、画面や機能を推測できるようなものではありません。
この現場では上記IDをクラス名に使うというルールになっていました。
そのためエディタのツリーが下記のようになります...!
- DISP001.do
- DISP002.do
- DISP003.do
...
- DISP010.do
どのファイルが何なのか全くわかりませんねw
これでは探している画面や機能のファイルを見つけるだけで一苦労で、ファイルを見つけるだけで無駄に時間がかかってしまいます...
クラス名やメソッド名、変数名にわかりやすい名前をつけるのはリーダブルコードの鉄則です!
詳細設計という名の日本語コーディング
ウォーターフォールでは前工程へ戻ることは許されないので、手戻りを減らすために細かく設計することが求められます。
とある現場では実際にコードを書く前に詳細設計という名の日本語コーディングを行なっていました。
日本語コーディングとはどういうものかというと下記のようなイメージです。

みんな大好きExcel方眼紙に処理の詳細を書きます。
特に「詳細」の部分は処理の細かい部分まで書かれており、コーディングすることを日本語で書いているような内容になります。これをこの記事では日本語コーディングと呼んでいます。
これを書くために頭の中でコードを思い浮かべていると思うので、この時点でコードとしてアウトプットした方が圧倒的に効率が良いのは明白です。
また、この粒度で書かれているため、後工程でコードを修正した場合にほぼ100%の確率で詳細設計も修正する必要があり後工程の生産性を下げることにも寄与します。
書いた行数で進捗管理
とある現場では、開発工程の進捗は書いたコードの行数で管理していました。
コードの行数が多いほど進捗が良いということです。
また、見積もり時の工数算出を想定コード量から計算するため、実際にコーディングするときに簡潔に書いてコード量が減ってしまうと見積もりと乖離してしまいます。
見積もりより大幅にコードが少ない場合、工数が削減できたと判断され(実際には削減できているかどうか関係なく)次回以降の工数確保が難しくなる恐れがあります。
それを避けるために、コーディング規約でコード量を削減するような書き方、例えば3項演算子やカッコを省略するif、1行で複数の変数を宣言するような行数が少なくなる書き方は禁止されていることもありました。
生産性を上げるプラクティスの1つはコード量を減らすことですが、コーディング量を増やすという生産性向上とは真逆のことをしていました。
エビデンスを大量に保持。ログやDBダンプ、キャプチャを全部残す
実装した後、動作確認を行うことはどの現場でもあると思います。
ただ、とある現場では1つテストをするごとに前後のDBダンプやログ、操作したキャプチャなどテストをした証跡を事細かに残していました。
しかし、工数をかけて保存している証跡ですが後から使われることはほぼなく、ただただテスト工数を数倍に跳ね上げているだけの存在でした。
実態は品質云々ではなく納品物に含まれているのでやらざるえなかったということなのでしょうが、このように本質的ではないタスクがたくさんあったな〜と懐かしく思います。
デバッガで止めた状態をキャプチャ
1つ前の事細かなエビデンスの時点でツラいですが、過去最高にツラかったのは単体テストのホワイトボックステストで分岐前後のキャプチャを残すというものでした。
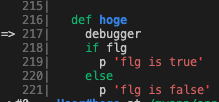
例えば下記のようなコードを書いた場合
def hoge(flg)
if flg
p 'flg is true'
else
p 'flg is false'
end
end
-
flg == trueの証跡
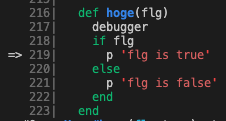
-
flg == falseの証跡
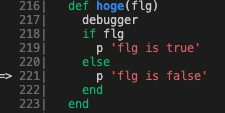
のようにキャプチャを残します。
ホワイトボックステストなので数は膨大です。ほぼ全コードのキャプチャをとっているようなもので、控えめに言ってもこのキャプチャを残す・残さないで単体テストの工数は10倍以上増えたと思います。
ちなみに上記は納品物に含まれており、上記のキャプチャをExcelに並べて貼って、見るべきポイントを赤枠で囲い、最後にPDFにするという作業も必要で言葉を失いました。
印刷して納品。Excelの改ページプレビューにやられる
プロダクトを納品するとき、設計書類を印刷してキングファイルに綴じて提出するというものがありました。
ちなみにCDで電子ファイルとしても提出しています!!
このとき「詳細設計という名の日本語コーディング」で登場したExcel方眼紙が猛威を振います。
Excelを印刷したことある方ならほぼ100%経験すると思いますが、Excelの印刷範囲は初期状態ではほぼうまくいきません。
だいたい下記の図のように絶妙にずれますw
(下記は手元にExcelがなかったのでスプレッドシートでそれっぽく加工しています)

これをちまちま修正する必要があり、印刷し終わるまでに余裕で1日かかります。
最後に
以上、昔の話を思い出して書いてみました。
今となっては雑談のネタになるので良い経験だったなと思いますw
そんな私も今では開発生産性をどう向上させるか日々考えながら開発しています。
昨今、開発スピードと品質は相反するものではないということが広まってきているので、本当に必要なものを見極めながら効率よく品質の高い開発ができたら良いなと思います。