■**「単語の意味」をコンピュータに理解させる3通りの方法 (p59~)**
1. シソーラス
-
同義語と上位・下位の関係性をピラミッドのように定義した辞書
-
WordNet(1985~) 20万語以上
- メンテナンスが大変!
2. カウントベース
-
コーパス
- 大量のテキストデータ(+品詞やラベル))を使う
-
単語の分散表現
-
色の3次元の分散表現=(255,255,255)
- カウントベースや、推論ベース(NN)がある
-
-
分布仮説
- 単語の意味は、周囲の単語(コンテキスト)によって形成される
-
共起行列
- ウインドウサイズ1の共起行列、などと言う
-
コサイン類似度
- 2つの単語ベクトルの類似度を表現
-
相互情報量
-
高頻度な単語との関連性を低く調整する式
-

-
Pointwise Mutual Information
-
PMIを使ってPPMI行列に変換!(元の共起行列の重みが0or1から変わる)
-
-
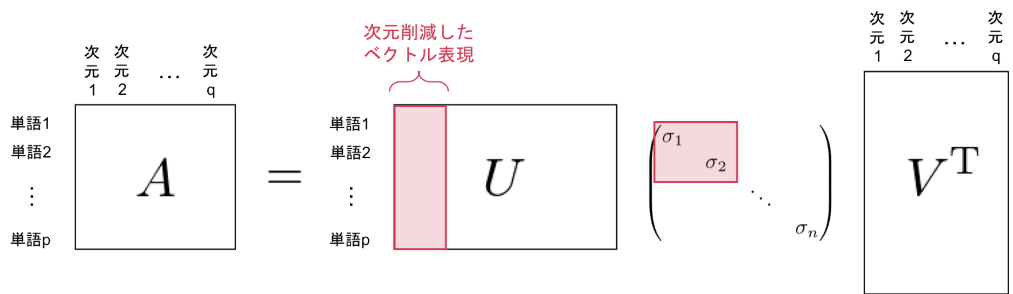
次元削減(dimensionality reduction)
-
重要な情報を残しつつ次元削減をして、ノイズに強くする。頑健性を高める。
-
特異値分解 (SVD : singular value decomposition)
-
普通にやるとO(n^3)のオーダー!(n=単語数)
-
計算オーダーの小さいTruncated SVDもある
-
-
-
3. 推論ベース(word2vec)
-
ニューラルネットワークのメリット
- SVDではコーパス全体を1度に学習するが、NNはミニバッチ学習が可能
-
推論ベースから単語の分散表現を作るには?
-
コンテキストを入力→モデル→単語を推測
- モデル自体が各単語の分散表現になっている(らしい)
-
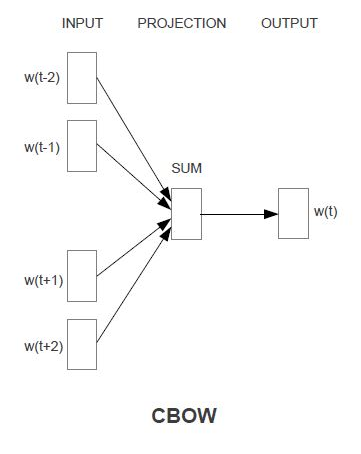
CBOWモデル(Continuous bag-of-words)
-
コンテキストからターゲットを推測するNN
-
中間層=単語の分散表現
-
-
ソフトマックス+クロスエントロピー誤差→負の対数尤度
- これを最小化する=誤差が0になる
skip-gramモデル
-
こちらの方が、単語の分散表現の精度が高い
- 低頻出の単語や、類推問題の性能が比較的良い
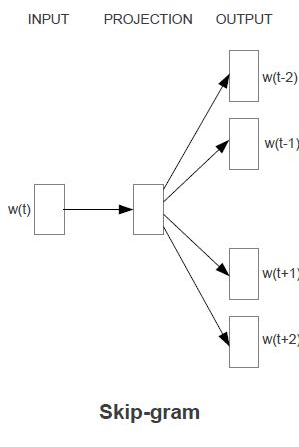
カウントベースも推論ベースも類似性の精度の定量評価は変わらない。
推論ベースは追加学習出来るのがメリット
■word2vecの深堀
word2vecの高速化
Embedding layer
- one-hotベクトル(入力ベクトル)と重みとの積ではなく、ハッシュ化する。
Negative Sampling
-
多値分類から二値分類へ
- ソフトマックス関数からシグモイド関数へ
-
ここで想定される問題は、推論時に「say」に該当する単語を、全単語数当てはめないといけないように感じる。
- ただ、目的は分散表現を作成(学習まで)してそこから、意味を足し算引き算したり、クラスタリングしたり、なので推論にかかる時間はあまり重要ではない。
-
もう一つの問題は、負例の問題を学習していないことにある。
-
そこで、負例データを少数(5~10)サンプリングする。(p153)
-
コーパスの統計データに基づいてサンプリングするのが良い。
-
ただ、単語の確率分布の0.75乗したものの方が推奨されている。
- 低頻度の単語のサンプリング確率を微増させるため。
-
-
改良版word2vecの学習(p164)
-
ウインドウサイズは2~10が良い
-
分散表現の次元数は50~500が良い
word2vec(分散表現)の他のメリット
-
転移学習ができること。
-
文章を固定長の単語ベクトルに変換できること。
-
単語ベクトルの総和による文章のベクトル表現化(bag-of-words)
-
RNNによる文章の固定長ベクトルへの変換
-
単語ベクトルの評価方法(p172)
-
Semantics…単語の意味の類推問題の正解率
-
Syntax…単語の形態情報の問題の正解率
■まとめ
単語をベクトル化すると、様々な問題を解くための「入力値」として使える!