"How to Win a Data Science Competition: Learn from Top Kagglers"のまとめノートです。
https://www.coursera.org/learn/competitive-data-science
Week1は、データの前処理についての解説がメインでした。
曖昧な情報ありなので、あくまで参考程度にしてください。|д゚)
競争力学
- 競技規則をちゃんとみること。
- 競技にはkaggle、DKK、VizDoomなどがある。
- コンペ中のランキングに使われるデータセットと、最終ランキングに使われるデータセットは異なる。
実世界のアプリケーション対競争
- データに関する知識が重要。
メインMLアルゴリズムの要約
- 線形モデル(ロジスティック回帰、SVM)
- ☆ツリーベースメソッド(決定木、ランダムフォレスト、勾配ブースト決定木(XGBoost、LightGBM))
- k-最近傍
- ☆ニューラルネット
ソフトウェア/ハードウェア要件
- 最小
- 16GB RAM
- 4コア
- 推奨
- 32GB RAM
- 6コア
- クラウドはAWAのスポットインスタンスが注目
- 言語はpython
- ライブラリはnumpy, Pandas, Matplotlib, Jupyter notebooks
- おすすめはXGBoost, LightGBM
- その他
- Vowpal Wabbit
- これは、驚異的な速度と速度を提供するように設計されたツールです メモリに収まらない大規模なデータセットを処理します。
- Libfmとlibffm
- 異なるタイプの最適化マシンを実装しています。 クリックスルー率(CTR)予測のような疎なデータによく使用されます。
- Rgf (Regularized Greedy Forest)
- アンサンブルで使うことをお勧めする別のベースメソッドです。
- Vowpal Wabbit
モデルに関する特徴量の前処理と生成
Overview
- タイタニックのデータ
- データの特徴タイプ(feature)
- 数字
- カテゴリ
- 日時
- 座標(coordinate features)
- データのそれぞれ異なる特徴に対して注意する必要がある理由
- 特徴を前処理(preprocessing)するため
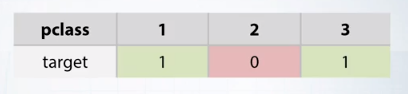
- 非線形の関係(x=pclass, y=target)を線形モデルに当てはめる方法
- 説明変数を分けて、それごとにモデルを作る。
- pclass値ごとに1つ 線形モデルは、以前の場合よりはるかに良くフィットします。
- ランダムフォレストの場合は、上記を行う必要はない。
- 説明変数を分けて、それごとにモデルを作る。
- 非線形の関係(x=pclass, y=target)を線形モデルに当てはめる方法
- 特徴を生成(generation)するため
- 来週の売り上げ予測をするには、データに週番号を示す特徴を加える必要がある。
- 特徴を前処理(preprocessing)するため
数値
Preprocessing(前処理)
- Tree-based models
- scaling
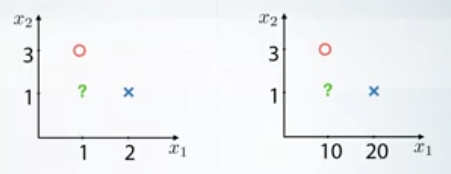
- MinMaxScalerを使うとよい。
- 主にKNNのため
- StandardScalerを使うとよい。
- 主にKNNのため
- outlier(外れ値)
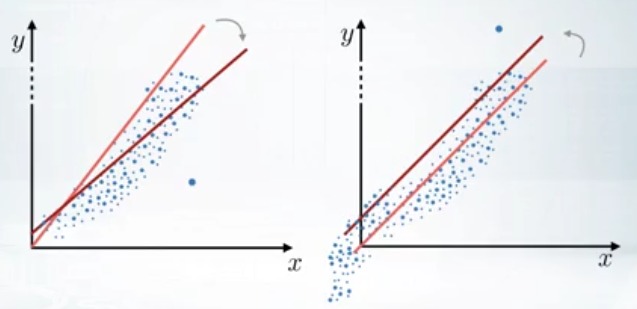
- 99パーセンタイルなどを使って、一定の外れ値を除去すべき。(金融データでは winsorizationと呼ばれる)
- rank
- scipyで使える
- 等しくなるように昇順値の間にスペースを入れる?
- NNで特に使える前処理
- logをとる
- 平方根を取る
- 特徴の平均値に近い大きすぎる値をドライブする
- ゼロに近い値は、もう少し区別がつくようになる
- その他の応用
- ああああああ?
- 異なる方法で前処理されたデータのトレーニングモデルを混ぜる。
- scaling
- Non-tree-based models
- 特徴のスケールには依存しない。
Feature generation(特徴量生成)
- データに関する事前知識があるとよい。
- EDA (Exploratory data analysis)を行ってから、生成するのもよい。
- 特徴量の生成例
- 単位当たりの数値
- 座標情報を基にした距離
- ツリーモデルは掛け算や割り算に弱いし、こういった特徴を作っておけば、木もシンプルになる?
- 価格情報の小数部のみを取り出した特徴
- 価格に対する人々の知覚の違い
- 想像力(創造力)(creativity)とデータの理解が、有効な特徴生成のカギ。
カテゴリ(category)と順序(ordinal)の特徴
順序
- ordinal = ordinal category future (順序カテゴリ特徴量)
- 例えば、自動車免許のランク、教育のレベル(小中高大)などがある。
- 数値と順序カテゴリの違いについて注意する必要がある。
- 順序カテゴリはその間の差を算出することはできない。
カテゴリ
概要
- カテゴリフィーチャをエンコードする最も簡単な方法は、ユニークな値(主に文字列?)を別の数値にマップすることです。?(Label encoding)下記、2つの方法により、うまく動作する。
- ツリーメソッドがフィーチャを分割できるため。??
- ツリーメソッドがカテゴリ内の有用な値の大部分を抽出できるため。??
- 逆に、ツリーベースでないモデルは、通常、この機能を効果的に使用できません。
- 線形、k-NN、NNを使う場合は、カテゴリフィーチャを別々に扱う必要があります。(カテゴリをフラグにするということ?)
Label encoding
- 方法1:アルファベット順
- S,C,Q → 2,1,3
- sklearn.preprocessing.LabelEncoder
- 方法2:外観のソート順
- S,C,Q→ 1,2,3
- pandas.factorize
- データが意図をもってそのような順になっていた場合は、この方法は合理的である。
Frequency encoding
- 各カテゴリの値 → 各カテゴリの出現頻度 にエンコード
- S,C,Q→ 0.5,0.3,0.2
- encoding = titanic.groupby('EMbarked').size()
- encoding = encoding/len(titanic)
- titanic['enc'] = titanic.Embarked.map(encoding)
- ツリーベースモデルでも、非ツリーベースのモデルでも、周波数エンコードが役立つ。
- 非ツリーモデルの場合、カテゴリの頻度が目標値と相関する場合、線形モデルはこの依存性を利用する。
- ツリーモデルの場合、分割数が少なくて済む。
- カテゴリごとの頻度が同じ場合は周波数エンコーディングは意味がなくなる
- 下記方法で確認できる・・?
- from scipy.stats import rankdata
- 下記方法で確認できる・・?
One-hot encoding
- 線形、k-nn、NNに効果的。

- 数値特徴が少なく、one-hotエンコーディングで何百ものバイナリ・フィーチャが使用される場合、最初のもの(数値特徴)を効率的に使用するツリー・メソッドでは困難になる可能性がある。より正確に言えば、ツリーメソッドは遅くなり、必ずしも結果にたどり着かなくなる。
- 疎行列について知っておく必要があります。非ゼロ要素のみを格納することができ、多くのメモリを節約できます。
- ゼロ以外の値の数がすべての値の半分よりもはるかに小さい場合は、疎な行列を使用すると意味があります。
- スパース行列は、カテゴリのフィーチャやテキストデータを扱う場合に便利です。
- 一般的なライブラリのほとんどは、XGBoost、LightGBM、sklearnなど、これらの疎な行列を直接操作することができます。
- ツリーベースおよび非ツリーベースのモデルのカテゴリ機能を事前処理する方法を理解した後、機能の生成を簡単に確認できます。
- 特徴生成の最も有用な例の1つは、いくつかのカテゴリ特徴間の特徴相互作用である。
- これは通常、木以外のモデル、すなわち線形モデル、kNNに有用です。
- たとえば、ターゲットがPclassフィーチャと性別フィーチャの両方に依存すると仮定します。
- これが当てはまる場合、線形モデルはこれらの2つのフィーチャの可能なすべての組み合わせについて予測を調整し、より良い結果を得ることができます。
- どうすればこれを実現できますか?この相互作用を追加するには、列とワンホットエンコーディングの両方の文字列を単純に連結します。
-
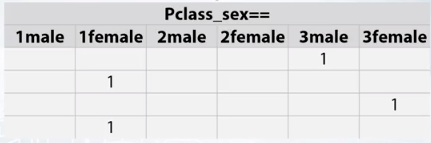
- 線形モデルはすべての相互作用に最適な係数を見つけて改善することができます。
- シンプルで効果的。
- 機能の相互作用に関する詳細は、特に、高度な機能のトピックでは、数週間後に来る予定です。
要約
- 第1に、順序はカテゴリの特徴の特殊なケースですが、意味のある順序で値がソートされています。
- 第2に、ラベルのエンコーディングは、基本的にこのカテゴリの特徴のユニークな値を数字で置き換えます。
- 第3に、この用語における周波数エンコーディングは、固有の値をそれらの周波数にマッピングする。
- 第4に、ツリーベースの方法では、ラベル符号化および周波数符号化がしばしば使用される。
- 第5に、one-hot・エンコーディングは、非ツリー・ベースの方法にしばしば使用される。
- 最後に、ワンホットエンコーディングの組み合わせを心臓と心音の組み合わせをカテゴリの機能の組み合わせに適用することで、非ツリーベースのモデルは特徴間の相互作用を考慮して改善することができます。
- 私たちは、カテゴリー的なフィーチャーのフィーチャー前処理を選別し、フィーチャー生成について簡単に見ました。
- 今度は、次回のコンペでこれらのコンセプトを適用し、より良い結果を得ることができます。
日時、座標特徴量
日時
- 2つ?に分けられる
- その瞬間(タイムスタンプ)
- 秒、分、時、日、月、年などの特徴を追加することができます。
- データ内の反復パターンを取り込むのに便利
- 秒、分、時、日、月、年などの特徴を追加することができます。
- 経過時間
- 低独立性
- 1970/1/1 0:00:00からの経過時間
- 低依存性
- 特定の出来事からの経過時間
- 低独立性
- 時間差
- その瞬間(タイムスタンプ)
- 例
- 曜日、年初からの日数、休日フラグ、祝日までの日数
- 解約予測をする場合に、最終電話の日ー最終購入日=日付差異 という新しい特徴量を追加できる。
座標
- ある建物から別の目的物への距離の算出ができる。
- 最も地価の高いグリッドとの距離
- クラスターの中心との距離
- エリア周辺のオブジェクトの集計統計(領域または極性として解釈できる)
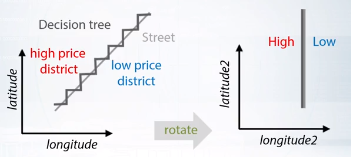
- 決定木を使う場合は、座標自体を回転させると精度よく分割できる場合がある。
欠損値の扱い
- 隠れNaNs
- ヒストグラムを描く
- 変な数字に置き換えられている場合を抽出できる。
- (→正直、ちゃんと翻訳できなかった。。。)
- Fillna approaches
- -999,-1,etc
- 全く関係のないカテゴリを追加して、置き換える。
- ツリーメソッドにとっては良い。
- →線形ネットワークの精度が落ちやすい。
- mean, median
- 平均や最頻値に置き換える。
- ツリーメソッドだと、欠損値を持つオブジェクトを選択することは難しくなります。?
- Reconstruct value
- isnullフラグをつける
- これにより平均値または中央値を計算しながら、ツリーやニューラルネットワークの問題を解決できます?
- 欠点は、データセット内の列の数が倍になること
- 既知のデータの間の差の中間の値で補完することも可能?
- 欠損値を予測するモデルの訓練
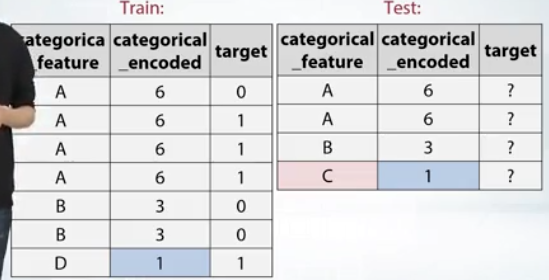
- テストデータにあって、学習データに存在しないようなカテゴリがある場合は、例えば学習データで頻度カテゴリを作成するなど、学習、テスト共通で使える項目を増やすのも手。
- -999,-1,etc
- まとめ
- 1.状況に応じて、欠損値を埋めるための方法を選ぶ。
- 2.-999や平均、中央値で置き換えるのがよく使われる。
- 3. また欠けている値は既に主催者によって何かに置き換えられます。
- この場合、値のない行を正確に知りたい場合は、ヒストグラムをブラウズして調べることができます。
- 4.バイナリフィーチャである、isnull項目が有益
- 一般に、フィーチャの有用性を低下させる可能性があるため、フィーチャ生成前に欠損値を置き換えることは避けてください。
- 5. そして最終的に、Xgboostは数字を直接扱うことができず、時にはスコアをより良く変えることができます。
テキストと画像からの特徴抽出
Bag of words
- テキストや画像を使ったコンペの紹介
- テキストの特徴量抽出
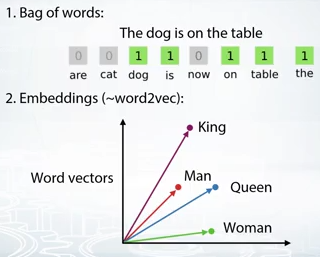
- bags of words
- sklearn.feature_extraction.text.CountVectorizer
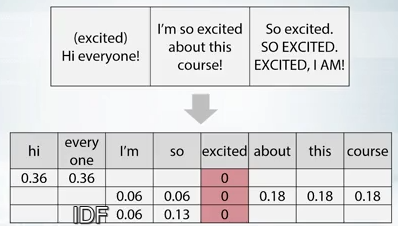
- TF(行内の合計が1になるように正規化)
- IDF

- sklearn.feature_extraction.text.TFidfVectorizer
- N-grams

- sklearn.feature_extraction.text.CountVectorizer:Ngram_range,analizer
- 小文字化
- sklearn configulizer
- レマティゼーション(同一意味を一つの表現にする)
- democracy, democratic, and democratization -> democracy
- ステミング(同一文字を抜き出す)
- democracy, democratic, and democratization -> democr
- ストップワード
- 前置詞のようにあまり意味のない単語
- sklearn.feature_extraction.text.CountVectorizer:max_df
- 単語の閾値
- まとめ
- テキスト前処理。
- 小文字、ステミング、字形化を適用するか、ストップワードを削除することができます。
- 前処理の後、bag of wordsアプローチを使用
- 各行がテキストを表す行列を取得し、各列は固有の単語を表すことができます。
- Ngramsの語彙アプローチと、いくつかの連続した単語や文字のグループの新しい列を使用することもできます。
- 最終的には、TFiDFを使用してこれらのメトリクスを後処理するときに役立ちます。
- さて、次に、抽出されたフィーチャを基本データフレームに追加するか、依存モデルを作成してトリッキーなフィーチャを作成することができます。
- テキスト前処理。

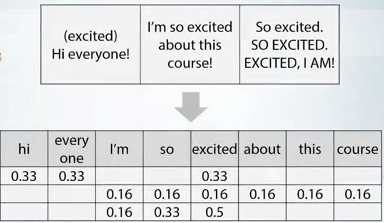
word2vec, CN
- word2vec
- 単語を数百次元のベクトルとして表現する。
- 学習に時間がかかる。ネットでモデルが存在するので使うとよい。
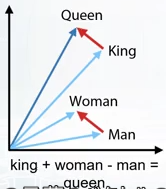
-

- 両方のアプローチを確認し、ベストを選択するようにした方が良い。
- BoW and w2v
- CNN
- ファインチューニング
- データ増強
- 回転
- まとめ
- 大きいベクトルとは何か?


最終的なプロジェクト
- 最終プロジェクトの概要
- 600万の学習データセット
- どの店のどのアイテムの売り上げを予測する。
- チームで行うことをお勧めする。
- ただし、チーム以外の人にコードを共有してはならない。(フォーラムなどで)