始めに
最近触っているCNTKパッケージですが、分散処理も行えるみたいです。
今まで分散深層学習をやってみたことはありませんでしたが、ドキュメントを見る限りでは
実装難易度が低そうで、簡単に並列計算ができそうな印象を持ちました。
https://docs.microsoft.com/en-us/cognitive-toolkit/Multiple-GPUs-and-machines
早速実装方法について上のドキュメントとサンプルコードを元に調査を行いましたので、
CNTKパッケージの分散処理の実装方法について解説しようと思います。
分散処理に必要な要素
CNTKで分散処理を実現するには、3つの要素が必要になります。
一つ目の要素は複数のプロセスを走らせるmpiexecコマンド、二つ目は複数のプロセス間の学習状況を管理するdistributedサブパッケージ、三つ目はdistributedを使う際に仕様上必要となるストリーム化したデータセット
になります。
mpiexec コマンド
mpiexecは、複数プロセスを走らせて並列処理を行うコマンドです。
Azureのデータサイエンス仮想マシン(NC12, OSはUbuntu 16.04)には、プリインストールされていました。
linux版のインストール方法はこちら
(1)単一ノード上で複数プロセスを走らせる場合
mpiexecの使い方は非常に簡単で、以下のように実行するだけです。
>>> mpiexec --npernode $num_workers ipython ConvNet_CIFAR10_DataAug_Distributed.py
$num_workersで実行するプロセス数を指定します。
(2)複数ノード上で複数プロセスを走らせる場合
今回は試していませんが、複数ノード上での並列処理も可能です。
ホストファイルを作成してmpiexecに渡すことで、指定したホストでプロセスが実行されます。
>>> mpiexec -hostfile $hostfile ipython ConvNet_CIFAR10_DataAug_Distributed.py
ホストファイルの書式は以下のようになります。
# Comments are allowed after pound sign
name_of_node1 slots=4 # we want 4 workers on node1
name_of_node2 slots=2 # we want 2 workers on node2
- name_of_node1(もしくはname_of_node2)には、DNS名かIPアドレスを記述します。
- slotsでは、各ノードで走らせるプロセス数を指定します。
distributed サブモジュール
distributedは並列学習を管理するサブモジュールであり、trainサブパッケージの下にあります。
まずは、サンプルコード ConvNet_CIFAR10_DataAug_Distributed.pyで、distributedサブモジュールが
どのように使われているのか見てみます。
if block_size != None:
parameter_learner = C.train.distributed.block_momentum_distributed_learner(
local_learner, block_size=block_size)
else:
parameter_learner = C.train.distributed.data_parallel_distributed_learner(
local_learner, num_quantization_bits=num_quantization_bits, distributed_after=warm_up)
# Create trainer
return C.Trainer(network['output'], (network['ce'], network['pe']), parameter_learner, progress_writers)
distributed.block_momentum_distributed_learner()1 か distributed.data_parallel_distributed_learner()
を使って、モデルパラメータのlearnerオブジェクトを作成し、Trainer()に引き渡しています。
後は、作成したtrainerオブジェクトをtraining_session()2に投げれば並列学習が実行されます。
(training_sessionを使用せず、for文を使った学習ループも可能です3)
training_session(
trainer=trainer, mb_source = train_source,
model_inputs_to_streams = input_map,
mb_size = minibatch_size,
progress_frequency=epoch_size,
checkpoint_config = CheckpointConfig(frequency = epoch_size,
filename = os.path.join(model_path, "ConvNet_CIFAR10_DataAug"),
restore = restore),
test_config = TestConfig(test_source, minibatch_size=minibatch_size)
).train()
学習が終了したら、以下のコードでMPIを閉じています。
distributed.Communicator.finalize()
データセットのストリーム化
先ほど、distributedでlearnerオブジェクトを作成しtraining_session()で学習させることを紹介しましたが、
これを実行するためには前処理済みのデータセットをMinibatchSource()でストリーム化する必要があります4。
サンプルコードでは、以下の部分に対応しています。
return C.io.MinibatchSource(
C.io.ImageDeserializer(
map_file,
C.io.StreamDefs(features=C.io.StreamDef(field='image', transforms=transforms), # 1st col in mapfile referred to as 'image'
labels=C.io.StreamDef(field='label', shape=num_classes))), # and second as 'label'
randomize=train,
max_samples=total_number_of_samples,
multithreaded_deserializer=True)
実験
サンプルコードを用いて、並列学習が機能しているかどうか実験してみます。
実験内容は非常にシンプルで、並列処理を行わない時(1 GPU)と並列処理を行った時(2 GPU)で
どの程度処理時間が変化するのか、比較します。
実験には、Azureのデータサイエンス仮想マシンNC12を1台使用しています。
実験環境
- 1 ノード、計 2 GPU
- ノード
- GPU:2 * NVIDIA Tesla K80
- CPU:12 * Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz
- ネットワーク
- Azure Network
- フレームワーク
- cntk v2.1
実験設定
- データセット:CIFAR10
- モデルのネットワーク構造:詳細はこちら
- 訓練
- 最適化手法:Momentum SGD
- 並列計算アルゴリズム:distributed.data_parallel_distributed_learner()
- バッチサイズ:64
- エポック数:20
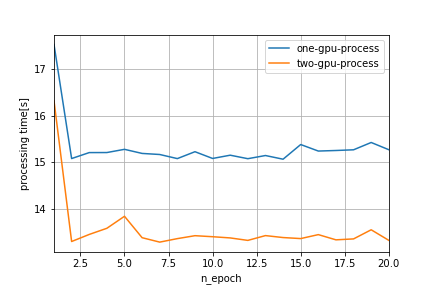
実験結果
エポック毎にかかる処理時間を比較してみたところ、計算に使用するGPUを1台増やすことで、
2秒程度短縮できていることが確認できました。
計算時のGPUステータス
(1)1GPUで計算した時のGPUステータス
>>> mpiexec --npernode 1 ipython ConvNet_CIFAR10_DataAug_Distributed.py &
>>> watch -n1 nvidia-smi
Every 1.0s: nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.48 Driver Version: 367.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 8E4D:00:00.0 Off | 0 |
| N/A 43C P0 71W / 149W | 64MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla K80 Off | 998D:00:00.0 Off | 0 |
| N/A 75C P0 90W / 149W | 323MiB / 11439MiB | 84% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 19734 C /anaconda/envs/py35/bin/python 62MiB |
| 1 19734 C /anaconda/envs/py35/bin/python 321MiB |
+-----------------------------------------------------------------------------+
(2)2GPUで計算した時のGPUステータス
>>> mpiexec --npernode 2 ipython ConvNet_CIFAR10_DataAug_Distributed.py &
>>> watch -n1 nvidia-smi
Every 1.0s: nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.48 Driver Version: 367.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 8E4D:00:00.0 Off | 0 |
| N/A 44C P0 118W / 149W | 371MiB / 11439MiB | 75% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla K80 Off | 998D:00:00.0 Off | 0 |
| N/A 67C P0 104W / 149W | 247MiB / 11439MiB | 72% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 42479 C /anaconda/envs/py35/bin/python 62MiB |
| 0 42480 C /anaconda/envs/py35/bin/python 307MiB |
| 1 42479 C /anaconda/envs/py35/bin/python 245MiB |
+-----------------------------------------------------------------------------+
以上
脚注
-
Block-Momentum SGDとはMSが開発した学習アルゴリズム。
リンク先のアブストしか読んでないが、それによると、従来の並列学習アルゴリズムよりも
高いスケーラビリティを実現できているらしい。 ↩ -
training_sessionモジュールは、学習ループを抽象化したもの。 ↩
-
MinibatchSource.next_minibatch()の引数 num_data_partitions、partition_index を設定する必要がある。 ↩
-
for文を使った学習でも、MinibatchSource()は必要になる。 ↩