導入
こんにちはhagurereです。
今回はtwitterを設計してみました。
要件
今回の要件は以下です。
- タイムライン(フォローしている人のtweet一覧)
- スレッド(tweet詳細とそのリプ一覧)
- いいね
考慮事項
- スケーラビリティ
- 機能拡張性(今後増える機能を予想して設計する)
RDBだけで設計してみる
以上の要件と考慮事項をもとに設計をしていきますがまず最初RDBだけで設計してみようと思います。
以下がざっと書いてみたE-R図です。
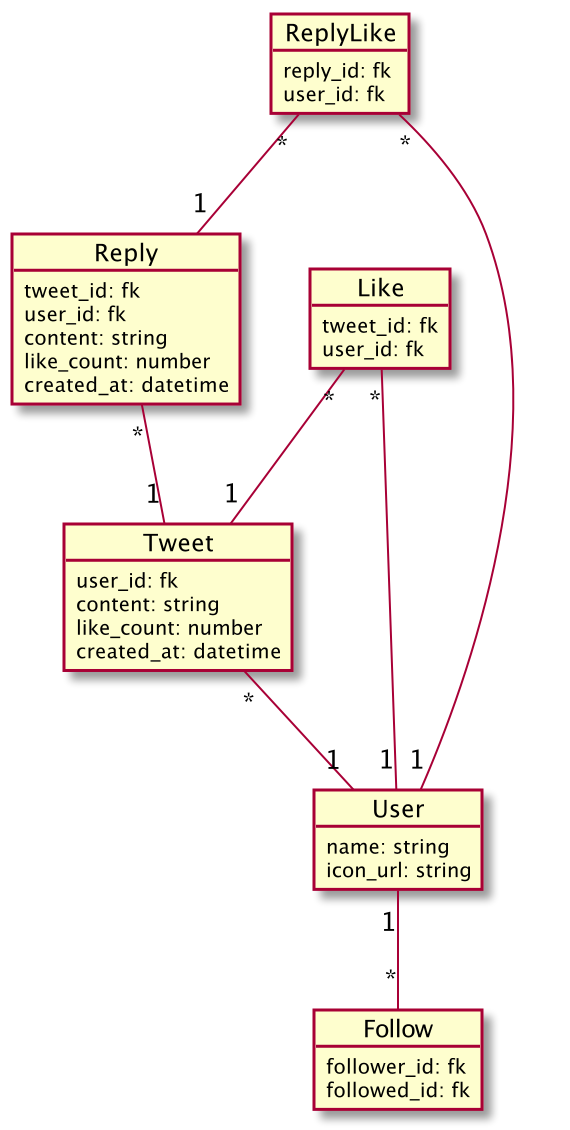
シンプルでわかりやすいDB設計ですね
このDB設計ですとタイムラインの一覧表示は以下のようなクエリで行うことができます。
SELECT *
FROM tweets
WHERE user_id
IN (SELECT followed_id
FROM follows
WHERE follower_id = ?)
ORDER BY created_at DESC
スレッドの表示だと以下
SELECT *
FROM replies
WHERE tweet_id = ?
ORDER BY created_at DESC
問題点
一見簡潔でよく見えますがこのDB設計、クエリですと以下のような問題点が出てきます。
- アクセスが増えるとサブクエリ(WHERE IN (SELECT ...))が重くなる
- リツイート, 引用リツイート, 広告ツイートなどを含めてタイムライン表示させるようにするときこのテーブル設計じゃ不可能
改善策
上の問題点を改善したDB設計にしてみました。
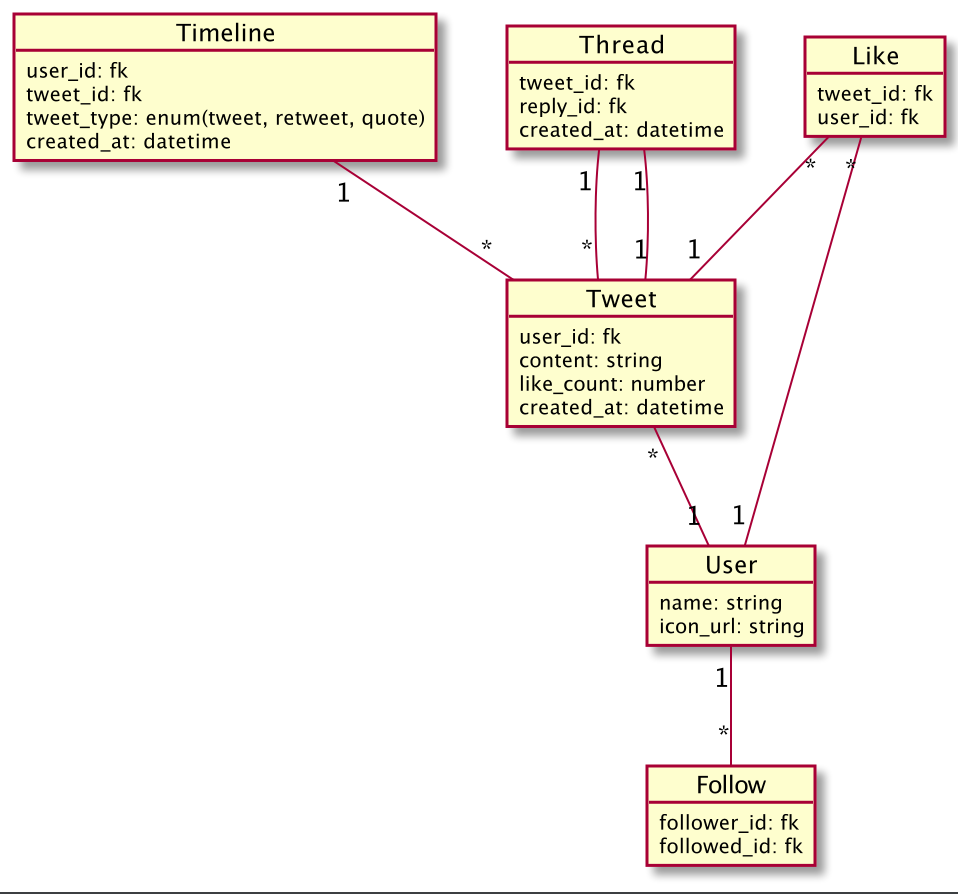
Tweetが作成されるたびにフォロワーの数Timelineテーブルにレコードを作成します
このようにすることでリツイート、引用リツイートに簡単に対応できますし以下のような軽いクエリでタイムライン一覧を取り出すことができます。
SLECT *
FROM timelines
INNER JOIN tweets
ON tweets.id = timelines.tweet_id
WHERE user_id = ?
ORDER BY created_at DESC
ただこちらにもデメリットはあります。
tweetの作成時フォロワーの数だけレコードを作成する。
つまり1000フォロワーなら1000レコード, 10000フォロワーなら10000レコード作成されてしまうということです。
NoSQL(DynamoDB)と組み合わせる
RDBに一気に何千, 何万レコードの作成はかなりのコストがかかりますが大量のデータを扱うように作られたNoSQLならそこまでのコストにせずに可能です。
twitterではmemcachedを使っている(使っていた?)ようですが今回はDynamoDBを使います
DynamoDBを使って最適化させたDB構成が以下です
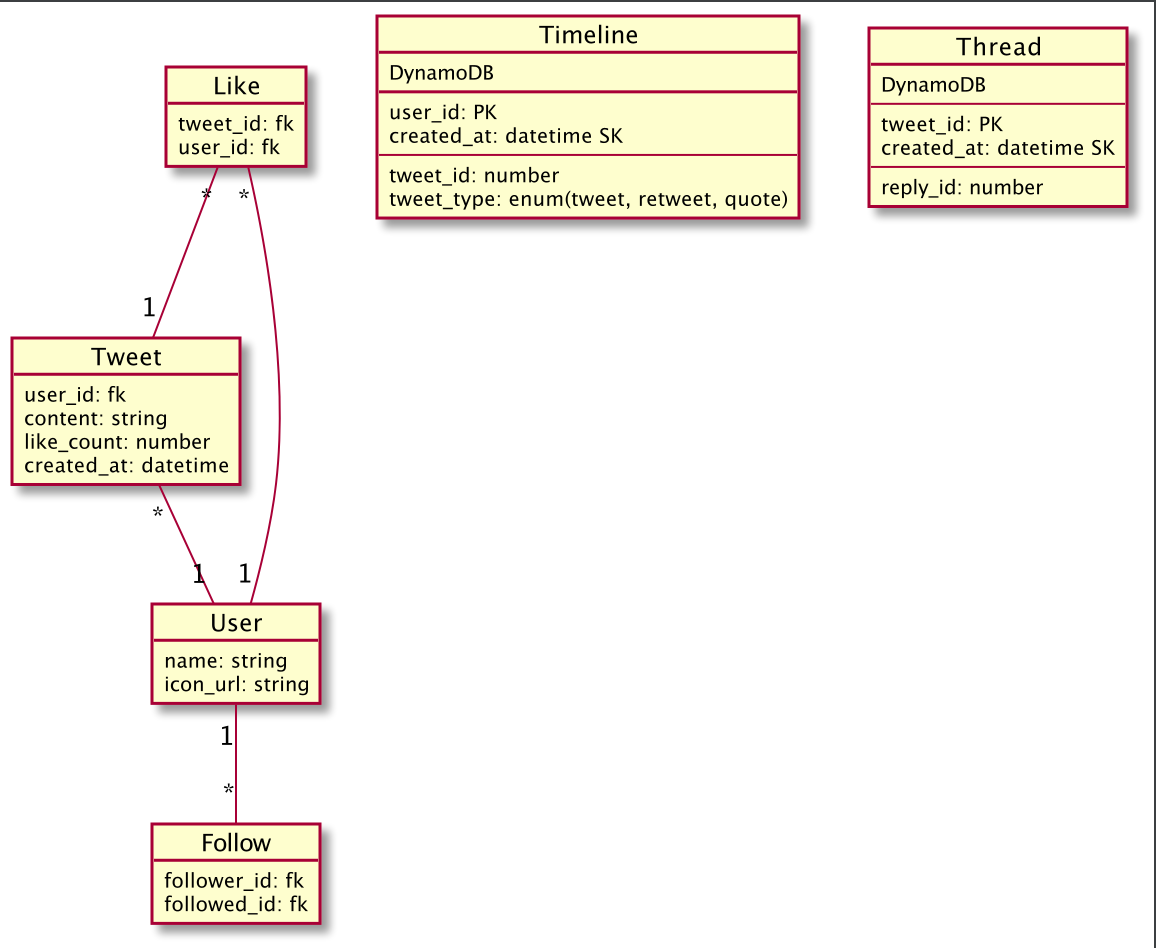
PKがパーティションキー, SKがソートキーです。
NoSQLにはリレーションがないので取り出したTimeline一覧にアプリケーション内でTweetをアタッチしてあげる必要がありますが最大30件程度ならそこまでコストにならないと思います。
最後に
実際のtwitterが今どのような構造で動いているかはわかりませんが10年前はこんな感じの構造で動いていたみたいです。
今はこんな感じじゃないのかとかここはこうしたらもっとよくないかとかのご指摘、ご質問があったらぜひ送ってください!