修正
get_crc32とget_md5が,数GBのファイルを渡した時にエラーを吐くので,修正しました.
背景
- ディスクで不良セクタが出ていたので,壊れたデータを見付けて原本から復元したい
- 忙しいので少しでも早い関数で比較したい
- データの破損チェックの方法 - Qiita などを見てみると,どうもHWやライブラリの実装に依存するんじゃないかという気がしてならない
- なので自分が処理する系で実際に測定した方が確実だよね!
方法
- ハンディカム付属ソフトで取り込んでいる関係上,ディレクトリ構成が異なるデータを比較する必要があり,面倒なのでpythonでループを回すことにする
- ハッシュ関数は上の記事を参考にCRC32かMD5に絞り込んだ
- サイズによっても処理速度が変わるようなので,サイズ別に比較する
- ランダムデータを作るのが面倒くさいので,実際にあるデータで試した
- 同じファイルを読み込んで実行速度を比較するので,ファイル読み込みのキャッシュが効かない1回目と効く2回目でフェアに比較できない
- じゃぁ比較の前にファイルを読み込んでしまへ
環境
| item | description |
|---|---|
| OS | Windows 10 Pro |
| lang | anaconda3-2018.12 (x64) for windows |
| IDE | JupyterLab 0.35.3 |
| HW | Intel NUC DC3217IYE (USB2.0) + external USB HDD |
ソース
import datetime
import doctest
import hashlib
import matplotlib.pyplot as plt
import os
import pandas
import zlib
bufsize = 1024*1024*10
def get_md5(filepath):
'''return md5sum of `filepath`
Parameters:
-----------
filepath : str
file path to calculate md5sum
Returns:
--------
md5sum : str
Example:
--------
>>> _ = open('test-get-md5.txt','w').write('hello world')
>>> get_md5('test-get-md5.txt')
'5eb63bbbe01eeed093cb22bb8f5acdc3'
'''
with open(filepath,'rb') as f:
buf = hashlib.md5()
while True:
fbyte = f.read(bufsize)
if not fbyte:
break
buf.update(fbyte)
return buf.hexdigest()
# doctest.testmod()
def get_crc32(filepath):
'''return crc32 of `filepath`
Parameters:
-----------
filepath : str
file path to calculate crc32
Returns:
--------
crc32 : str
Example:
--------
>>> _ = open('test-get-crc32.txt','w').write('hello world')
>>> get_crc32('test-get-crc32.txt')
'0xd4a1185'
'''
with open(filepath,'rb') as f:
buf = 0
while True:
fbyte = f.read(bufsize)
if not fbyte:
break
buf = zlib.crc32(fbyte, buf)
return hex(buf)
# doctest.testmod()
columns = ['size','md5','crc32']
data = []
dirname = 'D:\\Pictures\\Videos\\2018-10-06'
for f in os.listdir(dirname):
print(f)
testfile = f'{dirname}\\{f}'
_ = open(testfile,'rb').read() # ファイルを一度読み込んでおく
t0 = datetime.datetime.now()
get_crc32(testfile)
t1 = datetime.datetime.now()
get_md5(testfile)
t2 = datetime.datetime.now()
data.append(
(os.stat(testfile).st_size/1024/1024,
(t2-t1).seconds + (t2-t1).microseconds/10**6,
(t1-t0).seconds + (t1-t0).microseconds/10**6)
)
df = pandas.DataFrame(data, columns=header).set_index('size').sort_index()
df.plot(figsize=[16,9])
plt.show()
結果
実際はJupyterLabで実行したので,途中でdfを出力したりして確認している.
| size [MB] | md5 [sec] | crc32 [sec] |
|---|---|---|
| 15.37500 | 0.078123 | 0.046876 |
| 16.31250 | 0.062501 | 0.062499 |
| 20.25000 | 0.085988 | 0.062503 |
| 29.06250 | 0.124991 | 0.093748 |
| 32.15625 | 0.140618 | 0.109371 |
| 52.96875 | 0.234371 | 0.171864 |
| 95.15625 | 0.455127 | 0.312490 |
| 97.40625 | 0.406245 | 0.343737 |
| 107.53125 | 0.453120 | 0.359362 |
| 110.15625 | 0.484318 | 0.359372 |
| 118.50000 | 0.499991 | 0.328117 |
| 127.21875 | 0.531234 | 0.406247 |
| 166.68750 | 0.698429 | 0.531236 |
| 235.59375 | 1.021666 | 0.792377 |
| 266.90625 | 1.093727 | 0.925919 |
| 268.40625 | 1.099131 | 0.825174 |
| 344.90625 | 1.453075 | 1.046859 |
| 380.53125 | 1.562470 | 1.137611 |
| 388.31250 | 1.593721 | 1.219517 |
| 388.59375 | 1.570866 | 1.188309 |
| 1938.37500 | 66.921877 | 65.280923 |
| 2026.50000 | 73.078747 | 72.051399 |
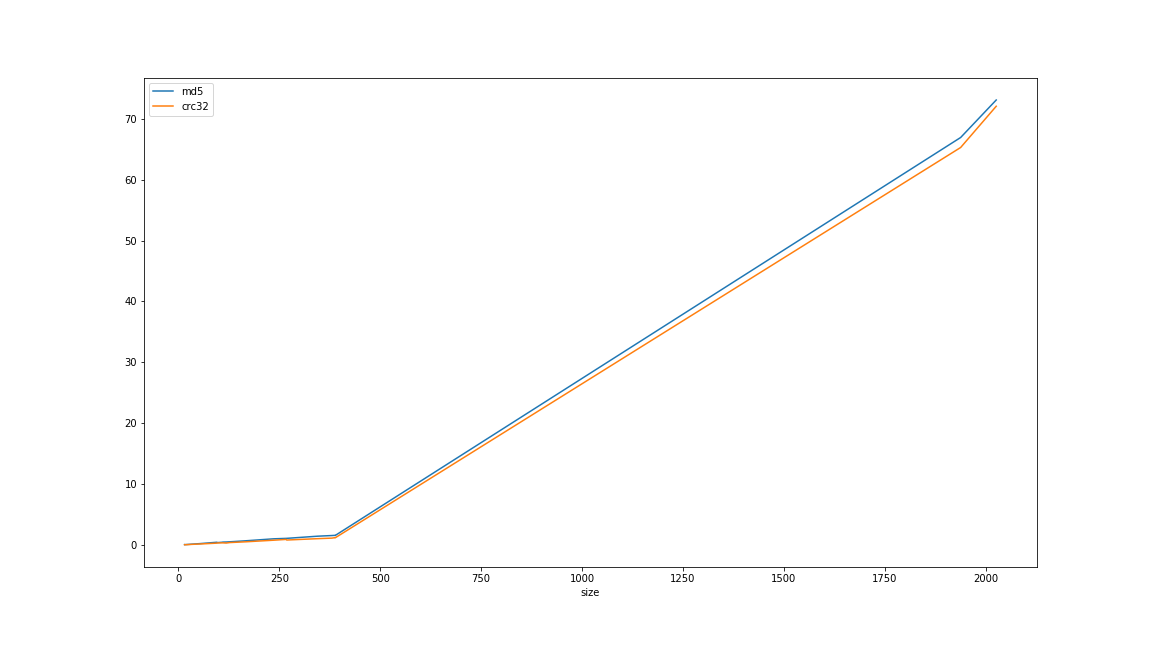
結論
時々md5がcrc32に肉薄するけど,誤差の範囲.
っていうかどっち使ってもあんま変わんねーな.
そんで,この検証する時間があれば,全部チェック終わってただろうっていう.