Weblioポップアップ英和辞典が便利だったのでテキストエディタでもこんな機能があったらなぁと思って作ってみました。
Weblioポップアップ英和辞典は↓みたいな感じで辞書の検索結果を表示してくれます。
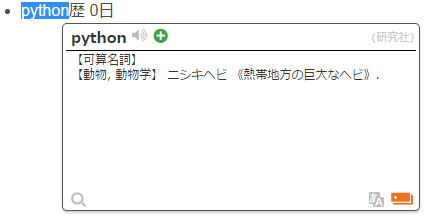
上の例では検索したい単語を反転させてますがマウスオーバーだけで表示する設定もあります。
目指した機能
- ドラッグで選択した英単語の翻訳結果を表示。
- ショートカットで動作(選択しただけで表示させるとコーディングしづらいのため)
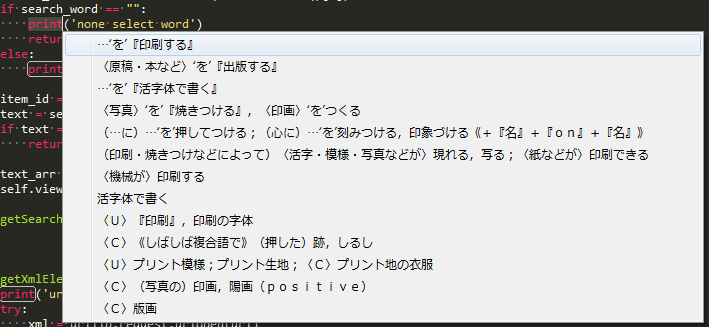
こんな感じになりました。
環境
- Windows7 64bit
- SublimeText3
- python歴 0日
参考にしたサイト
- sublime-text3を使いはじめたのでプラグインも作ってみた
- 英和・和英辞書APIのデ辞蔵を呼び出すRubyコードのサンプル
- Sublime Text API Reference(翻訳)
- Pythonで名前空間付きのXMLを操作する(ElementTree)
コード
# coding=UTF-8
import sublime, sublime_plugin
import urllib.request
import xml.etree.ElementTree as ET
class popTranslateEnglishIntoJapaneseCommand(sublime_plugin.TextCommand):
def run(self, edit):
search_word = self.view.substr(self.view.sel()[0])
if search_word == "":
print('none select word')
return
else:
print(search_word)
item_id = self.getItemID(search_word)
text = self.getTranslatedText(item_id)
if text == '':
return
text_arr = self.splitTranslatedText(text, '\t')
self.view.show_popup_menu(text_arr, None)
def getXmlElementText(self, url, tag):
print('url : ' + url)
try:
xml = urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print('error code : ' + str(e.code))
print('error read : ' + str(e.read()))
return ''
print(xml)
tree = ET.parse(xml)
root = tree.getroot()
element = root.find('.//{http://btonic.est.co.jp/NetDic/NetDicV09}' + tag)
text = element.text
print(text)
return text
def getItemID(self, search_word):
head = 'http://public.dejizo.jp/NetDicV09.asmx/SearchDicItemLite?Dic=EJdict&Word='
end = '&Scope=HEADWORD&Match=EXACT&Merge=OR&Prof=XHTML&PageSize=20&PageIndex=0'
url = head + search_word + end
return self.getXmlElementText(url, 'ItemID')
def getTranslatedText(self, item_id):
head = 'http://public.dejizo.jp/NetDicV09.asmx/GetDicItemLite?Dic=EJdict&Item='
end = '&Loc=&Prof=XHTML'
url = head + item_id + end
return self.getXmlElementText(url, 'Body/div/div')
def splitTranslatedText(self, translated_text, split_word):
return translated_text.split(split_word)
何をしたか?
-
まずはパッケージの作り方を検索
下のリンク先で基本的な作り方を学習。
sublime-text3を使いはじめたのでプラグインも作ってみた
ついでになんとな~くpythonの記述を理解した気になる。 -
どうやって翻訳するか・・・
最初はWeblioのAPIを探したのですが見つけられませんでした。
そのうち下記のリンク先でデ辞蔵というとこで翻訳できるらしいことを発見。
英和・和英辞書APIのデ辞蔵を呼び出すRubyコードのサンプル
どうやらURL内に検索したい英単語やパラメータを関数のように記述することで翻訳結果のXMLが返ってくるらしい。
その返って来たXMLを解析して翻訳結果を取得、といった感じ。
しかし、サンプルはRubyなのでどうやってpythonで実現するか・・・ -
urllibとxml.etree.ElementTree
この二つのライブラリを使うことで実現できそう。
urllibでURLにアクセスしたときのデータを取得、今回はXMLファイルが取得できます。
xml.etree.ElementTreeで取得したXMLを解析という流れ。
それぞれのライブラリの使い方はググればたくさん出てきます。 -
手間取った箇所
-
getXmlElementTextメソッドで使っているurllib.request.urlopen
pythonのバージョンによってurllib.request.urlopenだったり、urllib.urlopenになるらしい。importの単語も変わるかも? -
XMLに名前空間がありタグの検索に失敗
findメソッドに検索したいタグを渡すと子要素を返してくれます。
ただし名前空間があると名前空間をタグに付けなくてはダメなようです。element = root.find('.//{http://btonic.est.co.jp/NetDic/NetDicV09}' + tag)ここで要素を取得してますが'{}'で囲った部分が名前空間になります。
詳しくは Pythonで名前空間付きのXMLを操作する(ElementTree) へ
ちなみに'.//'をつけると子要素だけでなく孫要素以降も検索できます。
- 最後に
初めてパッケージを作りましたが1日で出来るほど簡単でした。
GitHubは登録してるけどリポジトリはありません。気が向いたら作ります。