はじめに
ClusterNet: Detecting Small Objects in Large Scenes by Exploiting Spatio-Temporal Informationを読みました。
https://arxiv.org/pdf/1612.03144.pdf
Abstract
物体検出タスクの一つの分野としてwide area motion imaginary(WAMI)というタスクがある。
WAMIとは検出をしたい物体が以下のような性質を持っている時の検出タスクをいう。
- 物体が極端に小さい
- 物体がある部分に密集している(sparse and densely-packed objects)
- 動画の一つのフレームに対して検索するエリアが広い
WAMIタスクに対して既存のappearance-based classifierモデルは十分に高い精度出せていなく、ほとんどは背景差分を利用した情報抽出に依存してしまっている。
本論文ではR-CNNのようなappearance-basedな手法とfully convolutional neural networksのようなheatmap-basedな手法がWAMIタスクに対して高精度を出すのが難しいことを検証し、appearanceとmotion情報を組み合わせた2stageCNNモデルを提案している。
データセット
WAMIタスクのデータセットの一つであるWPAFBは以下のような画像がある。

このような画像が連続で撮影した動画がデータセットとして提供されている。
画像サイズとしても大きく、かつ検出した物体が密集しているのがこのデータセットの特徴である。
一般的なObject Detectionタスクで利用されるCOCO datasetやPASCALVOC datasetなどと比較したのが以下の表である。
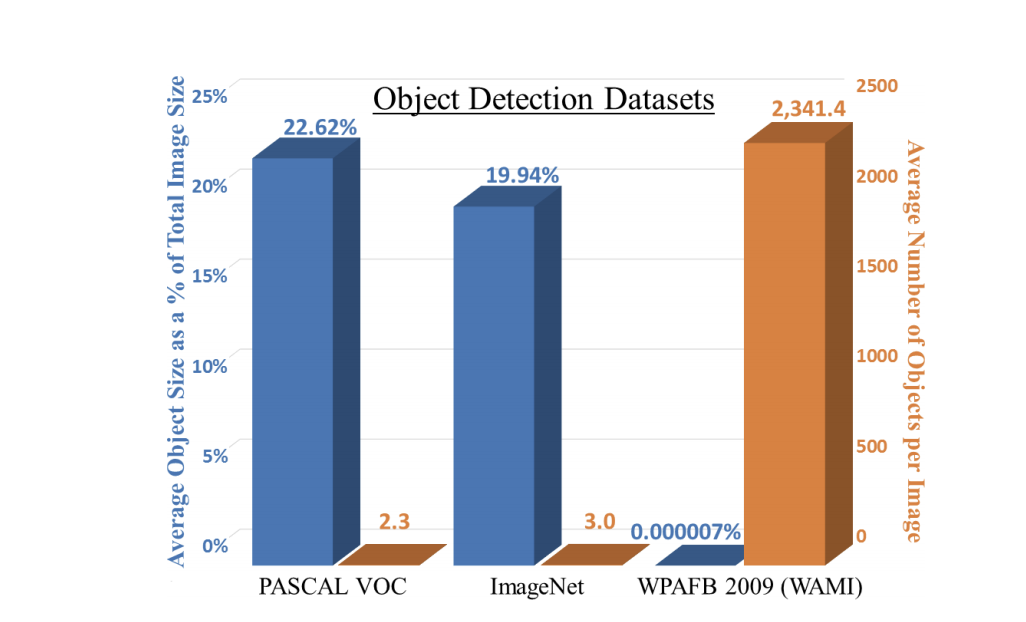
表のとおり画像サイズに対しての物体の領域がかなり小さく、さらに1枚の画像に対してのオブジェクトの数が圧倒的に多い。
既存手法の問題点
このようなデータセットにたいしてYOLOやR-CNNのような1フレームに対して検出を行うAppearance Basedなモデルでは高い精度を達成できず、SOTAは動画の性質を利用した背景差分抽出手法を利用したモデルである。
背景差分抽出は入力されたビデオフレームと事前に用意した背景画像との差分を抽出することにより動いている物体のみを抽出する手法。
背景画像は一般的にすべての動画フレームのピクセルごとのMedianを計算することによって背景を抽出するが、この手法では計算量が多くなってしまう。
提案手法
CusterNetはApperance Basedのモデルをビデオフレームのような時系列情報を考慮したモデルとなっている。
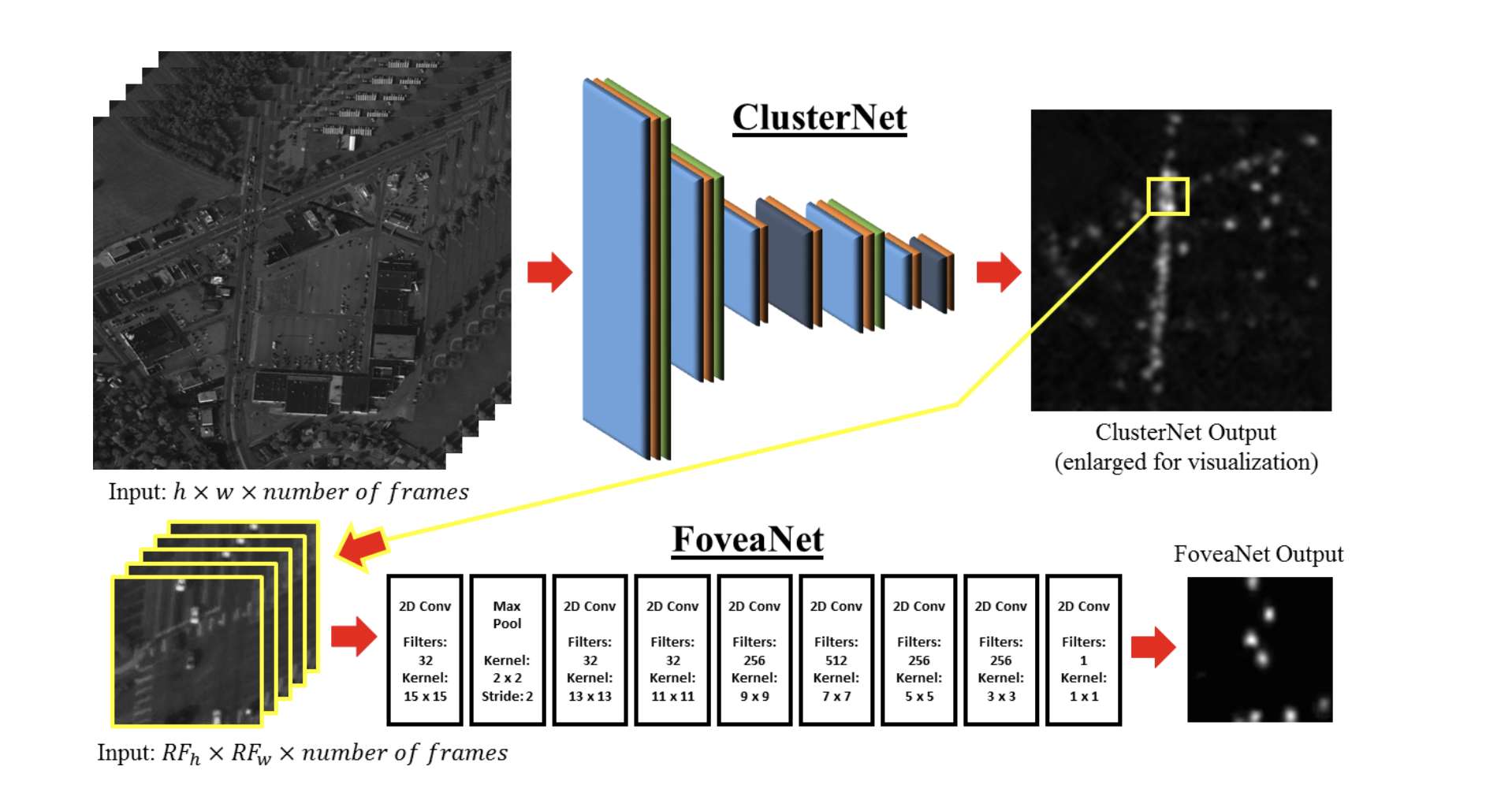
ClusterNetはClusterNetとFoveaNetの2つのモデルから構成されている。
ClusterNet
ClusterNetの目的は**ROOBI(regions of objects of interests)**という物体がありそうな領域を抽出するためのモデルである。
WAMIタスクのデータセットは画像サイズが大きいため探索範囲を絞込んでからFoveaNetで物体検出を行うことで計算量を減らすことができる。
またClusterNetでは前後フレームを考慮するために入力は1フレームではなく複数フレームを入力できる構造となっている。
Convolutionの計算をいかに示す。
$$f_{x, y}^{m}=\sum_{n=1}^{N}\left[\sum_{i=1}^{k_{h}} \sum_{j=1}^{k_{w}} V_{n}(i, j) \times K_{n}\left(k_{h}-i, k_{w}-j\right)\right]+b_{m}$$
DensityMap
データセットでは検出したオブジェクトの領域が極端に小さくてほぼ点に近い状態・オブジェクトが密集している。
ClusterNetでは密集している部分を抽出したというモチベーションもあるため、本モデルでは出力にはDensityMapというものを利用している。
DensityMapは物体のある座標を中心にGaussian Heatmapをかけることで生成する。
これにより物体が密集しているところはHeatMapが高くなる。
DensityMapは以下の式を利用して生成する。
$$H=\sum_{n=1}^{N} \frac{1}{2 \pi \sigma^{2}} e^{-\frac{\left(x / 2^{d}\right)^{2}+\left(y / 2^{d}\right)^{2}}{2 \sigma^{2}}}$$
学習はMSEをLossとして定義をして学習を行う。
FoveaNet
FoveaNetはClusterNetにより出力されたheatmapがある程度高い部分を抽出して入力してより細かなDensityMapを出力させる。
ClusterNetは大きな画像から物体がある領域を抽出するモデルに対して、FoveaNetはより細かく物体を検出するモデルとなっている。
検証
Faster-RCNN・差分抽出を利用したモデルと入力するフレーム数を変更したClusterNetを比較した。
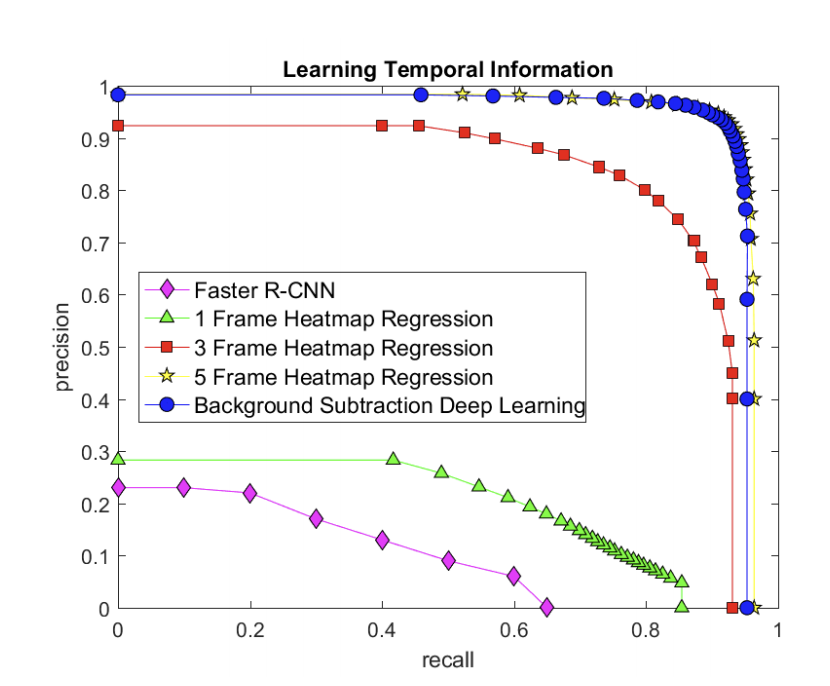
結果を見るとSOTAのモデルとほぼ変わらない結果となっている。
またフレームを増やすことで精度が上がっていることがわかる。
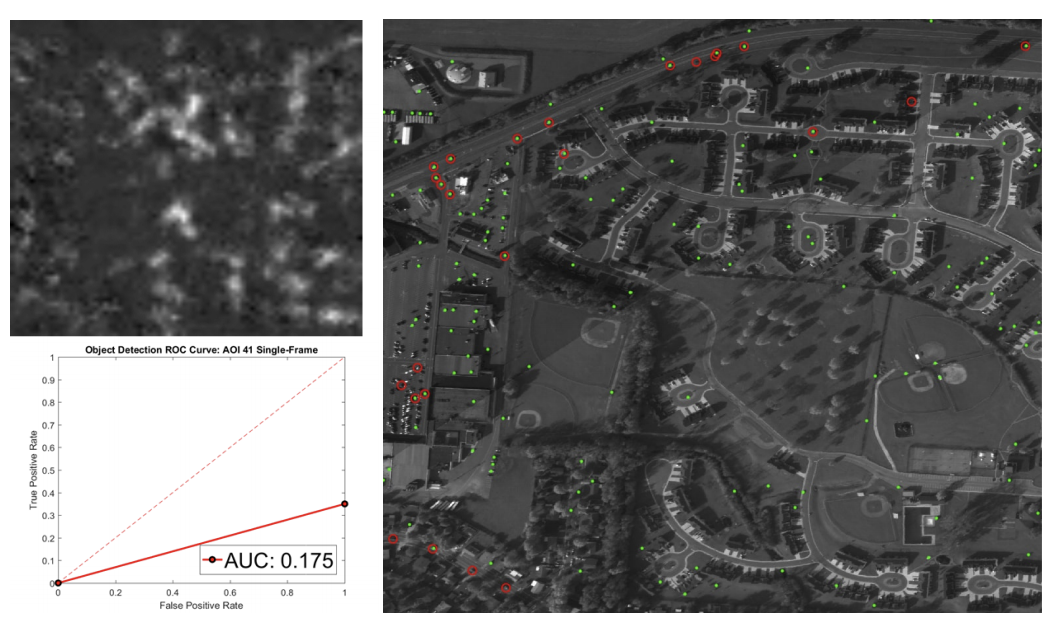
1フレーム入力の結果
3フレーム入力の結果
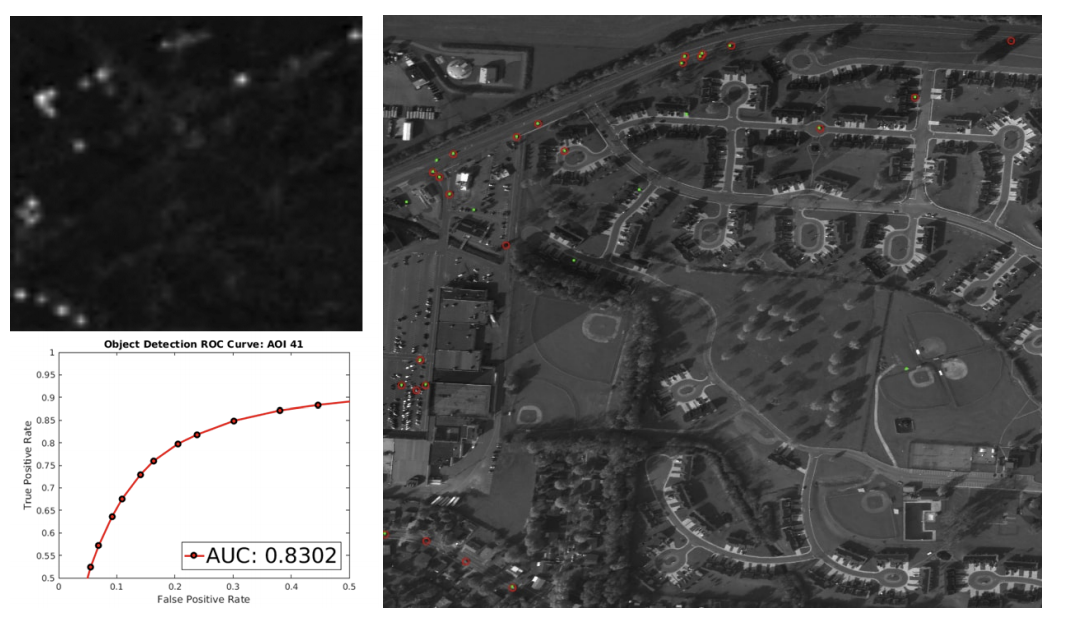
5フレーム入力の結果
