概要
本コンテンツは、JAWS DAYS 2017のIoTハンズオン向けに作成したもので、前編の続きとなるコンテンツです。
前編に引き続き、構築するデータフローは以下の通りです。
温度センサー -> RaspberryPi -> Kinesis Firehose -> S3 -> Athena -> QuickSight
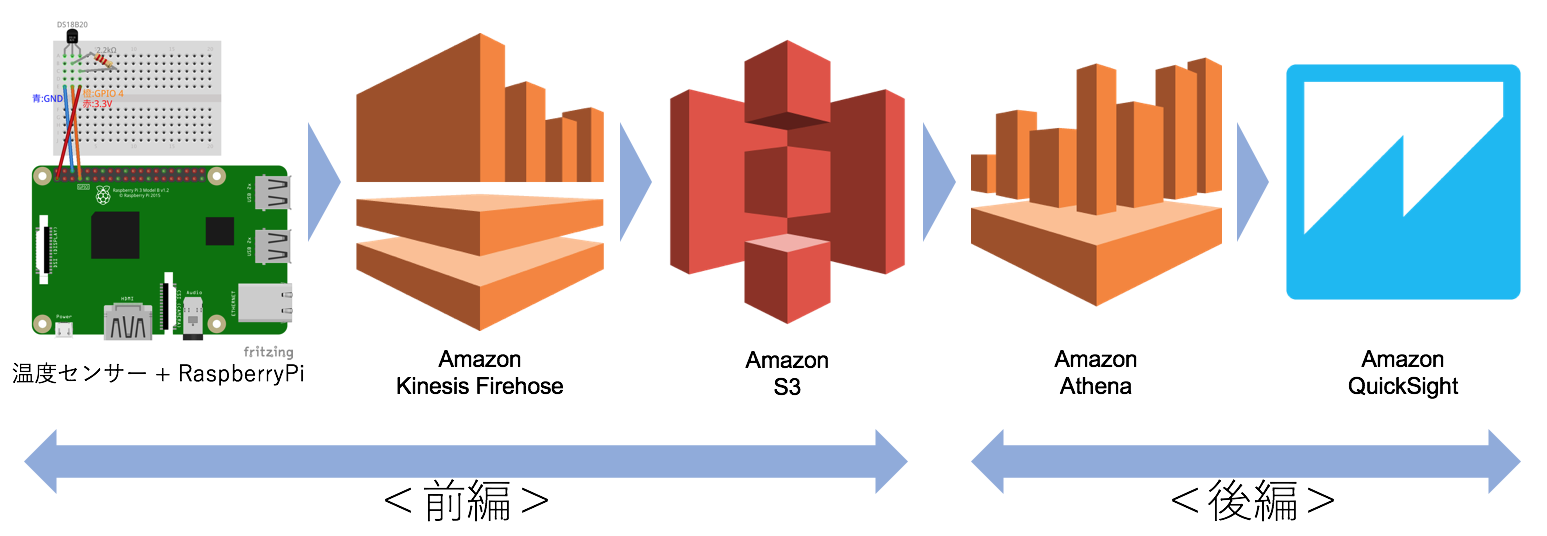
<後編>の範囲
<後編>では、S3 -> Athena -> QuickSight の部分を説明します。成功すればグラフィカルな画面でセンサーデータを可視化する事ができます。
必要な機材
- PC
- 前編で構築済みのRaspberryPi 2または3
前提条件
- 前編の手順が完了している事
<後編>で利用するAWSサービス
Amazon Athena
Amazon S3内のデータをSQLを使って分析できるサービスです。サーバーレスなサービスなため、セットアップや管理は不要、すぐに即座にデータ分析を開始できます。データをAthenaにロードする必要は無く、S3に保存されているデータと直接連携できます。
CSV、JSON、Apacheログなど様々な形式を扱う事ができます。QuickSightと統合する事で簡単に可視化する事ができます。
- GZIP等の圧縮ファイルも読み込める
- JDBC経由でのアクセスも可能
- 検索した結果がS3に保存される
- 実行したクエリに対して課金
- 東京リージョンでは使えない(2017年2月時点)
Amazon QuickSight
AWSが提供する高速なBIサービスです。データソースとして、ファイル、S3、RDS、Redshift、Salesforceなどが使え、昨年12月にはAthenaに対応しました。
インメモリ処理に最適化されたデータベースである「SPICE」(Super-fast Parallel In-memory Calculation Engine)にデータをインポートする事で、高速な分析ができるようになっています。
作成したグラフはモバイルからの閲覧にも対応しています。
- 東京リージョンでは使えない(2017年2月時点)
- 利用するアカウント数やSPICEの容量で課金
- 60日間の試用期間、無料枠もある(1ユーザー、SPICEは1GBまで)
[ToDo 8] Amazon Athenaを設定する
Amazon Athenaにテーブルを作成し、S3を参照できるようにします。
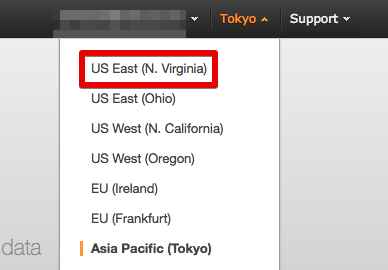
- Athenaコンソールを開く

* Amazon Athenaは2017年2月現在、東京リージョンでは提供されていないので、利用可能な北バージニア(N.Virginia)リージョンを選択する
* [Get Started]をクリックする

* Tutorialが表示されたら×で閉じる

サンプルデータベースを使ったクエリの試行
Athenaにはサンプルデータ(Elastic Load Balancingのログ)が用意されているので、こちらを使ってクエリの実行を試してみます。
- Query Editorの画面でDATABASEに「sampledb」が選択された状態で、以下のクエリを入力し、「Run Query」をクリックする
SELECT * FROM elb_logs limit 100;
- 数秒待つと画面下部に実行結果が表示される
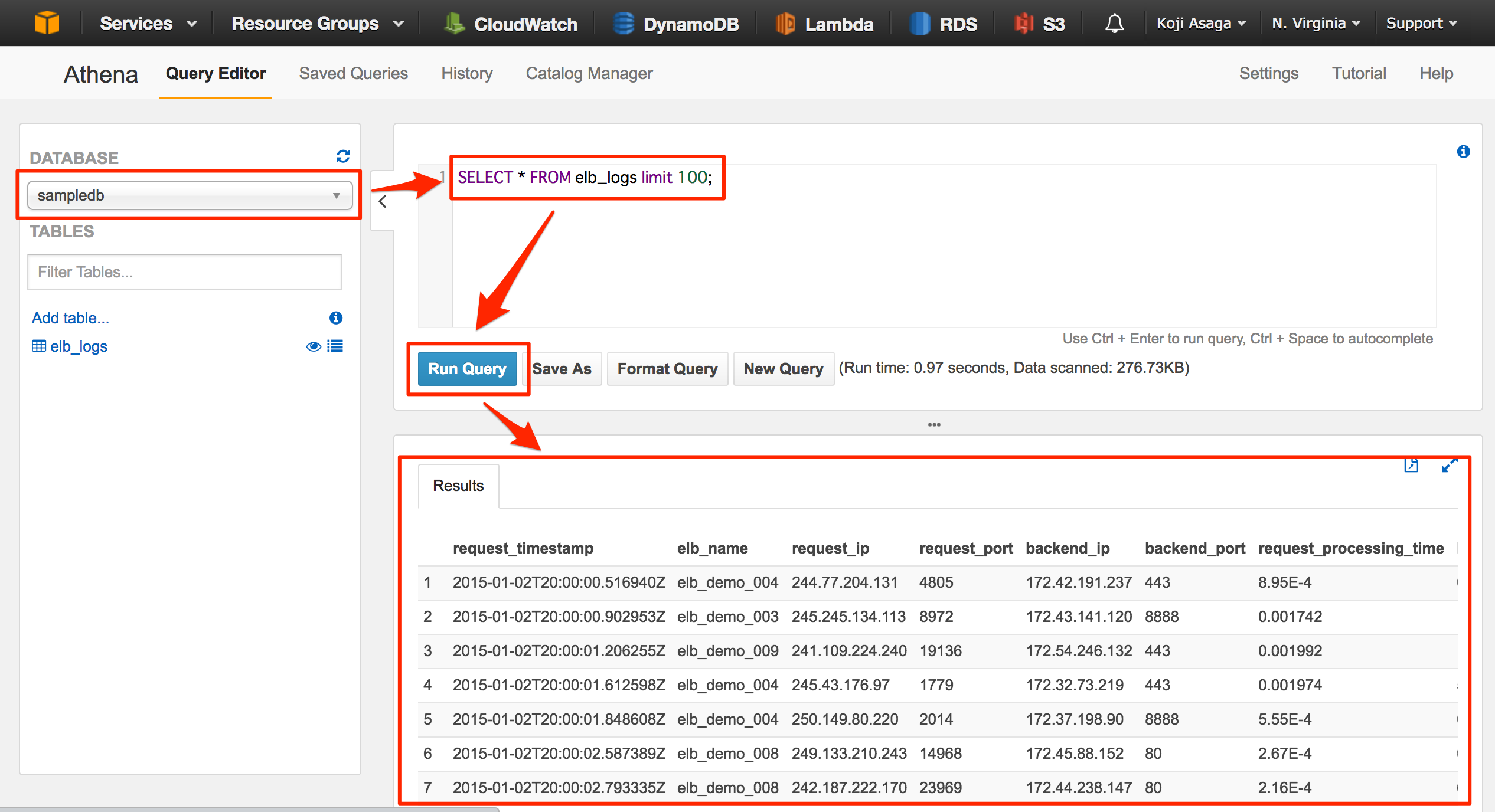
- 実行した結果はCSV形式でS3に保存される
- その他の実行例
SELECT backend_response_code, count(*) FROM elb_logs GROUP BY backend_response_code ORDER BY backend_response_code;
SELECT count(*) AS C, url FROM elb_logs GROUP BY url ORDER BY c desc;
データベースとテーブルの作成
- Query Editorの画面で「Add table...」をクリックする

Name & Location
データベースとテーブルの名前、S3のパスを指定します。
- Databaseに「Create new database」を選択された状態で、データベース名を入力する(ここでは「jawsdays2017」としている)
- Table Nameに任意のテーブル名を入力する(ここでは「sensor」としている)
- Location of Input Data Setには、前編で作成したセンサーデータが格納されるS3のパスを入力する。今回の場合は、
s3://バケット名/YYYY/MM/DD/HH/ファイル名となるため、パスとして固定なs3://バケット名/を設定する。(バケット名は、スクリーンショットでは「jaws-days-2017-iot-handson」となっているが、前編では「iotan-f」として作成しているので注意)
- 全て入力したら「Next」をクリックする。

Data Format
S3に格納されているデータのフォーマットを設定します。
- 「JSON」を選択して「Next」をクリックする

Columns
S3のデータに合わせて、Athenaのテーブルにカラムを追加します。
- センサーから送信されるJSONデータはtimeとtemperatureのため、それぞれのカラムを追加する
- 「Add a column」をクリックすると、入力エリアを増やす事ができる
- 2カラム分の情報を入力したら、「Next」をクリックする

Partitions
- 今回は省略して、「Create table」をクリックする
- Query Editorに戻り、「Query successful.」と表示されたら完了

[ToDo 9] Amazon Athenaでクエリを実行する
[ToDo 8]と同様の手順で、SQLを発行してS3上のログファイルが参照できるか確認してみます。
- Query Editorに以下のクエリを入力し、「Run Query」をクリックする
(左側の眼のアイコンをクリックしても同じクエリを実行できる)
SELECT * FROM sensor limit 10;

画面下部に結果が表示されるので、ご自分の環境で確認してみてください。
検索結果がCSVファイルとしてS3に保存される事も確認してみましょう。
[ToDo 10] QuickSightのアカウントを作成する
QuickSightを使う場合、最初にアカウントの登録が必要となります。
- QuickSightコンソールを開く

* QuickSightを利用開始する前の場合、以下のような画面が表示されるため、「Sign up」をクリックする

* [Standatd edition]が選択された状態で、「Continue」をクリックする 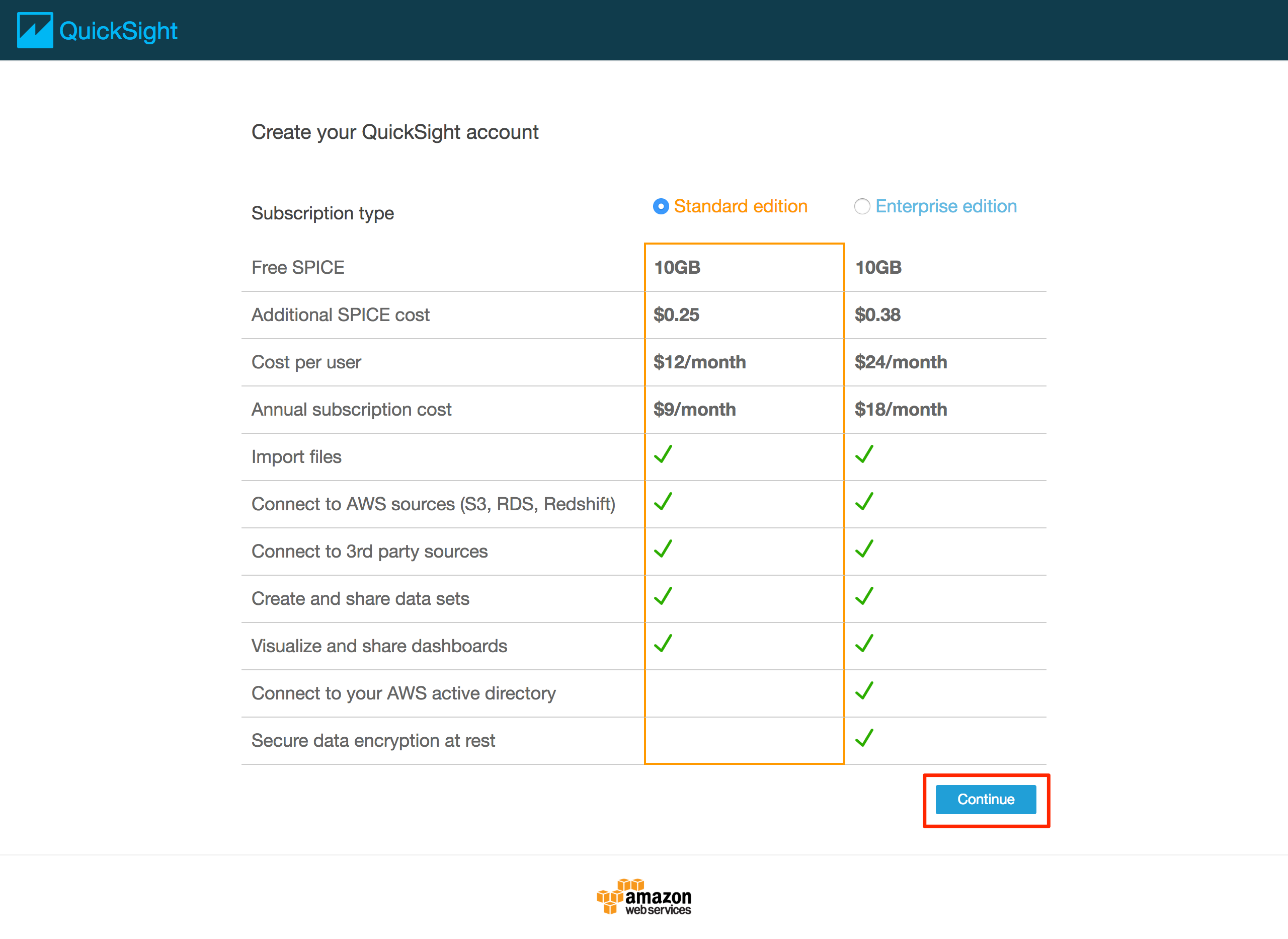
* アカウントの作成に必要な情報を入力し、「Finish」をクリックする 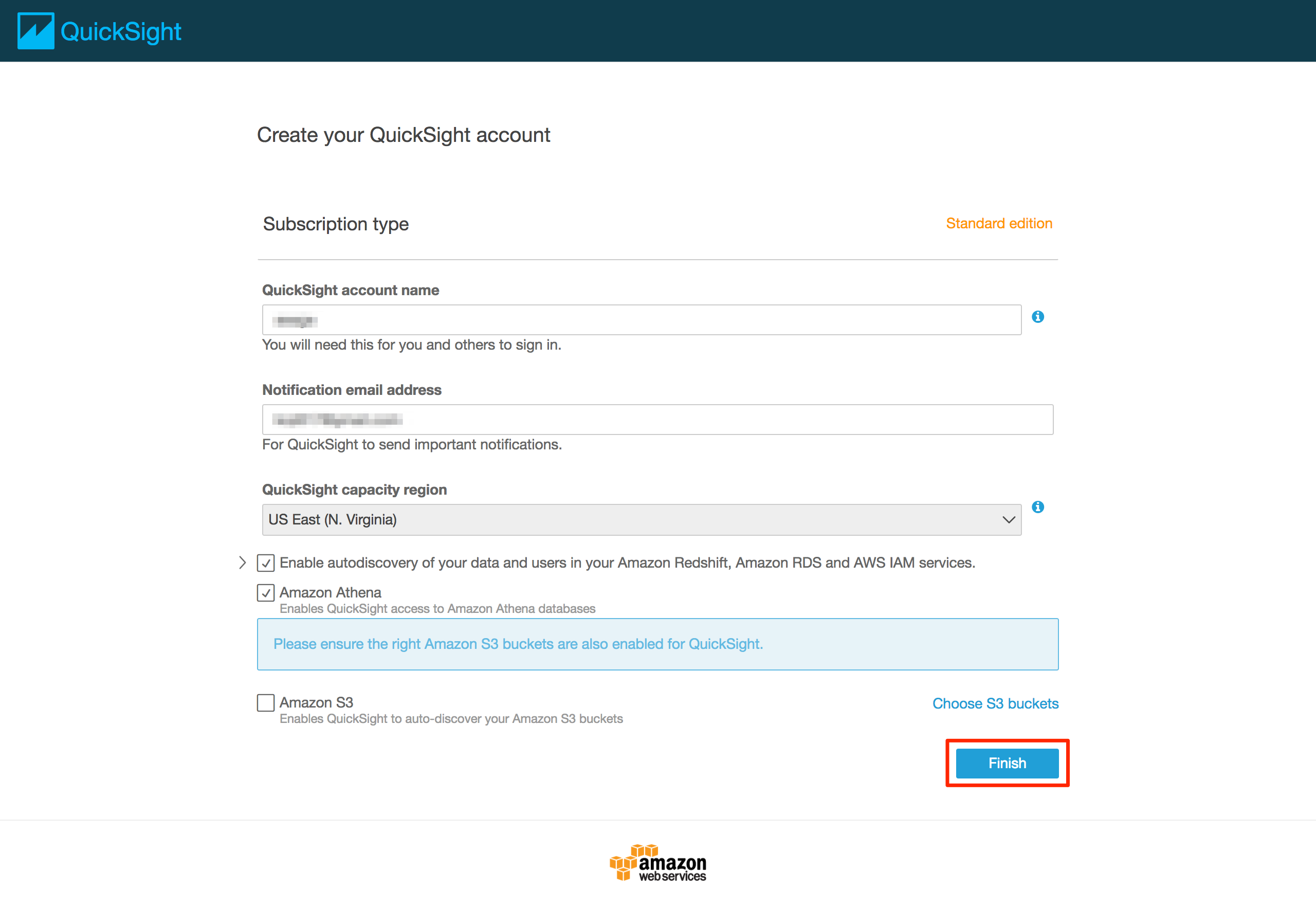
- 「Create your QuickSight account」が表示されたらアカウントの作成が完了したので、「Go to Amazon QuickSight」をクリックする
[ToDo 11] Amazon QuickSightのデータセットを作成する
データソースから必要な部分を取り出して、データセットを作成します。データセット作成時に前述のSPICEに取り込むか選択する事ができます。
データセットのデータを整形できる「Prepare」により、不要な列の削除・列名の変更、計算フィールドの設定、ジョイン、カスタムSQLなどが可能です。
QuickSightに対してS3バケットへの権限を追加する
- これを実施しないと、データセットの作成時に以下のエラーが発生する

* 右上のアイコンから[Manage QuickSight]をクリックする

* 「Account setting」を開き、「Edit AWS permissions」をクリックする

* 「Choose S3 buckets」を選択し、該当のバケットにチェックを入れてから「Select buckets」をクリックする(その後の画面で「Apply」をクリックする)


データセットを作成する
- 以下の画面では作成済みのAnalysis(分析画面)を選択できる。今回は 「Manage data」をクリックする

* 以下の画面では作成済みのデータセットを選択できる。 「New data set」をクリックする

* データセットを作成するためのデータソースを選択する。ここでは「Athena」を選択する

* Data source nameを入力し、「Create data source」をクリックする

* Databaseのプルダウンから、事前に作ったAthenaデータベースを選択し、「Select」をクリックする

* 最後にAthenaのデータをSPICEにインポートするか、直接クエリを実行するか選択する。ここでは「Import to SPICE for quicker analytics」を選択し、「Visualize」をクリックする
 **注意**
**注意*** [AWSのドキュメント](http://docs.aws.amazon.com/ja_jp/quicksight/latest/user/importing-data-to-spice.html)によると「AthenaはSPICEへのインポートに未対応」となっていますが、実際の挙動はインポート可能となっています。 * AWSのドキュメントより抜粋 * You can improve the performance of database data sets by importing the data into SPICE instead of using a direct query to the database (with the exception of Amazon Athena data sets, which currently only support direct query). * データベースへの直接クエリを使用するのではなく、データをSPICEにインポートすることで、データベースデータセットのパフォーマンスを向上させることができます(現在、直接クエリのみをサポートするAmazon Athenaデータセットを除く)。
* Analysisの画面でImport completeが「100% success」になったらSPICEへのデータインポートが完了した事になる

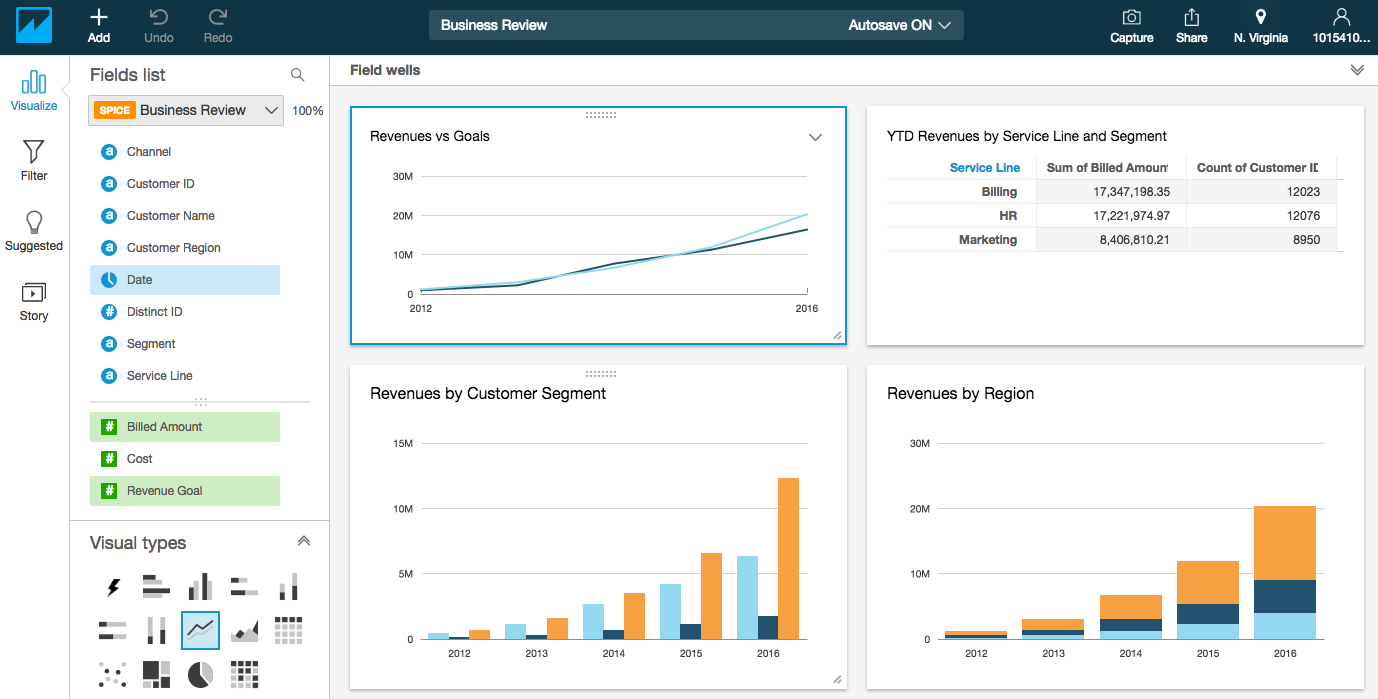
[ToDo 12] Amazon QuickSightのAnalysisを作成する
- ここでは時間ごとの温度平均値を折れ線グラフで表示します
フィールドを配置する
- Visual typesの「Line chart」を選択する

* X軸に表示するデータを指定するため、Fields listの「time」をクリックする(「time」をField wellsの「X axis」にドラッグ&ドロップしても同じ事ができる)

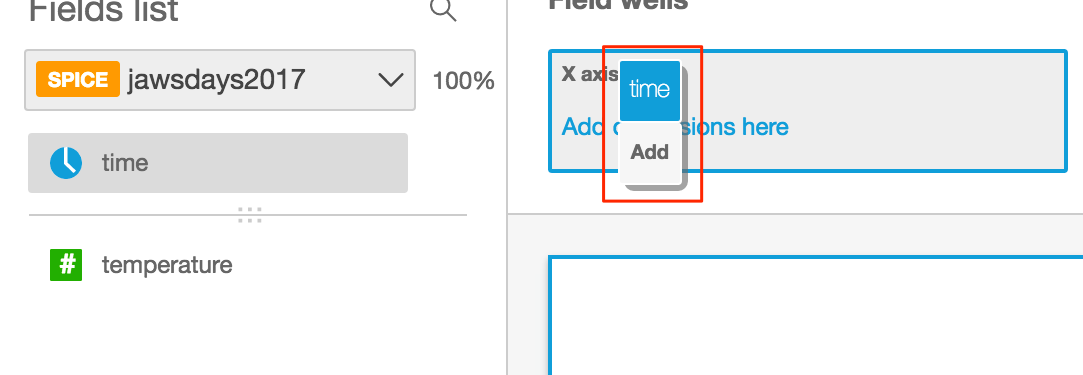 ※ドラッグ&ドロップした場合
* Y軸に表示するデータを指定するため、Fields listの「temperature」をクリックする(「temperature」をField wellsの「Value」にドラッグ&ドロップしても同じ事ができる)

集計する条件を変更する
- この時点では年単位の温度の合計値となっているため、時間単位の平均値になるように設定を変える
- 「X axis」の「V」をクリックし、「Aggregate」を「Hour」に変更する

* 「Value」の「V」をクリックし、「Aggregate」を「AVERAGE」に変更する

* 時間単位の平均温度が表示されるようになる

[ToDo 13] SPICEのデータを更新する
2017年2月現在、SPICEのデータを自動でリフレッシュする機能は搭載されていないため、手動でリフレッシュする必要があります。
2017年2月22日にスケジュールリフレッシュの機能が搭載されました。今回は手動でリフレッシュしますが、設定方法はこちらを参照。
- 左上のアイコンをクリックする

* 「Manage data」をクリックする
* リフレッシュするデータセットをクリックする。
* 「Refresh Now」をクリックする。
 * 「Refresh」をクリックする。
* 「Refresh」をクリックする。 * 「We have submitted your refresh request.」と表示されたら、「OK」をクリックする。
* 「Last Refreshed」が「a few seconds ago」になったらインポート完了。インポートされたレコード数も更新される。
* 「We have submitted your refresh request.」と表示されたら、「OK」をクリックする。
* 「Last Refreshed」が「a few seconds ago」になったらインポート完了。インポートされたレコード数も更新される。
補足
- 最後の画面で「Edit data set」をクリックすると、SPICEの中を参照したり、設定を変える事ができる。(Preparing data)

[ToDo 14] 計算フィールドを使う
計算フィールド(Calculated field)を使う事で、データソースのデータに対して演算を行う事ができます。もちろん演算後のデータを使って可視化ができます。
ここでは取得した温度データを高い・中間・低いに分類して、パイチャート(円グラフ)で可視化します。
計算フィールドの追加
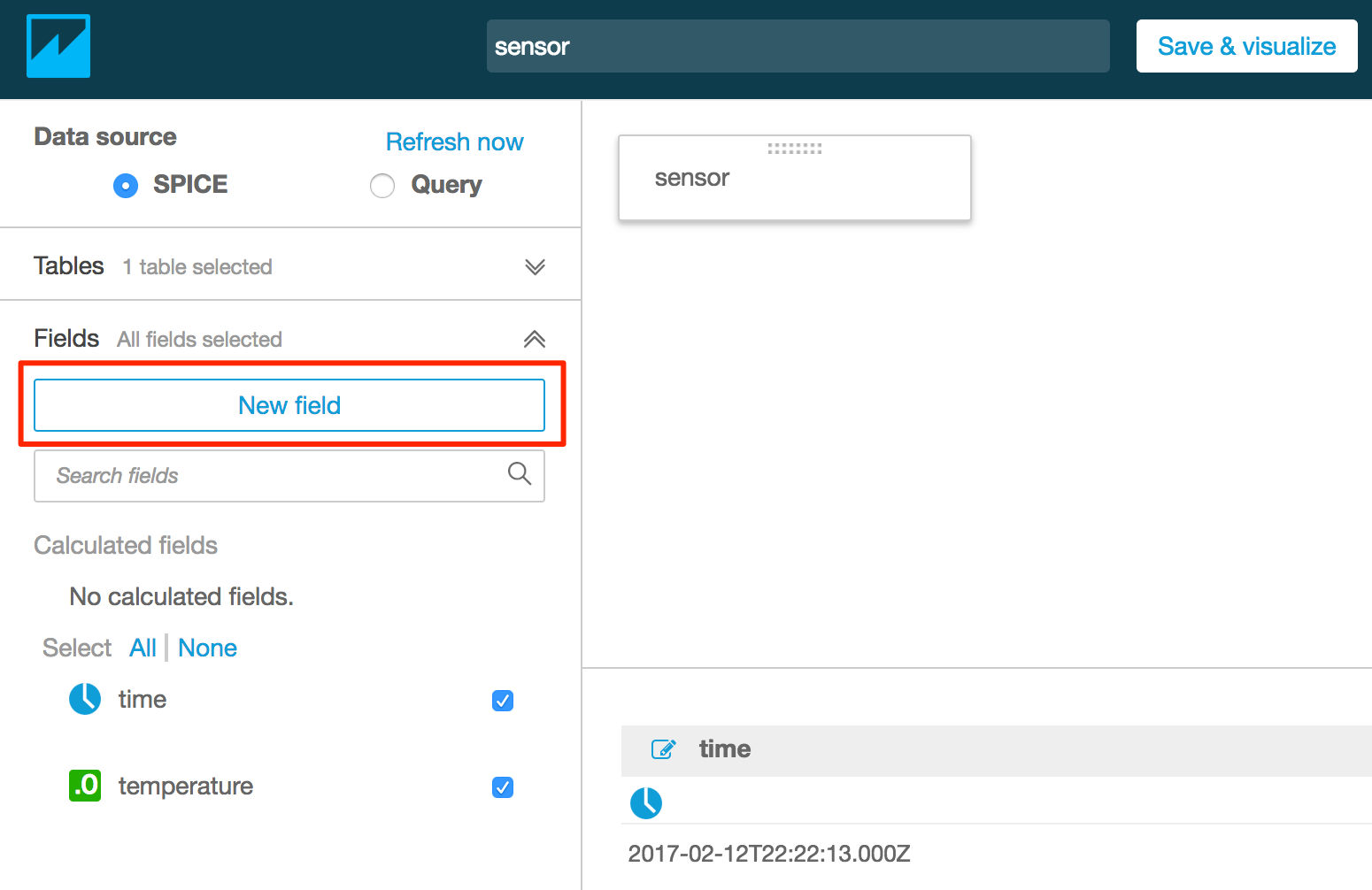
- 前述の「補足」の手順でPreparing dataの画面を表示する
- 「New field」をクリックする
- 「New calculated field」画面が表示されたら「Function list」の「ifelse」をクリックする(選択したら水色に変わる)
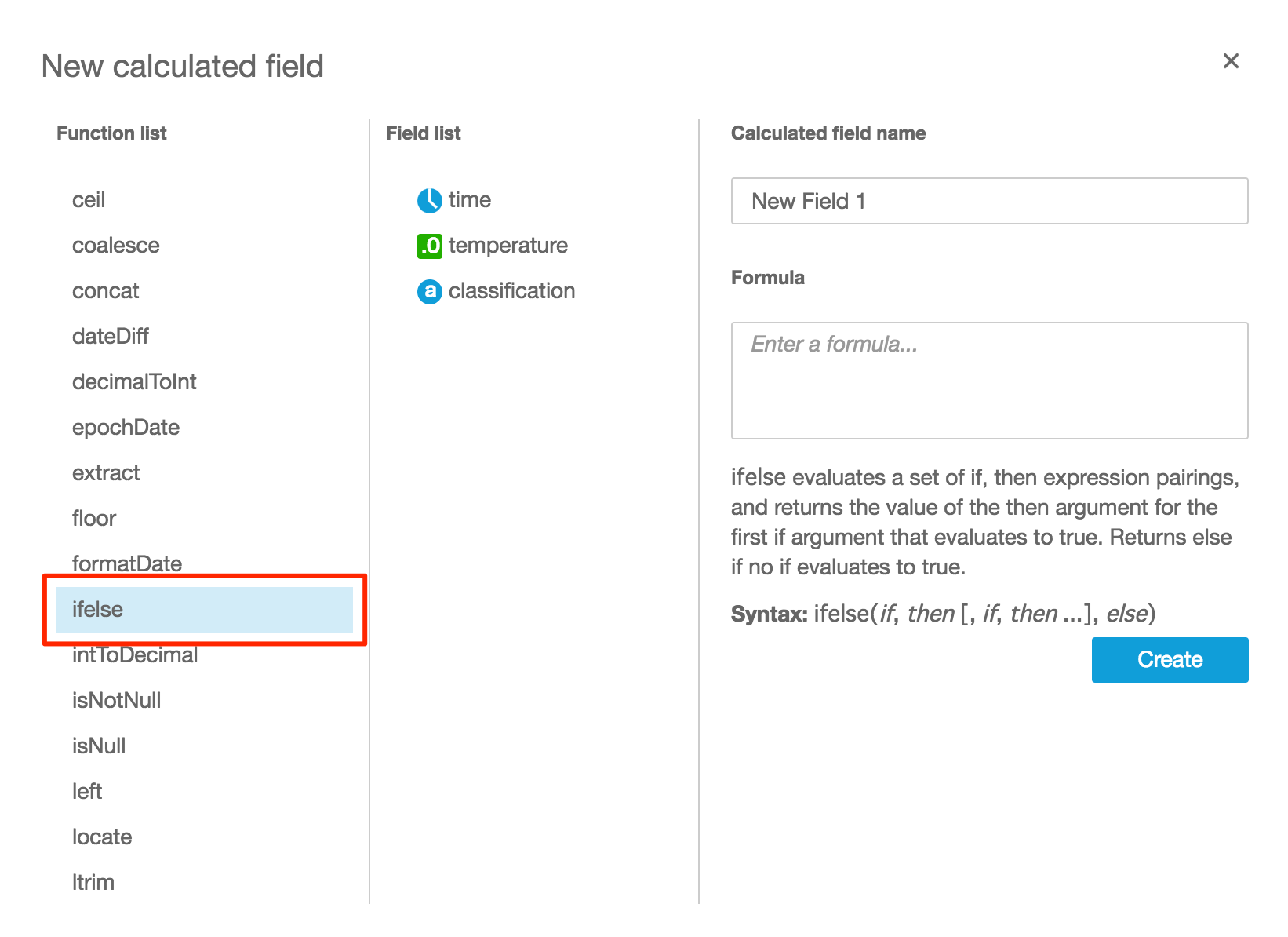
- 「Calculated field name」に任意の名称を入力、「Formula」に以下の内容を入力したら、「Create」をクリックする(完了までに時間がかかる場合がある)
ifelse(temperature < 20,'low',temperature > 29,'high','middle')
 **注意**
**注意*** ifelseでは、温度を判定し、20度未満ならlow、29度より大きければhigh、それ以外はmiddleに分類しています。 * ifelse内の数値は温度を表します。会場の温度に合わせて調整が必要となる可能性があります。
* 完了すると「Calculated fields」にフィールドが追加され、分類されたデータが格納される

* 「Save」をクリックする

パイチャート(円グラフ)の設定
作成済みのAnalysisにパイチャート(円グラフ)を追加します。
- 左上のアイコンをクリックする
- 作成済みのAnalysisをクリックする
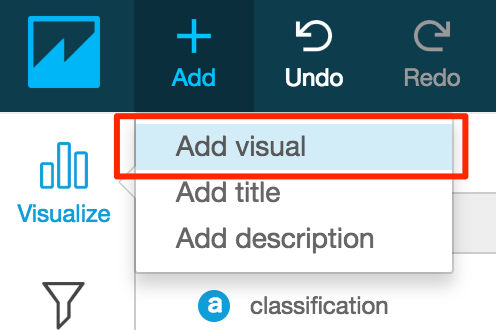
- 左上の「+Add」をクリックし、「Add visual」をクリックする
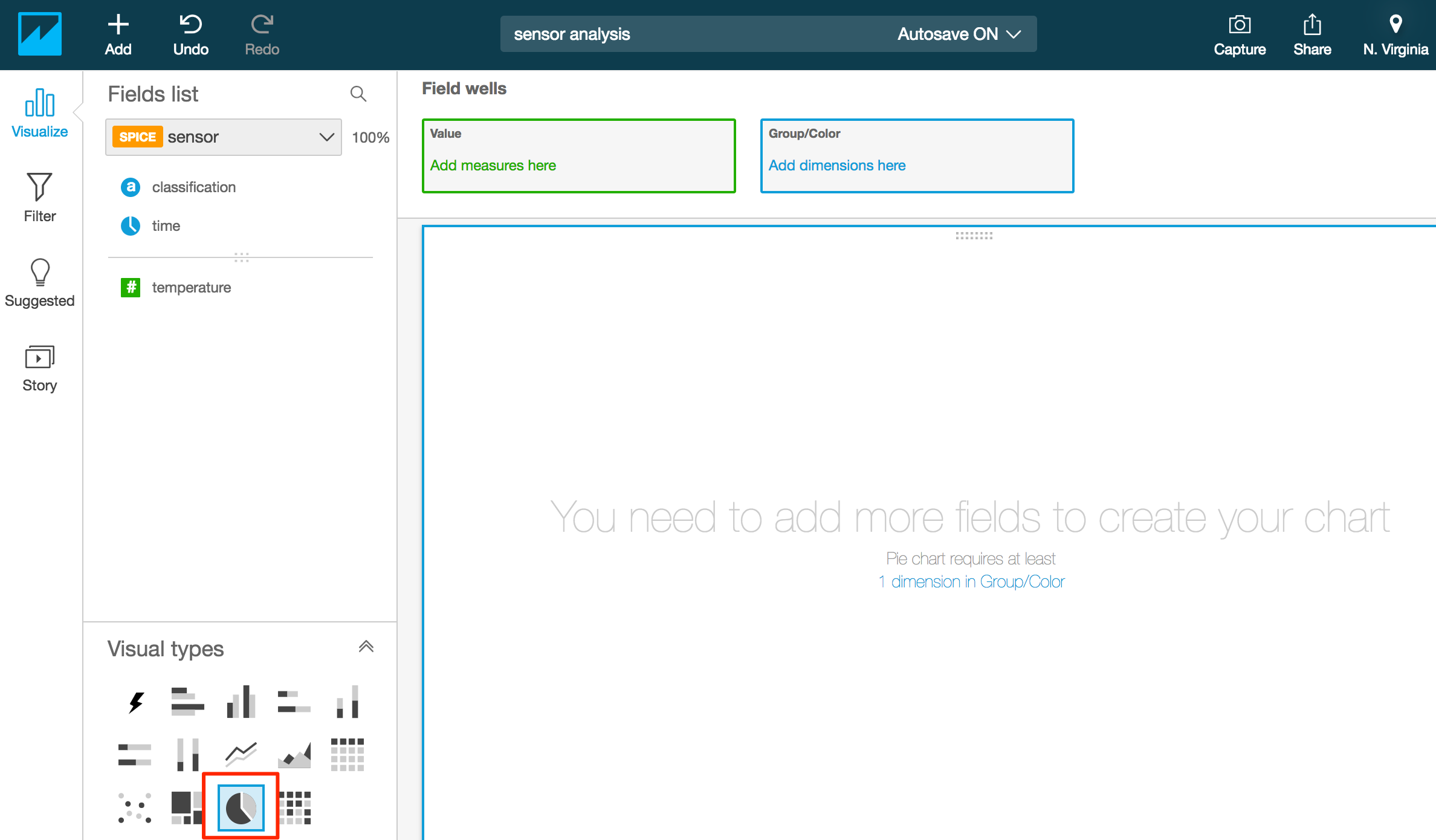
- 未設定のグラフが追加されるので、「Visual types」の「Pie chart」をクリックする
- 追加した計算フィールドをクリックすると、「Group/Color」に設定され、グラフが表示される
