目的
趣味でギターを引いていて,ギター音をAIが正しく識別できるか気になった
今回は通常のNeural Networkと簡単なCNNを用いてリアルタイムに9種類のコードを分類してみる
環境
Pythonを使用する.以下のライブラリをインストールする.
・Pyaudio
・Chainer
・keras
・sklearn
・pandas
アジェンダ
- 音波形の取得,フーリエ変換
- Neural Network
- CNN
- 今後の課題
1. 音波形の取得,フーリエ変換
リアルタイムで音声波形を取得し,フーリエ変換し正規化,結果をcsvファイルに書き込むプログラム
申し訳ないが,フーリエ変換に関しては専門外のためあまり詳しくない
プログラムも他の記事を参考にしたため勉強して使用した方が良いが,numpyで簡単にできるみたいですね
全てのコードの波形をcsvファイルに記録したら,ラベルをつけて1つのファイルに結合しておく
今回はC,D,G,A,Am,F,Fm,B,Bm, 無音状態 の10種類のスペクトルを分類する
data-kakikomi.py
import pyaudio
import numpy as np
import matplotlib.pyplot as plt
import math
import csv
CHUNK = 1024
RATE = 44100 #サンプリング周波数
P = pyaudio.PyAudio()
stream = P.open(format=pyaudio.paInt16, channels=1, rate=RATE, frames_per_buffer=CHUNK, input=True, output=False)
x = np.arange(1,1025,1)
freq = np.linspace(0, RATE, CHUNK)
# 正規化
def min_max(x, axis=None):
min = x.min(axis=axis, keepdims=True)
max = x.max(axis=axis, keepdims=True)
result = (x-min)/(max-min)
return result
o = open('fmcode.csv','a') #コードごとにファイルを変更する
writer = csv.writer(o, lineterminator=',\n')
while stream.is_active():
try:
input = stream.read(CHUNK, exception_on_overflow=False)
# bufferからndarrayに変換
ndarray = np.frombuffer(input, dtype='int16')
#フーリエ変換
f = np.fft.fft(ndarray)
#周波数
freq = np.fft.fftfreq(CHUNK, d=44100/CHUNK)
Amp = np.abs(f/(CHUNK/2))**2
Amp = min_max(Amp)
writer.writerow(Amp)
print(Amp)
#フーリエ変換後のスペクトルを表示
line, = plt.plot(freq[1:int(CHUNK/2)], Amp[1:int(CHUNK/2)], color='blue')
plt.pause(0.01)
plt.ylim(0,1)
ax = plt.gca()
ax.set_xscale('log')
line.remove()
except KeyboardInterrupt:
break
stream.stop_stream()
stream.close()
P.terminate()
f.close()
print('Stop Streaming')
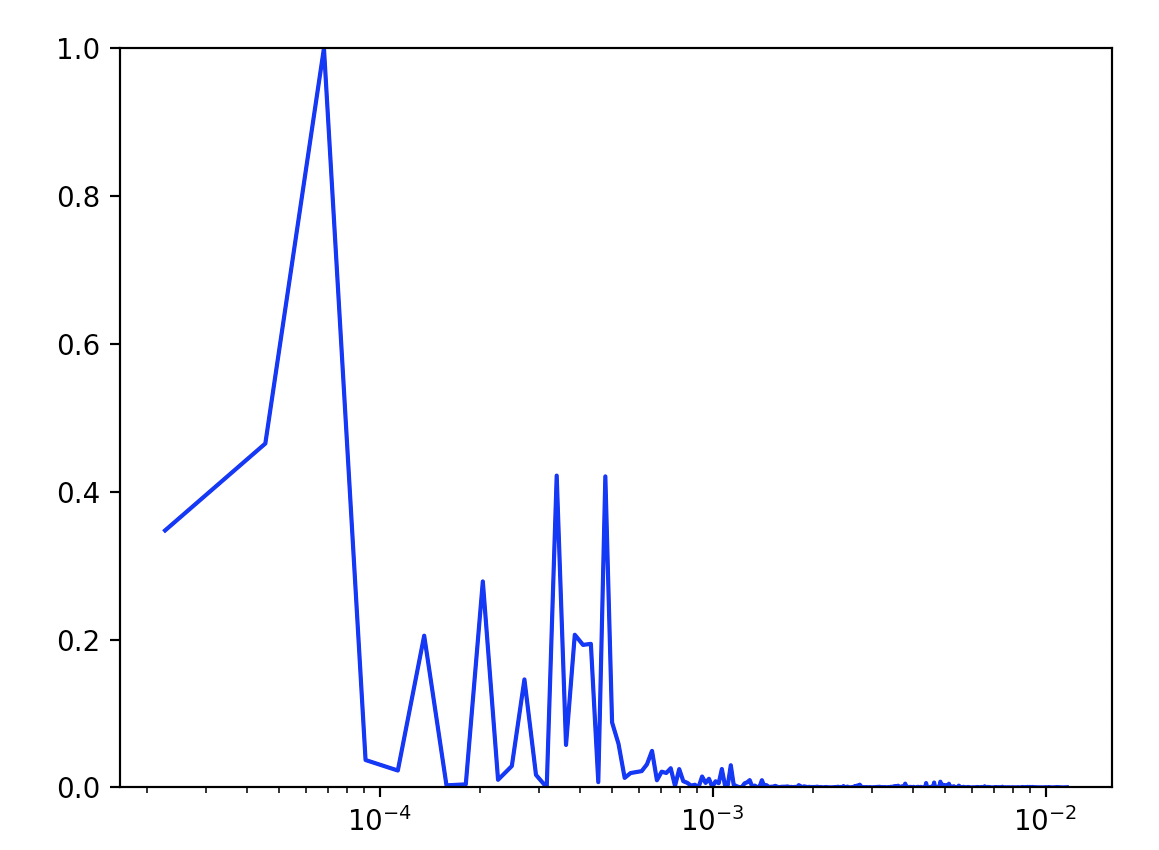
下の図のようにフーリエ変換後の波形が表示される
2. Neural Network
次にChainer(NN)を用いて学習モデルを作成する
chainer_NN.py
import chainer
from chainer import Chain, optimizers, iterators, training, datasets, Variable
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
import numpy as np
import pandas as pd
from chainer import serializers
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# chainerによるニューラルネトワークのクラス
class NN(Chain):
def __init__(self, in_size, hidden_size, out_size):
super(NN, self).__init__(
xh = L.Linear(in_size, hidden_size),
hh = L.Linear(hidden_size, hidden_size),
hy = L.Linear(hidden_size, out_size)
)
def __call__(self, x):
h1 = F.sigmoid(self.xh(x))
#h1 = F.dropout(F.relu(self.xh(x)), train=train)
h2 = F.sigmoid(self.hh(h1))
y = F.softmax(self.hy(h2))
return y
# データ読み込み
data1 = pd.read_csv("data.csv")
X = data1.iloc[:, 0:1024] #140 #no_outline:106
Y = data1.iloc[:, 1025] #↑+2
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.1, random_state = 0)
X_train = X_train.values
Y_train = Y_train.values
X_test = X_test.values
Y_test = Y_test.values
# chainerでデータを読み込む時に必要な部分
X_train = np.array(X_train.astype(np.float32))
Y_train = np.ndarray.flatten(np.array(Y_train.astype(np.int32)))
X_test = np.array(X_test.astype(np.float32))
Y_test = np.ndarray.flatten(np.array(Y_test.astype(np.int32)))
# 各層のユニット数,エポック数
n_in_units = 1024
n_out_units = 10
n_hidden_units = 100
n_epoch = 3000
# 決めたユニット数をニューラルネットワークに反映,
model = L.Classifier(NN(in_size = n_in_units, hidden_size = n_hidden_units, out_size = n_out_units))
optimizer = optimizers.Adam()
optimizer.setup(model)
# 訓練部分
print("Train")
train, test = datasets.split_dataset_random(datasets.TupleDataset(X_train, Y_train), int(len(Y_train)*0.9))
train_iter = iterators.SerialIterator(train, int(len(Y_train)*0.9))
test_iter = iterators.SerialIterator(test, int(len(Y_train)*0.1), False, False)
updater = training.StandardUpdater(train_iter, optimizer, device=-1)
trainer = training.Trainer(updater, (n_epoch, "epoch"), out="result")
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
trainer.extend(extensions.LogReport(trigger=(10, "epoch"))) # 10エポックごとにログ出力
trainer.extend(extensions.PrintReport( ["epoch", "main/loss", "validation/main/loss", "main/accuracy", "validation/main/accuracy"]))
# エポック、学習損失、テスト損失、学習正解率、テスト正解率、経過時間
trainer.extend(extensions.ProgressBar()) # プログレスバー出力
trainer.run()
# 訓練部分で作成した学習済みモデルを保存
serializers.save_npz("model.npz", model)
# テスト部分,結果出力
C_list1 = []
print("Test")
print("y\tpredict")
for i in range(len(X_test)):
x = Variable(X_test[i])
y_ = np.argmax(model.predictor(x=x.reshape(1,len(x))).data, axis=1)
y = Y_test[i]
print(y+2, "\t", y_+2)
C = y_ - y
C_list1 = np.append(C_list1,C)
A = np.count_nonzero(C_list1 == 0)
p = A / (len(C_list1))
print(p)
学習した結果を以下に示す.
0.6749311294765841
通常のNNではあまり精度がよくない.
3. CNN
次にkeras(CNN)を用いて学習モデルを作成する
CNN.py
import numpy as np
# データの読み込みと前処理
from keras.utils import np_utils
# kerasでCNN構築
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.optimizers import Adam
from sklearn.model_selection import train_test_split
import pandas as pd
import time
f_model = './model'
# 時間計測
import time
correct = 10
data = pd.read_csv("data.csv")
X = data.iloc[:, 0:1024]
Y = data.iloc[:, 1025]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.1, random_state = 0)
X_train = X_train.to_numpy()
X_train = X_train.reshape(3264,32,32,1)
X_train = X_train.astype('float32')
Y_train = Y_train.to_numpy()
Y_train = np_utils.to_categorical(Y_train, correct)
X_test = X_test.to_numpy()
X_test = X_test.reshape(363,32,32,1)
X_test = X_test.astype('float32')
Y_test = Y_test.to_numpy()
Y_test = np_utils.to_categorical(Y_test, correct)
model = Sequential()
model.add(Conv2D(filters=10, kernel_size=(3,3),padding='same', input_shape=(32,32,1), activation='relu'))
model.add(Conv2D(32,1,activation='relu'))
model.add(Conv2D(64,1,activation='relu'))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
startTime = time.time()
history = model.fit(X_train, Y_train, epochs=200, batch_size=100, verbose=1, validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test Loss:{0:.3f}'.format(score[0]))
print('Test accuracy:{0:.3}'.format(score[1]))
# 処理時間
print("time:{0:.3f}sec".format(time.time() - startTime))
json_string = model.to_json()
model.save('model_CNN.h5')
学習結果を以下に示す
Test Loss:0.389
Test accuracy:0.948
time:327.122sec
正解率94.8%であり,だいぶよくなった
最後にCNNでリアルタイムにコードを分類してみる
code_detector.py
from keras.models import load_model
import pyaudio
import numpy as np
import matplotlib.pyplot as plt
import math
CHUNK = 1024
RATE = 44100 #サンプリング周波数
P = pyaudio.PyAudio()
stream = P.open(format=pyaudio.paInt16, channels=1, rate=RATE, frames_per_buffer=CHUNK, input=True, output=False)
def min_max(x, axis=None):
min = x.min(axis=axis, keepdims=True)
max = x.max(axis=axis, keepdims=True)
result = (x-min)/(max-min)
return result
model = load_model('model_CNN.h5')
def detect(pred):
a = ["C","D","G","Bm","B","","A","Am","F","Fm"]
pred_label = a[np.argmax(pred[0])]
score = np.max(pred)
if pred_label != "":
print(pred_label,score)
while stream.is_active():
try:
input = stream.read(CHUNK, exception_on_overflow=False)
# bufferからndarrayに変換
ndarray = np.frombuffer(input, dtype='int16')
line, = plt.plot(ndarray, color='blue')
plt.pause(0.01)
f = np.fft.fft(ndarray)
Amp = np.abs(f/(CHUNK/2))**2
Amp = min_max(Amp)
Amp = Amp.reshape(1,32,32,1)
Amp = Amp.astype('float32')
pred = model.predict(Amp)
detect(pred)
plt.ylim(-200,200)
line.remove()
except KeyboardInterrupt:
break
stream.stop_stream()
stream.close()
P.terminate()
print('Stop Streaming')
Cコードを弾いた時
C 1.0
C 1.0
C 1.0
C 1.0
C 1.0
C 1.0
C 1.0
C 1.0
C 1.0
C 0.99999833
C 1.0
C 0.9999988
C 1.0
C 1.0
C 1.0
G 0.98923177
Dコードを弾いた時
D 0.9921374
D 1.0
D 1.0
D 1.0
D 1.0
D 1.0
D 0.99915206
Bm 0.9782265
D 1.0
D 0.967693
Bm 0.43872046
D 0.5228199
D 0.9998678
D 0.99264586
Amコードを弾いた時
A 0.7428425
Am 0.98781455
Am 1.0
Am 1.0
Am 1.0
Am 1.0
Am 0.99081403
Am 0.9998661
Am 0.98926556
Am 0.9721039
Am 0.9999999
Am 0.99899584
A 0.7681879
Am 0.59727216
Am 0.77573067
Fコードを弾いた時
Fm 0.54534096
F 1.0
F 0.4746885
F 0.99983275
F 0.9708171
F 1.0
F 0.9999441
F 0.99999964
C 0.50546944
F 0.9999746
F 1.0
F 1.0
F 0.9999999
F 0.966004
C 0.79529727
F 1.0
F 0.99999976
Fmコードを弾いた時
Fm 0.9999492
Fm 1.0
Fm 1.0
Fm 0.99058926
Fm 1.0
Fm 0.99991775
Fm 0.9677996
F 0.96835506
Fm 1.0
Fm 0.9965939
Am 0.63923794
C 0.8398564
Fm 0.91774964
Am 0.9995415
今後の課題
個人的にはFとFmが識別できていることに驚いたw
現状,音声データを主のギター でしか取得していため,他のギター や弾き手によって精度が落ちてしまう
さらにデータ数を増やしてモデルを作成することが今後の課題かなあ?