前提
AWS Step Functionsとは、ステートマシンを使用してワークフローを構築し、アプリケーションの自動化を実現するサービスです。一方、Amazon Bedrockは、大規模な言語モデルを活用して自然言語処理の機能を提供するサービスです。AWS Step Functionsから Amazon Bedrockを実行することで、ワークフロー機能の中に生成AI機能を組み込むことが可能となっています。
生成AIはチャット機能の形式で使われることが多いですが、実業務の中での利用を考えたときにワークフローや自動化の文脈で活用できると利用の幅が非常に広がると考えられます。そこで今回、以下の記事を参考にしつつAWS上で生成AIを含んだ自動フローの実装を行いました。
この記事では、以下の2点を伝えることを目的としています。
- 生成AIを業務の中で活用するにあたってワークフローの中への組み込み・自動化というユースケースにどう応えられるかを解説すること
- AWS Step FunctionsとAmazon Bedrockが統合されておりワークフローの中への組み込みが容易になっている、これによりスピーディな生成AIの活用が可能になったのでその具体的な活用イメージを提示すること
検証内容及びワークフローの説明
今回の検証では以下のユースケースを想定してフローを構築しました。
ユースケース
- あるシステム会社のAWS基盤環境構築チームでは多数の案件実績があり、環境構築の都度構築物のレビューを行っている
- レビュー時の音声データを自動的に文字起こししたテキストが複数存在する
- 新システム構築時には同じレビューアがレビューを行うため、似た質問・指摘が行われることが多い
上記の状況において生成AIを用いて過去のレビュー指摘・質問を参考にしながら新システムの構築レビューで想定されるレビュー指摘・質問をアドバイスしてくれる機能を実装しました。
これにより実際のレビューの効率化と高品質化につなげるということが目的です。
処理概要
今回の仕組みは以下2つのワークフローから構成されます。
- 過去レビュー時の観点取り込み用マシン:
過去に行われたレビューの内容(オンライン打ち合わせの様子を機械的に文字起こししたもの)をインプットとして、具体的にどのAWSサービスに対してどういったレビュー質問・指摘が行われたのかを列挙し、その結果をS3にPUTするためのマシンです。このマシンはインプットファイルがS3に格納された時点や日次・週次等定期的に自動実行されることを想定しています。 - 新システムのレビューで想定される質問・指摘生成用マシン:
1の結果生成された"過去にされたレビュー質問・指摘項目"を踏まえて、今回の新システムの構成であればどのAWSサービスにどのようなレビュー質問・指摘がされそうかをアドバイスするためのマシンです。このマシンはユーザがオンラインで実行する想定で、その際のインプットとして新システムの構成概要を自由記入することを想定しています。
ワークフロー内の処理の概要説明
1,2それぞれのワークフローのイメージは以下の通りです。
1.過去レビュー時の観点取り込み用マシンの概要
ワークフローイメージ:
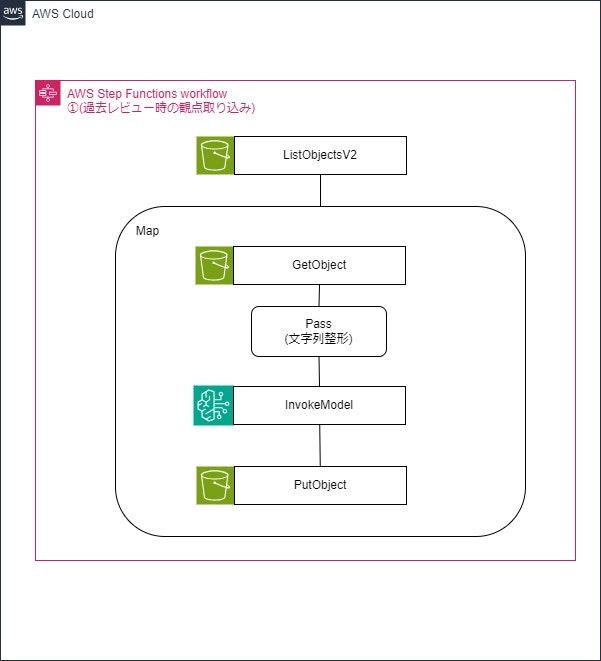
前提:S3上に過去レビュー時の内容(オンライン打ち合わせの様子を機械的に文字起こししたもの)が複数格納されている
| No | プロセス | 内容 |
|---|---|---|
| 1 | ListObjectsV2 | S3に存在するレビュー時の内容が記載されたオブジェクトのKeyを取得する |
| 2 | Map | これ以降の処理をMap(動的並行処理)で処理する |
| 3 | Getobjects | S3内のデータを取得する |
| 4 | Pass | GetObjectsの結果からBedrockのInvokemodelに必要な項目(S3オブジェクトのBodyと後続の処理で用いるKey名のみ)を抽出する |
| 5 | InvokeModel | モデルを実行して過去レビュー時の内容から質問・指摘内容をまとめる |
| 6 | PutObject | 5の結果出力された質問・指摘内容をS3にPutする |
InvokeModel部分のStep Functions定義:
"Bedrock InvokeModel": {
"Type": "Task",
"Resource": "arn:aws:states:::bedrock:invokeModel",
"Parameters": {
"ModelId": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-opus-20240229-v1:0",
"Body": {
"messages": [
{
"role": "user",
"content.$": "States.Format('{}{}','あなたはシステム構築時のレビュー指摘の打ち合わせメモを基にしてレビューでの指摘・質問について内容と観点をまとめる役割を持っています。\n\n日本のあるシステム会社ではAWSを用いたシステム環境構築時にレビューアが実際のAWS環境を見ながらレビューをします。以下の打ち合わせメモはそのレビューのやりとりについて機械的に文字起こししたものです、そのため誤植が多くあります。\n\n打ち合わせメモに記載されている内容から、レビュー時に行われた質問・指摘事項をできるだけ具体的にまとめてください。ただし、質問や指摘に対する回答は記載不要です。特定のAWSのサービスに対する質問・指摘は必ずそのAWSサービス名を明記してください。質問・指摘事項はAWSサービスごとにまとめて記載してください、もしどのAWSサービスにも紐づかない質問・指摘が存在する場合には「その他」というカテゴリにまとめてください。出力してもらった文章をそのまま機械的に後工程で取り込むため指摘される可能性のある内容以外の文字は一切出力しないようにお願いします。\n\n打ち合わせメモ#####\n\n' , $.Body )"
}
],
"max_tokens": 3000,
"anthropic_version": "bedrock-2023-05-31"
}
},
"Next": "PutObject",
"ResultPath": "$.InvokeModelResult",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"BackoffRate": 2,
"IntervalSeconds": 1,
"MaxAttempts": 3
}
]
},
2.新システムのレビューで想定される質問・指摘生成用マシン
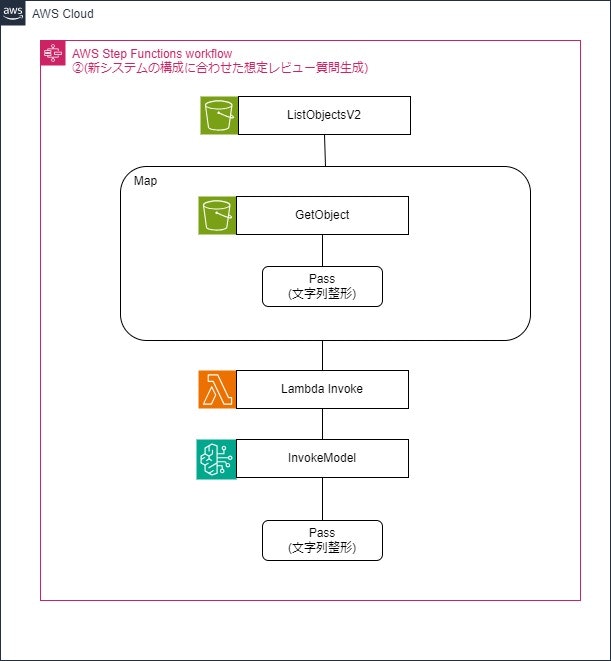
インプット:このマシンを実行する際の実行入力としてSystemSummaryという項目でシステムの構成面の概要や利用するAWSサービスを自由記入で記載した情報を入力する。
| No | プロセス | 内容 |
|---|---|---|
| 1 | ListObjectsV2 | S3に存在する1の処理の結果である過去の質問・指摘内容が記載されたオブジェクトのKeyを取得する |
| 2 | Map | No3,4の処理をMap(動的並行処理)で処理する |
| 3 | Getobjects | S3内のデータ(過去レビューの質問・指摘内容)を取得する |
| 4 | Pass | GetObjectsの結果からS3オブジェクトのBodyとシステムの概要を記載したSystemSummaryだけを抽出する |
| 5 | Lambda Invoke | Lambdaを実行して過去レビューの質問・指摘内容を複数の配列から1つの文字列型に変換する |
| 6 | InvokeModel | モデルを実行して過去レビュー時の内容を参考にして今回の構成で質問・指摘されそうな内容を出力する |
| 7 | Pass | 6の結果出力されたうち、ユーザにわかりやすいようBody部分(今回の構成で質問・指摘されそうな内容)のみを抽出する |
InvokeModel部分のStepFunctions定義:
"Bedrock InvokeModel": {
"Type": "Task",
"Resource": "arn:aws:states:::bedrock:invokeModel",
"Parameters": {
"ModelId": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-opus-20240229-v1:0",
"Body": {
"messages": [
{
"role": "user",
"content.$": "States.Format('{}{}{}{}{}','あなたは過去に行われたAWSを用いたシステム構築時のレビュー指摘内容と観点を参考にして、新たなAWSを用いたシステム構築で想定されるレビュー指摘内容と観点を推測する役割を持っています。\n\n日本のあるシステム会社ではAWS環境構築時にレビューアが実際のAWS環境を見ながらレビューをします。\n\n以下「過去指摘・観点」に記載されている内容が過去のAWS案件で実際に出された指摘内容・観点です。\n\nそれに対して「新システムの概要」で記載された内容が新たに構築したAWS環境でこれがレビュー対象になります。「過去指摘・観点」の内容を踏まえて「今回のシステム構成概要」でレビューアが指摘する可能性のある内容をできるだけ多く具体的に教えてください。その際、AWSのサービスごとに確認・指摘内容をカテゴリ分けを行ってください。なお、出力してもらった文章をそのまま機械的に後工程で取り込むため指摘される可能性のある内容以外の文字は一切出力しないようにお願いします。\n\n過去指摘・観点#####\n\n' , $.Body , '###############\n\n今回のシステム構成概要#####\n\n', $.SystemSummary , '###############\n\n' )"
}
],
"max_tokens": 3000,
"anthropic_version": "bedrock-2023-05-31"
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"BackoffRate": 2,
"IntervalSeconds": 1,
"MaxAttempts": 3
}
],
"Next": "Pass"
},
ワークフロー構築にあたって注意すべきポイント
今回実際にワークフローを構築して認識した注意ポイントとして以下があげられます。
- BedrockのInvokeModelのレスポンスとして返されるものはあくまで文字列でリスト型や数値にはできない(常にキレイに数値を返してくれることもない)ため、それを前提にするかもしくはその後のデータ加工が必要になる
- 細かい部分の入出力内容の整理ではpassやLambdaを活用することが必要である
- リージョン単位で利用できるモデルが異なるため、適切なリージョンを選択することが必要である
- エラーを想定したリトライ等の対応を組み込むことが必要である
1点目について、レスポンスは画像生成等でない限り文字列でしかもある程度の形はプロンプトの中で指示できるものの常に自分が想定したそのままの形で返ってくるとは限らない点に注意が必要です。
Lambda関数等はレスポンスの形を指定することで常にその形で返却されますが生成AIでは(現時点では)厳密に常に同じ形ではないため、後続の処理ではそれを前提とした作りにする必要があります。
2点目について、ワークフローの中のポイントごとにPassやLambdaを用いて入出力するデータを整理することにより、フローの中で必要なデータのみを効率的に受け渡すことができるようになります。
これは生成AIを用いたフローに限定されることではありませんが、特に生成AIを用いる場合プロンプトやレスポンスに自然言語を用いており入出力のデータが大きくなる傾向があると感じていますので、実際にワークフローを使って運用していくにあたってはこういった点も意識して開発する必要があると考えています。
3点目について、Amazon Bedrockで利用可能なモデルはリージョンごとに異なりますので自分が使いたいモデルがどのリージョンにあるのかを確認してそれに合わせてStep Functionsなどを構築する必要があります。
今回は2024年4月現在Claude3 opusが唯一利用できるオレゴンリージョンを利用しています。
4点目について、今回の検証のなかで何度かinvokeModelを行ったところ以下のエラーが出力されることがありました。こちら、フローを再実行したことで解消されていますのでおそらく一時的なエラーではないかと推測しています。Step Functionsのフローの中でリトライ設定を行うことで一時的なエラーが発生しても対応できるようにしておきましょう。

今後考えている改良事項
今回の機能を実装した結果現在考えている今後の改良点として以下2点があります。
- 除外条件の設定:
過去のレビューで頻繁に指摘された内容のうち、現在はなにかしら仕組みで対応ができているなどレビューで指摘されなくなっているものもあり得ます。そういった質問・指摘内容を生成AIの出力結果から除外するためのフィルタリング機能です。 - 想定レビュー質問・指摘事項に対するIaC設定確認:
AWSの環境構築をCloudFormationで行っているとした場合に、新システムで利用するCloudFormationテンプレートを生成AIが読み取って想定質問・指摘事項に対しての回答を作成する機能です。
特に2点目については1システム構築するためにCloudFormationテンプレートを数十程度利用する場合もあるため、それらをどのように読み取らせるか、等生成AI自体の機能や精度とは違う観点の検討が必要と考えています。
この部分の対応についてはStep FunctionsではMapで数十の処理を並列で実行できるので、CloudFormationテンプレートの数だけMapで処理するようにしてその中でテンプレートの中身に対して想定質問・指摘の該当箇所をチェックしていくような力業でも対応できるのではないかと考えています。
今回の検証で分かったこととまとめ
今回の検証を通じて生成AIをワークフローの中に組み込んで自動化していくということがAWS Step FunctionsとAmazon Bedrockを用いることで短期間に実現可能と分かりました。今後生成AIの本格的な利用が進む中、生成AI単体で価値を生み出すのではなく様々な業務処理の中に溶け込んで活用して価値を出すシーンが増えることを想定するとこの機能は非常に重要であると考えられます。
それからAmazon Bedrockでは多くのLLMが利用可能でそれらをAWS Step Functionsから実行することが非常にシンプルであることが分かりました。モデルによって入出力の形式が若干異なることはありますがAmazon Bedrock側のドキュメント等ですぐに確認が可能なことと、例えばClaude3であればopus,sonnet,haikuとも同じ入力で対応可能ですのでワークフローを作りながらどのモデルを使うか試行を繰り返すことが非常に容易です。
最後に、注意ポイントでも記載している通り生成AIをワークフローの中の一部として利用しようとする場合にはデータの加工を適切に行えることが重要になってくるということが分かりました。生成AIが出すレスポンス自体を厳密にユーザがコントロールすることは難しいという前提のもと、そのデータを適切に扱えるよう処理を施すことで品質の高いワークフローにすることができると考えています。