たいそうなタイトルにしてしまいましたが、Rの機械学習パッケージ{caret}を使って、
PowerBI上にアウトプットを表示させることをやってみた半分個人的メモです。
データセットの準備
いつものirisデータセットを利用します。
データの読み込ませ方は以下記事をご参照ください。
【PowerBIメモ】ggplot2を使って、Rのグラフィックを埋め込んでみる
ランダムフォレストをR上で実行
「クエリ編集」→「変換」→「Rスクリプトを実行する」を選択します。
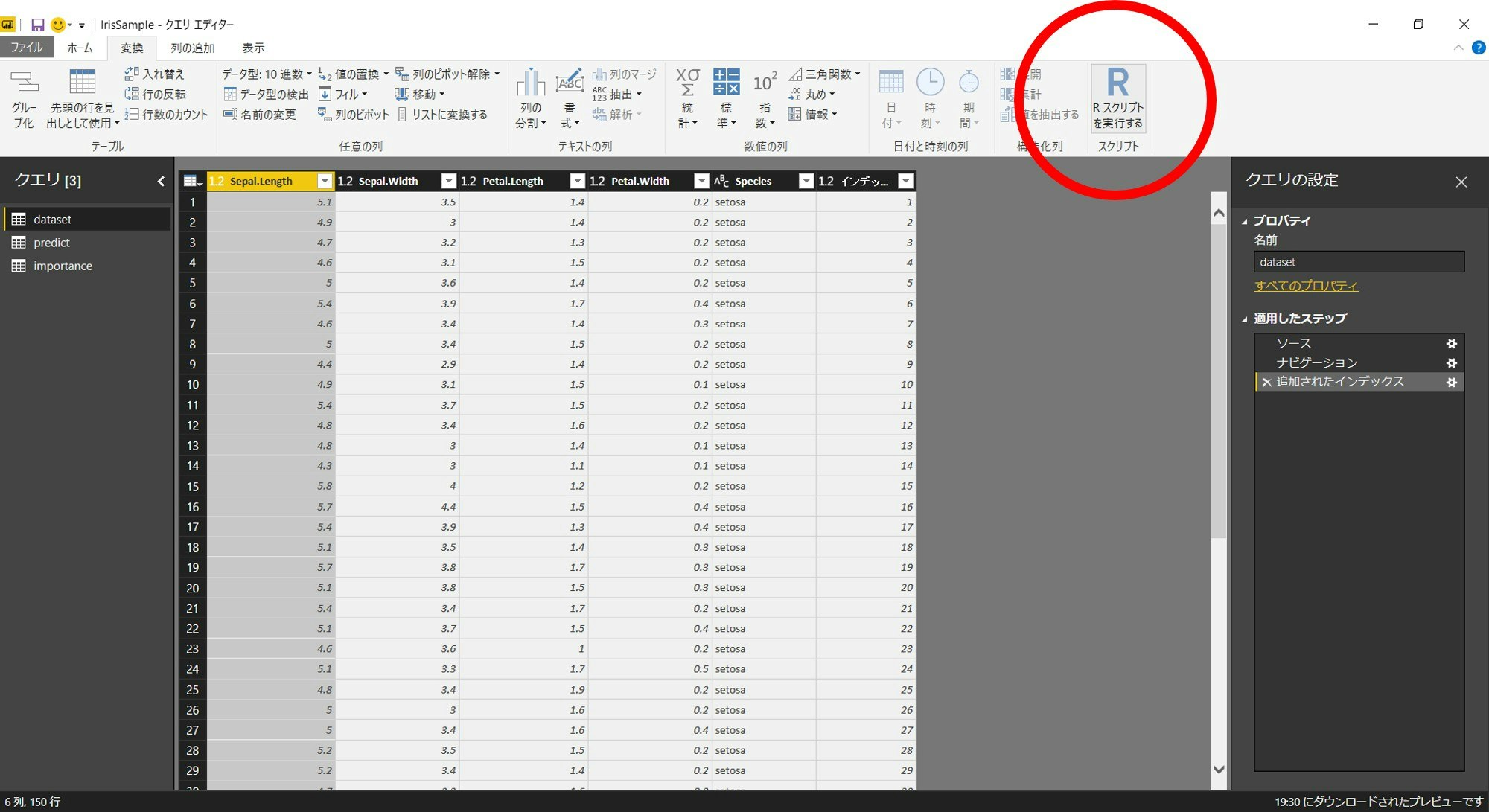
以下のようにランダムフォレストを実行します。今回は、全変数を使ってSpeciesを予測するモデルを作成します。
なお、今回の予測対象データは、適当に作成した10行分のcsvデータです。
library(caret) #今回はcaretパッケージを用います。
caret.rf <- caret::train(
data = dataset ,
Species ~ . ,
method = "rf"
)
TestData <- read.csv("file:///C:/hogehoge/hogehoge.csv")
# テストデータのファイルパスを適宜指定します。
output <- cbind(TestData,Predict =predict(caret.rf,TestData))
# predict関数で、予測モデルを対象データに結合します。
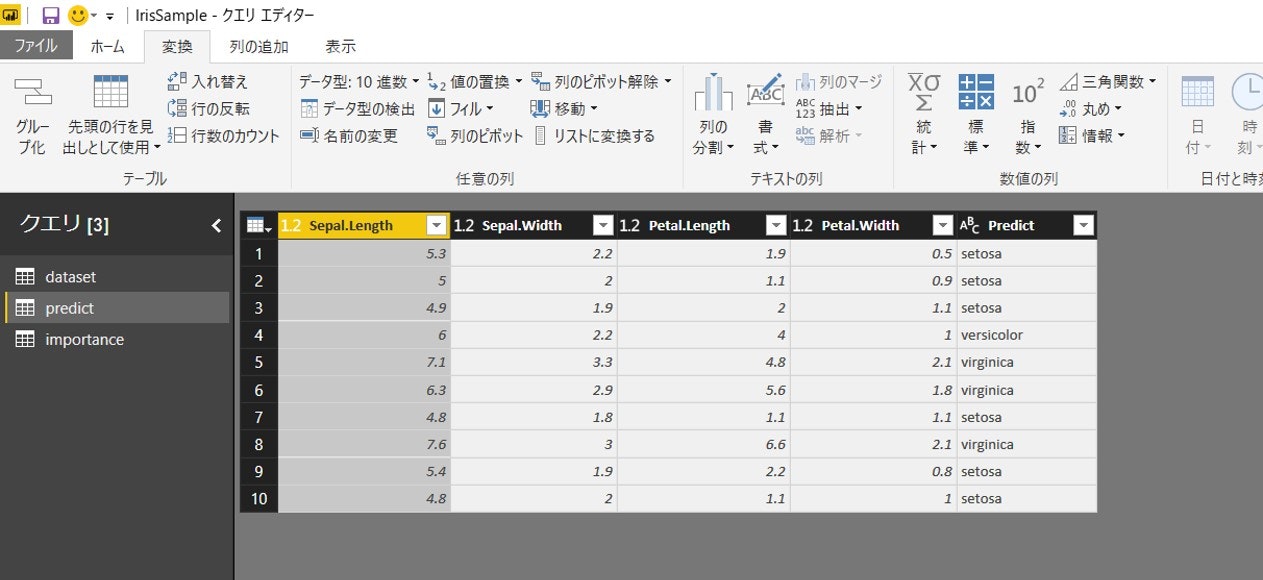
これで予測結果を足しこんだデータセットが作成できました。
こんな感じになったら成功です。Predict列が、予測結果です。
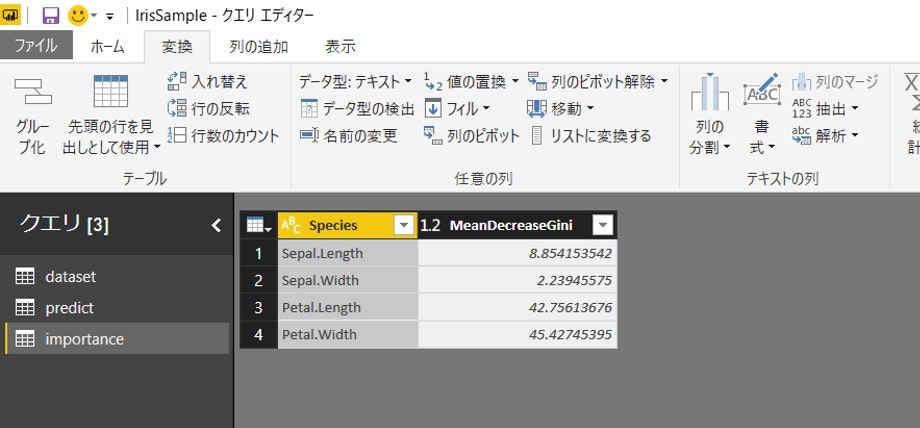
ちなみに、寄与度を計るためのMDA(Mean Decrease Accuracy)やMDG(Mean Decrease Gini)も
データセットにすれば表現することも可能です。
library(caret)
caret.rf <- caret::train(
data = dataset ,
Species ~ . ,
method = "rf"
)
imp <- data.frame(Species = row.names(caret.rf$finalModel$importance) ,caret.rf$finalModel$importance )
# 各変数のMDGをデータフレーム形式にします。
結果はこんな感じ
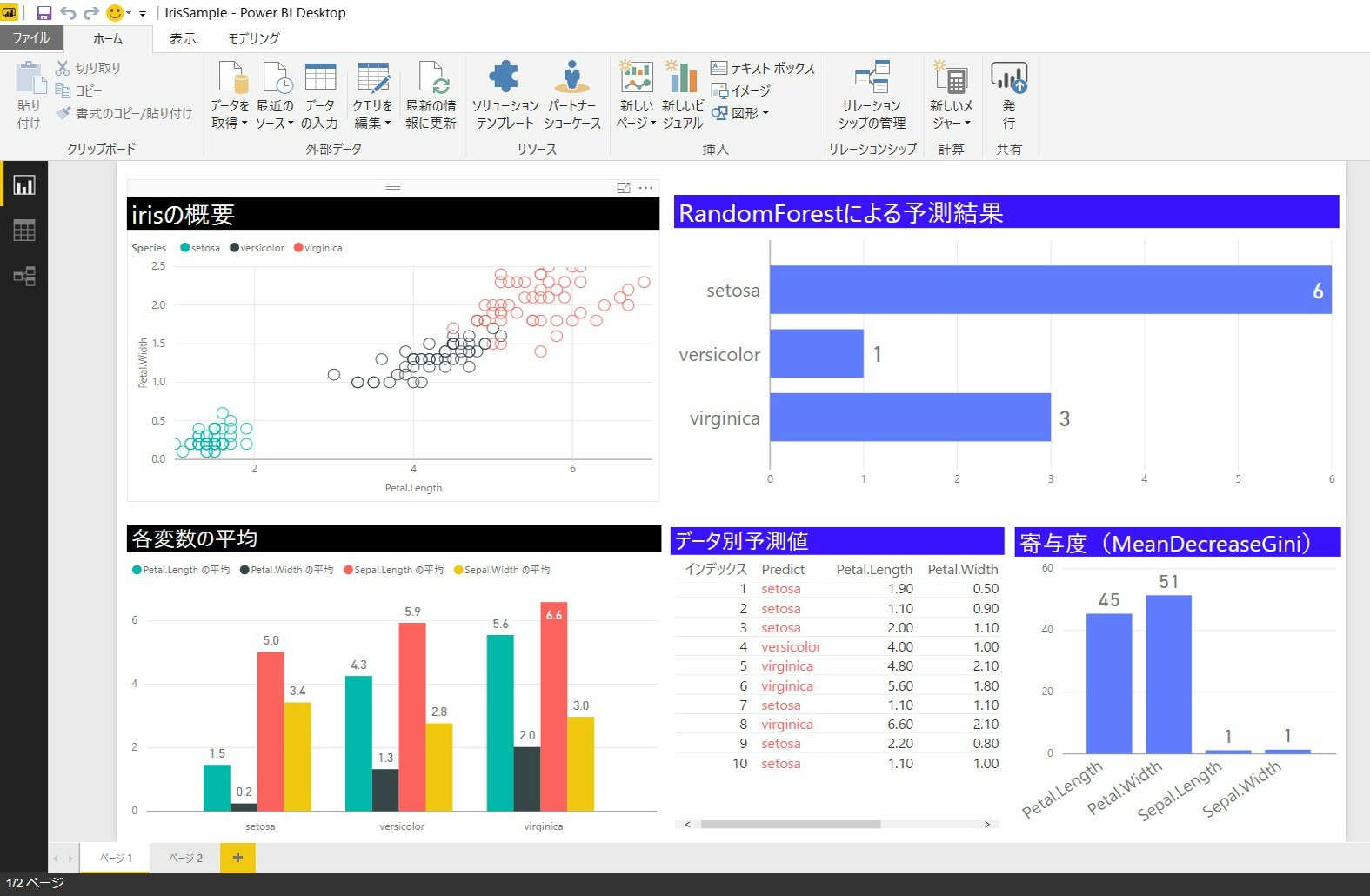
すべての準備が整ったので、あとはPowerBI上で整形します。
おわりに
たぶん、Azureを使って機械学習とアウトプットの仕組みを作っていくのが正当なMicrosoft通な気がしますが、RとPowerBIの知識だけで実装してみました。
無理があるかなーと思ってましたが、学習データと予測データが自動的に更新されていく仕組みにできれば、半自動化の機械学習モデルの完成ですね。
ただし、たった150行のデータだけでも学習時間が長い・・・。なんとか出来るのか今後の課題になりそうです。
ちなみに、機械学習を実務レベルで実装するには、パラメータ調整やモデル評価が必須ですね。
ランダムフォレストでも、パラメータとして決定木の数(ntree)やサイズ(mtry)を指定する必要があります。
その辺はR上で色々検証して最適なモデルを検証し、PowerBIに落とすイメージになりそうです。
※自習してた中でcaretパッケージの利便性に驚愕した私です。
こちらの記事が大変参考になりました。ありがとうございました。