PowerBIでレポートを作成してみよう
さて、前回記事でデータ作成の方法を理解できたと思います。
本来は、データの内容を精査したり、分析しやすいように加工したりするプロセスが必須ですが、
退屈な記事になるので、先にビジュアルづくりを解説していきたいと思います。
PowerBIのレポートについて
PowerBIを立ち上げると、下記のような真っ白な画面になります。

前回のプロセスで取り込んだデータは、このレポート画面でビジュアルにしてレイアウトしていきます。
PowerBI最大の利点は、データの更新が自動でビジュアルに反映される即時性と、
ビジュアルを直接操作して、フィルタや強調などができるインタラクティブ性です。
利用データについて
まずは、ビジュアルにするデータを選択しましょう。
今回は、UCIMachinelearningRepositoryから、「winequality」というデータを拝借して、ビジュアル化してみたいと思います。
上記からダウンロードした「winequality-red.csv」と「winequality-white.csv」を読み取ります。
ビジュアル化しやすいように、以下の操作を加えました。
- 「red」と「white」のデータのマージ
- カラム「types」の追加と「red」「white」のラベリング
- エラー削除
- インデックス列の追加
メジャーの概念を覚えよう
ビジュアルを作成する前に、メジャーの概念を少しだけ学んでおきたいと思います。
データからビジュアルを作るうえで欠かせないプロセス、それは「集計」です。
データをそのままビジュアルに適用するケースもありますが、
合計したり、平均したり「集計」した結果をビジュアルとして表現することが多いと思います。
この「集計」をPowerBIでは「メジャー」という機能で表現しています。
「メジャー」の方法は大きく分けて2点。
- DAXで記述して自分で作成する
- PowerBIビジュアル内で暗黙的に自動生成する
今回は、簡単な後者「PowerBIビジュアル内で暗黙的に自動生成する」方法でビジュアル化したいと思います。
ただし、今後高度・柔軟な集計を実施していくためには前者の方法で明示的に作成していくことがおすすめされています。
メジャー とはなんだろうと考える
DAX,メジャーの概念はこちらでも紹介しています。
【PowerBIメモ】DAX事始め ~計算列とメジャーを理解する~
PowerBIビジュアルを作ってみよう
レポート画面からPowerBIビジュアルを配置していきましょう。
画面右側の「視覚化ウインドウ」から、ビジュアルを選択します。
今回は一番左上、「積み上げ横棒グラフ」を選択します。
ビジュアルを選択すると、視覚化ウインドウに、以下のとおり「フィールド」「書式」「分析」アイコンが選択できるようになります。
フィールドアイコンでは、右側フィールドウインドウから、ビジュアル化したい変数(カラム)を選択して配置します。
たとえば、軸に「types」、値に「alcohol」を選択すると以下のようなビジュアルが自動生成されます。
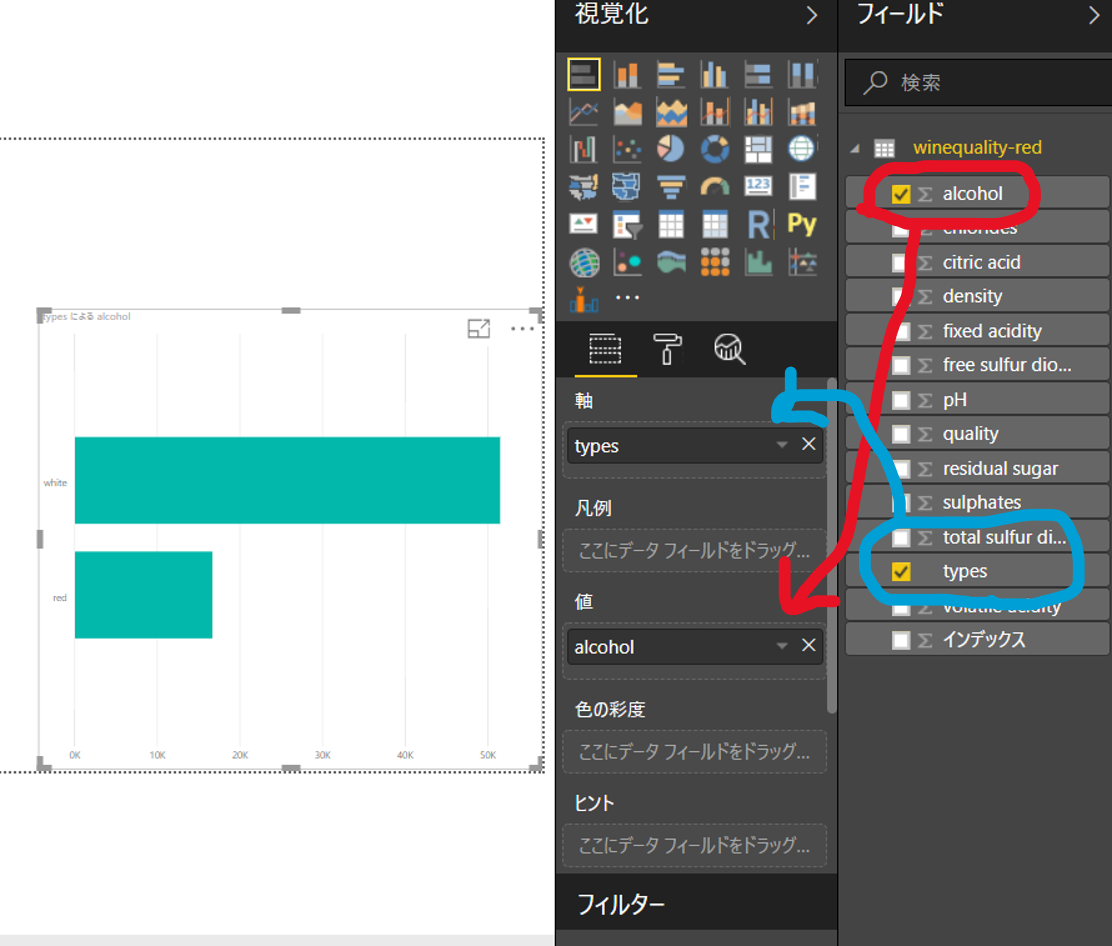
このように簡単な操作で、自動的にビジュアル化してくれるところがPowerBIの一つのメリットです。
ところで、このグラフは何を表現しているのでしょうか?
見たところ「alcohol」は「white」のほうが高いというグラフになっていますが・・・。
実はこれは「alcohol」の合計値が自動的に計算され、ビジュアルに反映されています。
これが、「暗黙的に自動生成されたメジャー」です。
今回は「合計」ではなく「平均」を表示したいので、以下から変更します。

合計・平均だけでなく、最大値やカウント(集計しない)など、様々な集計条件(メジャー)を選択できます。
ただし、ここで指定できるのは、基本的な条件だけ。
複雑な集計条件を設定するためには、DAXで自分で作成するか、クイックメジャーをうまく利用することになります。
フィールドの選択、メジャーの定義ができたら、書式アイコンを選択しましょう。
ここで、ビジュアルの書式を任意に変更することが可能です。

この書式については、毎月のアップデートで順次機能拡充されています。
分析アイコンは、時系列データの折れ線グラフによる予測や、散布図内での傾向線・定数線等の描写が利用できます。
ただし、分析アイコンが利用できないビジュアルも多いですので、注意してください。
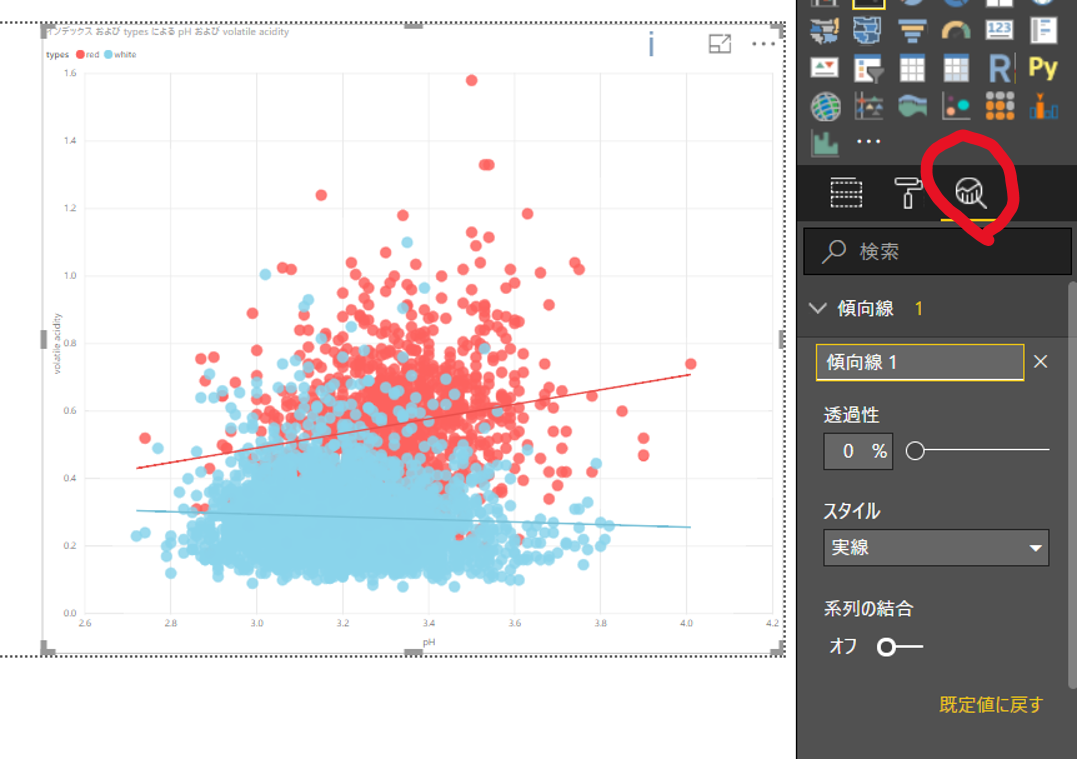
PowerBIビジュアルの特徴は、フィルターや強調などの表現がレポート内で連動し、インタラクティブに描写できることです。
スライサーといくつかのビジュアルを追加し、いろいろと操作してみると以下のとおり。

データを見ながら操作し、インサイトを得ることができるというBIの一番の利点です。
PowerBIカスタムビジュアルを作ってみよう
PowerBIは、様々な開発者が作成したカスタムビジュアルという標準以外のビジュアルを利用できることが特徴のひとつです。
カスタムビジュアルを利用するためには、ホームリボンから「カスタムビジュアル」の「Marketplaceから」を選択するのが一番シンプル。
いろいろなビジュアルが表示されるので、利用したいものを「追加」すれば、自動的に視覚化ウインドウに追加されます。
今回は、標準ビジュアルではサポートされていない「ヒストグラム」を選択します。
値に「alcohol」、頻度に「インデックス」を指定します。
「インデックス」の暗黙的なメジャーは、「カウント」を指定しましょう。

このカスタムビジュアルは一例。いろいろな魅力的なビジュアルを試してみましょう。
Pythonビジュアルを作ってみよう
では、ここからPythonビジュアルの話。
Pythonビジュアルの注意点
まずは住み分けについてですが、
「PowerBI標準ビジュアルでできることはなるべく標準ビジュアルで」を原則としましょう。
なぜか。
- インタラクティブな操作(フィルタ、強調)ができない
- 重い
- PowerBIServiceとの互換性がない
まず1点目のインタラクティブな操作について。
後ほど記述しますが、Pythonビジュアルをクリックしても、インタラクティブな操作はできません。
あくまで画像として認識されます。
BIの利点である、ビジュアルを操作しながらインサイトを得ることができません。
2点目。
**重いです。**数カラム、数千程度のデータ量かつ単純なビジュアルでも、表示までかなりの処理時間を要します。
もちろんPCスペックに依存すると思いますが、Pythonビジュアルで埋め尽くされたレポートなんか表示させようものなら・・・ゴクリ。
3点目。
まだプレビュー段階なので、PythonビジュアルはPowerBIDesktopでしかサポートされていません。
今後、Rのように共有できるようになることは想定されますが、まだ予定は未定です。
Pythonビジュアルのメリット
Pythonビジュアルのメリットは以下のとおり。
- matplotlib(特にseaborn)のようなグラフ描写ライブラリが利用できる
- データ加工した結果をビジュアル化できる
1点目。
Pythonではmatplotlibというビジュアルの描写ライブラリが大変高性能です。
さらに、イチからmatplotlibでビジュアルを作るのはなかなか骨が折れるのですが、
seabornというラッパーを利用し、簡単かつ綺麗な統計グラフを作ることができます。
PowerBIの標準orカスタムビジュアルに実装されていないビジュアルは自分で開発するしかないのですが、
Pythonビジュアルを利用することで、これを補完することができます。
2点目。
Pythonビジュアルを作成するスクリプトの中に、データ加工のスクリプトも埋め込めます。
したがって、わざわざデータモデルを作らなくてもビジュアル化できたりします。
※例として、「相関行列の作成→ヒートマップで表示」をこの後で掲載します。
Pythonビジュアルの作成
Pythonビジュアルを作成する際は、視覚化ウインドウの「Py」マークを選択します。
フィールドから、利用する変数を選択します。
選択した変数が、pandasのdataframe形式で「dataset」という変数に格納される仕組みです。
変数を選択する際、暗黙のメジャーに注意してください。
メジャーで集計された値をもってきてしまうと、正しく計算されません。
原則として「集計しない」を選択するようにしましょう。
Pythonビジュアルのサンプルコードと結果
実際に、PowerBI標準・カスタムビジュアルでは難しいケド、
データ分析にあたってよく使うおすすめビジュアルを実装してみたいと思います。
なお、上述したとおり、matplotlibでイチから作図していくのは玄人向け。
今回はseabornを利用して簡単ビジュアライゼーションします。
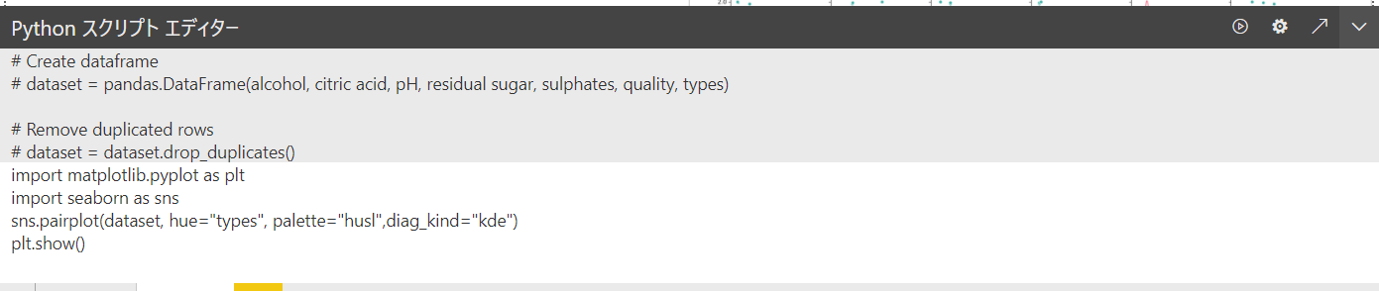
散布図行列図
多変数の関係性を視覚化するのにとても便利な散布図行列図です。
行列2変数の散布図と、各変数の分布図を可視化できます。
どのデータに相関があるのか?カテゴリごとに分布や相関に差異があるのか?を確認することができます。

import matplotlib.pyplot as plt
import seaborn as sns
sns.pairplot(dataset, hue="types", palette="husl",diag_kind="kde")
plt.show()
相関行列ヒートマップ
上記散布図行列図と似ていますが、各変数の相関をヒートマップで表現しています。
ポイントは、Pythonビジュアルスクリプト内でデータモデルから相関行列を計算していること。
わざわざこのためにデータモデルを持ったり、独自にメジャーをつくる必要はありません。
※実はカスタムビジュアルに同種のものがありますが、役に立つのでこちらで紹介しました。

import matplotlib.pyplot as plt
import seaborn as sns
corr = dataset.corr() #ここでデータセットの相関行列を算出
sns.heatmap(corr, square=True,annot=True,cmap="coolwarm")
plt.show()
カーネル密度分布
やたら便利なカーネル密度推定。
データから確率密度関数を推定して描写してくれます。
乱暴に言ってしまえば、データのおおまかな分布図をなだらかに描写してくれます。
ヒストグラムだと凸凹してわかりづらい特徴も、
これを使えば分布の差異を際立たせることができます。

import matplotlib.pyplot as plt
import seaborn as sns
g = sns.FacetGrid(dataset,hue="types", aspect=3)
g.map(sns.kdeplot, "alcohol", shade=True)
g.add_legend()
plt.show()
ファクタープロット
日本語名無いと思うんですが、"factorplot"も便利です。
カテゴリ変数と連続変数の分布を可視化してくれます。
カテゴリ変数ごとの分布の特徴を可視化できるので、これも大変便利なビジュアル。

import matplotlib.pyplot as plt
import seaborn as sns
sns.factorplot("quality","pH",data=dataset,hue="types",palette="hls")
plt.show()
Pythonビジュアルの挙動
Pythonビジュアルは、ビジュアル自体をクリック等で操作することはできません。
ただし、以下のようにスライサーでフィルタをかけたりすることは可能です。
(ビジュアルによりますが、挙動はだいぶ重いです。)
この特徴をうまく使えば、Pythonビジュアルを比較的柔軟に運用することができるかもしれませんね。

おわりに
PowerBIの標準・カスタムビジュアル、Pythonビジュアル
それぞれの長所をうまく活用して、PowerBIレポートの作成を楽しみましょう!