はじめに
もしかして **「え?MATLAB で言語処理やるの??」**と思いました・・?(6回目)
言語処理 100 本ノック 2020 で MATLAB の練習をするシリーズ。今回は第4章: 形態素解析です.
一部都合よく問題文を読み替えていますがご容赦ください。気になるところあれば是非コメントください。
実行環境
- MATLAB R2020a (Windows 10)
- Text Analytics Toolbox
- Statistics and Machine Learning Toolbox
**Livescript 版(MATLAB)は GitHub: NLP100-MATLAB1 に置いてあります。**そしてノックを一緒にやってくれる MATLAB 芸人は引き続き募集中です!詳細は GitHub の方で。
他章へのリンク
- 第 1 章: 準備運動
- 第 2 章: UNIX コマンド
- 第 3 章: 正規表現
- 第 4 章: 形態素解析(この記事)
- 第 6 章: 機械学習 part 1
- 第 6 章: 機械学習 part 2
- 第 7 章: 単語ベクトル
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
まずは,お題の通りにMeCabを使って形態素解析を行います.Text Analytics Toolbox を使ってもよいのですが,とりあえず言われるとおりにスタンドアロンのMeCabをつかってやってみます.(MeCabはインストール済とします.)
mecabCommand = '"C:\Program Files (x86)\MeCab\bin\mecab.exe"';
inputFile = 'nekoSJIS.txt';
outputFile = 'neko.txt.mecab';
system(sprintf('%s %s -o %s',mecabCommand,inputFile,outputFile));
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
Text Analytics Toolboxを使うと,tokenizedDocument オブジェクトが対応する「マッピング型」になりますか.ただし,MeCabの品詞細分類の情報が必要なので,ちょっと工夫がいります.このあたりはこちらの記事もご参考にどうぞ
str = fileread("neko.txt");
str = splitlines(str);
mecabOpt = mecabOptions("LemmaExtractor",@(~,info) info.Feature);
docs = tokenizedDocument(str,'TokenizeMethod',mecabOpt);
トークンの詳細表を作成します.
tknsOrg = tokenDetails(docs);
head(tknsOrg)
| Token | DocumentNumber | LineNumber | Type | Language | PartOfSpeech | Lemma | Entity | |
|---|---|---|---|---|---|---|---|---|
| 1 | "一" | 1 | 1 | letters | ja | numeral | "名詞,数,,,,,一,イチ,イ... | non-entity |
| 2 | "吾輩" | 3 | 1 | letters | ja | pronoun | "名詞,代名詞,一般,,,*,吾輩,... | non-entity |
| 3 | "は" | 3 | 1 | letters | ja | adposition | "助詞,係助詞,,,,,は,ハ,... | non-entity |
| 4 | "猫" | 3 | 1 | letters | ja | noun | "名詞,一般,,,,,猫,ネコ,... | non-entity |
| 5 | "で" | 3 | 1 | letters | ja | auxiliary-verb | "助動詞,,,*,特殊・ダ,連用形,... | non-entity |
| 6 | "ある" | 3 | 1 | letters | ja | auxiliary-verb | "助動詞,,,*,五段・ラ行アル,基... | non-entity |
| 7 | "。" | 3 | 1 | punctuation | ja | punctuation | "記号,句点,,,,,。,。,。... | non-entity |
| 8 | "名前" | 4 | 1 | letters | ja | noun | "名詞,一般,,,,,名前,ナマ... | non-entity |
tkns.Lemma の所に,MeCabの生出力が出てますね.そこで,ここの情報を使ってトークン表を少し書き換えます.
まず,MeCabの品詞分類情報(tkns.Lemma)の最大項目数,トークン表の行数を取得し,品詞情報を格納する配列 posArray を用意します.
nPos = 9; % MeCabの品詞分類出力の列数(固定値)
nDocs = height(tknsOrg); % トークン表の行数
posArray = repmat("",nDocs,nPos); % 品詞情報を格納する配列を用意します.
次に,tkns.Lemma を1行ずつ分割して posArray を埋めてゆきます.
for kk = 1:nDocs
[splitPOS,nPOS] = split(tknsOrg.Lemma(kk),',');
posArray(kk,1:numel(nPOS)+1) = splitPOS;
end
現在のトークン表をコピーして出力トークン表を作成し,posArray の内容を加えていきます.
tkns = tknsOrg(:,{'DocumentNumber','LineNumber'});
tkns.surface = tknsOrg.Token;
tkns.base = posArray(:,7);
tkns.POS = categorical(posArray(:,1));
tkns.POS1 = categorical(posArray(:,2));
head(tkns)
| DocumentNumber | LineNumber | surface | base | POS | POS1 | |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | "一" | "一" | 名詞 | 数 |
| 2 | 3 | 1 | "吾輩" | "吾輩" | 名詞 | 代名詞 |
| 3 | 3 | 1 | "は" | "は" | 助詞 | 係助詞 |
| 4 | 3 | 1 | "猫" | "猫" | 名詞 | 一般 |
| 5 | 3 | 1 | "で" | "だ" | 助動詞 | * |
| 6 | 3 | 1 | "ある" | "ある" | 助動詞 | * |
| 7 | 3 | 1 | "。" | "。" | 記号 | 句点 |
| 8 | 4 | 1 | "名前" | "名前" | 名詞 | 一般 |
できましたね.
31. 動詞
動詞の表層形をすべて抽出せよ.
テーブルtknsのPOS列が動詞であるものの表層形を抽出するのですから次のようになります.
verbs = tkns.surface(tkns.POS=="動詞")
verbs = 28907x1 string
"生れ"
"つか"
"し"
"泣い"
"し"
"いる"
"始め"
"見"
"聞く"
"捕え"
32. 動詞の原形
動詞の原形をすべて抽出せよ.
これも基本的には前問と同様です.
verbsBase = tkns.base(tkns.POS=="動詞")
verbsBase = 28907x1 string
"生れる"
"つく"
"する"
"泣く"
"する"
"いる"
"始める"
"見る"
"聞く"
"捕える"
33. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
まず,単語「の」を表す論理配列と,「POSが名詞である語」を表す論理配列を用意します.
次にこれらの論理配列を一つづつずらして論理積を取ることで,名詞-の-名詞の組み合わせを抽出するための論理配列が得られます.これを用いて当該単語を連結することで目的を達することができます.
lidx1 = strcmp("の",tkns.surface);
lidx2 = tkns.POS=="名詞";
lidx = lidx2(1:end-2) & lidx1(2:end-1) & lidx2(3:end);
idx = find(lidx);
nounPhrase = tkns.surface(idx)+tkns.surface(idx+1)+tkns.surface(idx+2)
nounPhrase = 6040x1 string
"彼の掌"
"掌の上"
"書生の顔"
"はずの顔"
"顔の真中"
"穴の中"
"書生の掌"
"掌の裏"
"何の事"
"肝心の母親"
34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
基本は名詞の抽出から.
lidx = tkns.POS=="名詞";
連続して出現しているということは,単独ではないということ.単独である条件は,両側が名詞ではないこと.
lidxIso = (~[false; lidx(1:end-1)]&~[lidx(2:end);false]);
なので,資格のある名詞は
lidx = lidx & ~lidxIso;
資格のない言葉を全て空白で置き換えて,全体を一つの文字列にしてから,正規表現で抽出というのはどうでしょう.
strContNoun = tkns.surface;
strContNoun(~lidx)= ' ';
strContNoun = char(join(strContNoun,''));
contNoun = string(regexp(strContNoun,'[^\s]+','match'))'
contNoun = 7188x1 string
"一吾輩"
"人間中"
"一番獰悪"
"時妙"
"一毛"
"その後猫"
"一度"
"ぷうぷうと煙"
"邸内"
"三毛"
もう少しエレガントなやり方もありそうなものですが・・・
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
これは,Bag-of-words モデルそのもの.
bow = bagOfWords(docs)
bow =
bagOfWords のプロパティ:
Counts: [9965x13580 double]
Vocabulary: [1x13580 string]
NumWords: 13580
NumDocuments: 9965
関数 topkwords で,頻出K単語の降順テーブルを作ってくれます.全ての単語の出現頻度を知りたければ,引数Kに,全単語数を入れればOK.
bowTable = topkwords(bow,bow.NumWords)
| Word | Count | |
|---|---|---|
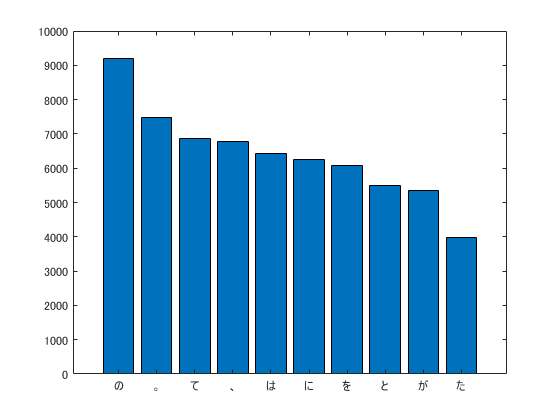
| 1 | "の" | 9194 |
| 2 | "。" | 7486 |
| 3 | "て" | 6868 |
| 4 | "、" | 6772 |
| 5 | "は" | 6420 |
| 6 | "に" | 6243 |
| 7 | "を" | 6071 |
| 8 | "と" | 5508 |
| 9 | "が" | 5337 |
| 10 | "た" | 3988 |
| 11 | "で" | 3806 |
| 12 | "「" | 3231 |
| 13 | "」" | 3225 |
| 14 | "も" | 2479 |
36. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
ここは素直にそのまま
bar(bowTable.Count(1:10));
set(gca,'XTickLabel',bowTable.Word(1:10));
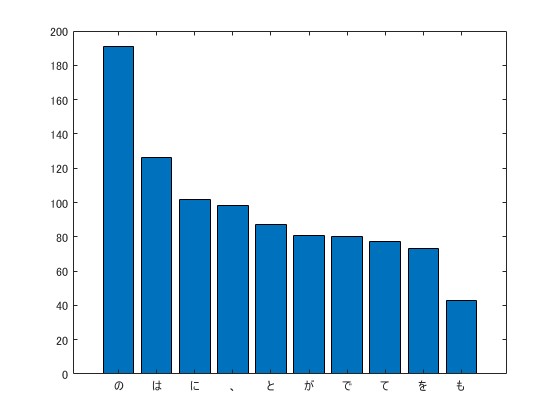
37. 「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
「共起」を考える際は,コンテクストのスパンを指定する必要があるのですが,ここでは17語(文書の長さのメディアン値+1)にしておきます(特に深い意味はありません.)
まず,context 関数を用いて「猫」を含むコンテクストを抽出します.
halfSpan = 8;
coWords = context(docs,"猫",2*halfSpan+1)
| Context | Document | Word | |
|---|---|---|---|
| 1 | " 吾輩 は 猫 ... | 3 | 3 |
| 2 | " その後 猫 ... | 16 | 2 |
| 3 | "向け て この 宿 なし の 小 猫 ... | 66 | 18 |
| 4 | " 吾輩 は 猫 ... | 87 | 3 |
| 5 | " て い て 勤まる もの なら 猫 ... | 90 | 9 |
| 6 | " 方 が 質 が わるい — — 猫 ... | 104 | 15 |
| 7 | " わるい — — 猫 が 来 た 猫 ... | 104 | 19 |
| 8 | " た 上 、 どうしても 我 等 猫 ... | 117 | 18 |
| 9 | " まあ 気 を 永く 猫 ... | 128 | 5 |
| 10 | " 吾輩 は 猫 ... | 171 | 3 |
| 11 | " 造作 と いい あえて 他 の 猫 ... | 172 | 15 |
| 12 | " 吾輩 は 波 斯産 の 猫 ... | 175 | 6 |
| 13 | " 所 さえ 見え ない から 盲 猫 ... | 180 | 27 |
| 14 | "ら 盲 猫 だ か 寝 て いる 猫 ... | 180 | 33 |
コンテキストとして抽出した文 coWords.Context は単語が空白で区切られた文字列になっているので,これらの単語を空白で分割して文字列配列に格納します.また,余分な空文字列""と,単語"猫"を除去します.
wordCat = coWords.Context;
tmp = arrayfun(@(x) split(x,' ')',wordCat,'UniformOutput',false);
tmp = [tmp{:}]; % セル配列を文字列配列に変換
tmp = tmp( tmp~="" & tmp~="猫"); % 空文字列および"猫"の除去
wordCat = tmp;
bowCat = bagOfWords(wordCat);
bowCatTable = topkwords(bowCat,10);
bar(bowCatTable.Count);
set(gca,'XTickLabel',bowCatTable.Word);
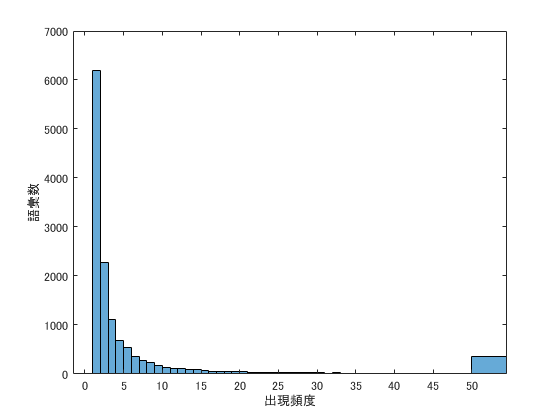
38. ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
殆どの単語の出現頻度は数回なので,ヒストグラムのビンを出現頻度の低いところに集中させています.出現頻度50回以上の単語数は,一つのビンにまとめて表示させています.
histogram(bowTable.Count,[1:50 Inf]);
xlabel('出現頻度');
ylabel('語彙数');
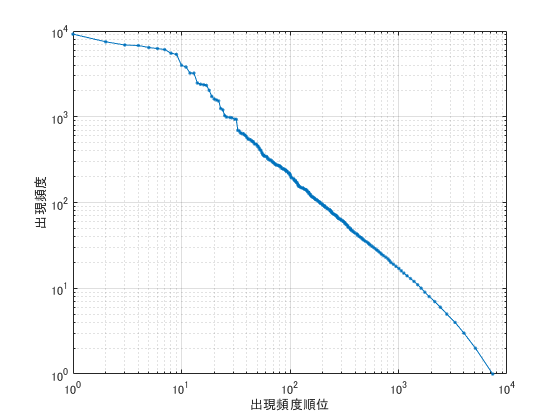
39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
順位を得るために,関数uniqueを使ってbowTable.Countから出現頻度がユニークなものを取り出します.オプションstableを使うことで,データの並び順を変えずに一意のデータを抽出することができます.
idxOrg = 1:height(bowTable);
[~, idxOrder] = unique(bowTable.Count,'stable');
loglog(idxOrg(idxOrder),bowTable.Count(idxOrder),'.-');
grid on;
xlabel('出現頻度順位');
ylabel('出現頻度')
上位10位の単語は「 "の","。","て","、","は","に","を","と","が","た"」といった機能語だからでしょうか,Zipfの法則には乗っていませんね.
-
Livescript から markdown への変換は livescript2markdown: MATLAB's live scripts to markdown を使っています。 ↩