はじめに
MATLABのText Analytics Toolboxでは日本語の形態素解析器としてMeCabが使われていますが,結果として得られる単語1の品詞(POS,Part of Speech)は15種類しかありません.品詞情報を用いて単語の選別を行う際に,MeCabが提供するきめ細かい品詞情報を(69種)を使えないのはなんとも勿体ないなあと思い,あれこれ探っているうちにそれっぽいことができたので紹介します.
(2020年4月16日追記: ここで紹介している方法よりも,もっと簡単で便利な方法が見つかりました.よろしかったらこちらの記事をご覧ください.)
環境と必要なツールボックス
MATLAB R2020a
Text Analytics Toolbox
MATLABが出力するPOS
'adjective'
'adposition'
'adverb'
'auxiliary-verb'
'coord-conjunction'
'determiner'
'interjection'
'noun'
'numeral'
'pronoun'
'proper-noun'
'punctuation'
'symbol'
'verb'
'other'
MeCabが出力するPOS情報と品詞ID[^2]
| 品詞 | ID |
|---|---|
| その他,間投,\,\ | 0 |
| フィラー,*,*,* | 1 |
| 感動詞,*,*,* | 2 |
| 記号,アルファベット,*,* | 3 |
| 記号,一般,*,* | 4 |
| 記号,括弧開,*,* | 5 |
| 記号,括弧閉,*,* | 6 |
| 記号,句点,*,* | 7 |
| 記号,空白,*,* | 8 |
| 記号,読点,*,* | 9 |
| 形容詞,自立,*,* | 10 |
| 形容詞,接尾,*,* | 11 |
| 形容詞,非自立,*,* | 12 |
| 助詞,格助詞,一般,* | 13 |
| 助詞,格助詞,引用,* | 14 |
| 助詞,格助詞,連語,* | 15 |
| 助詞,係助詞,*,* | 16 |
| 助詞,終助詞,*,* | 17 |
| 助詞,接続助詞,*,* | 18 |
| 助詞,特殊,*,* | 19 |
| 助詞,副詞化,*,* | 20 |
| 助詞,副助詞,*,* | 21 |
| 助詞,副助詞/並立助詞/終助詞,*,* | 22 |
| 助詞,並立助詞,*,* | 23 |
| 助詞,連体化,*,* | 24 |
| 助動詞,*,*,* | 25 |
| 接続詞,*,*,* | 26 |
| 接頭詞,形容詞接続,*,* | 27 |
| 接頭詞,数接続,*,* | 28 |
| 接頭詞,動詞接続,*,* | 29 |
| 接頭詞,名詞接続,*,* | 30 |
| 動詞,自立,*,* | 31 |
| 動詞,接尾,*,* | 32 |
| 動詞,非自立,*,* | 33 |
| 副詞,一般,*,* | 34 |
| 副詞,助詞類接続,*,* | 35 |
| 名詞,サ変接続,*,* | 36 |
| 名詞,ナイ形容詞語幹,*,* | 37 |
| 名詞,一般,*,* | 38 |
| 名詞,引用文字列,*,* | 39 |
| 名詞,形容動詞語幹,*,* | 40 |
| 名詞,固有名詞,一般,* | 41 |
| 名詞,固有名詞,人名,一般 | 42 |
| 名詞,固有名詞,人名,姓 | 43 |
| 名詞,固有名詞,人名,名 | 44 |
| 名詞,固有名詞,組織,* | 45 |
| 名詞,固有名詞,地域,一般 | 46 |
| 名詞,固有名詞,地域,国 | 47 |
| 名詞,数,*,* | 48 |
| 名詞,接続詞的,*,* | 49 |
| 名詞,接尾,サ変接続,* | 50 |
| 名詞,接尾,一般,* | 51 |
| 名詞,接尾,形容動詞語幹,* | 52 |
| 名詞,接尾,助数詞,* | 53 |
| 名詞,接尾,助動詞語幹,* | 54 |
| 名詞,接尾,人名,* | 55 |
| 名詞,接尾,地域,* | 56 |
| 名詞,接尾,特殊,* | 57 |
| 名詞,接尾,副詞可能,* | 58 |
| 名詞,代名詞,一般,* | 59 |
| 名詞,代名詞,縮約,* | 60 |
| 名詞,動詞非自立的,*,* | 61 |
| 名詞,特殊,助動詞語幹,* | 62 |
| 名詞,非自立,一般,* | 63 |
| 名詞,非自立,形容動詞語幹,* | 64 |
| 名詞,非自立,助動詞語幹,* | 65 |
| 名詞,非自立,副詞可能,* | 66 |
| 名詞,副詞可能,*,* | 67 |
| 連体詞,*,*,* | 68 |
MATLABが品詞情報(POS,Part of Speech)を出力する仕組み
形態素解析を行うときにMATLABはMeCabを走らせますが,この際にMeCabが吐き出す品詞ID(69種)を内部の変数に保持します.そしてその情報を関数 textanalytics.ja.mecabToPOS.m に渡してMATLABの出力するPOS(15種)にマッピングしています.このマッピング関数を自前のものに置き換えてしまえば,MeCabの出力をもっと柔軟に扱えるようになります.
実際,MATLABにはこのマッピング関数を置き換えるためのオプションが用意されています.まず,mecabOptions オブジェクトを生成します.このときに,POSExtractorプロパティに自前のマッピング関数(ここではmyPOSExtractor)のハンドルを指定します.あとは,形態素解析を行うときにtokenizedDocumentのオプション'TokenizeMethod'として,先ほど生成したmecabOptions オブジェクトを渡せば自前のマッピング関数を用いたPOSが出力されます.
mecabOpt = mecabOptions('POSExtractor',@myPOSExtractor);
tokens = tokenizedDocument(str,'TokenizeMethod',mecabOpt);
マッピング関数の作成
それでは,自前のマッピング関数を作成しましょう.MATLABがデフォルトで使うマッピング関数は,textanalytics.ja.mecabToPOS.m ですので,このファイルのありかをwhich コマンドで探してローカルフォルダにコピーします2 (ここではファイル名はmyPOSExtractor.m としてあります.適宜変更してください.)
arika = which('textanalytics.ja.mecabToPOS');
system(['copy "' arika '"' ' myPOSExtractor.m'])
コピーしたら,最初の行の関数名をファイル名に変更しておきます.
マッピング関数の中身(抜粋)
function newpartOfSpeechTags = myPOSExtractor(~,info)
%
% ・・・中略・・・
%
partOfSpeechTags = info.PartOfSpeech;
newpartOfSpeechTags = categorical(partOfSpeechTags, 0:68, ...
{'interjection',... % 0
'other',...
'interjection',...
'symbol',...
'symbol',...
'punctuation',...
'punctuation',...
%
% ・・・ 中略 ・・・
%
'noun',...
'noun',...
'noun',...
'noun',...
'noun',...
'noun',...
'adjective'});
end
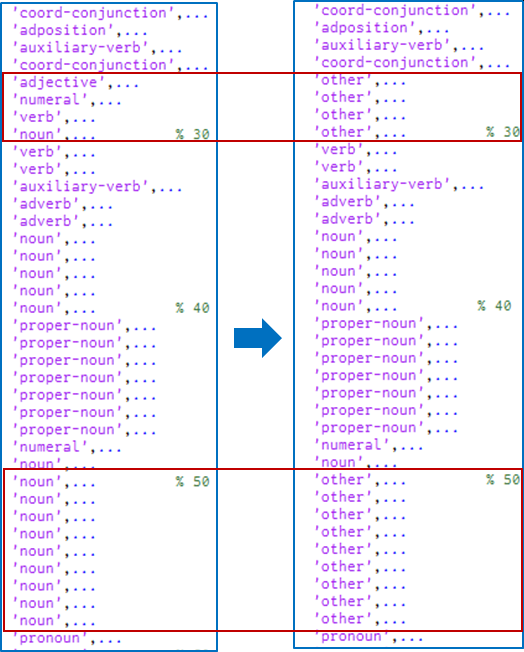
ですので,このセル配列の中身を書き換えることで自前のマッピング関数を作ることができます.例えば,「名詞を抽出したいけれども,接頭辞・接尾辞は要らない」といった場合を考えます.「名詞,接頭,...」「名詞,接尾,...」に対応するMeCabの品詞IDは27~30,50~58になりますので,セル配列の対応する要素3を'other'4に書き換えます.こうすることで,これらの品詞IDに対応する単語のPOSが'other'として出力されるようになります.
セル配列の中身の置き換え
サンプル
サンプルとして,「お宅のお坊ちゃまお元気?」を形態素解析し,その中からPartOfSpeechが'noun' であるものを抽出します.まずは,デフォルト設定.
str = "お宅のお坊ちゃまお元気?"
tkn0 = tokenDetails(tokenizedDocument(str));
tkn0(tkn0.PartOfSpeech=='noun',:)
| Token | DocumentNumber | LineNumber | Type | Language | PartOfSpeech | Lemma | Entity |
|---|---|---|---|---|---|---|---|
| "お" | 1 | 1 | letters | ja | noun | "お" | non-entity |
| "宅" | 1 | 1 | letters | ja | noun | "宅" | non-entity |
| "お" | 1 | 1 | letters | ja | noun | "お" | non-entity |
| "坊" | 1 | 1 | letters | ja | noun | "坊" | non-entity |
| "お" | 1 | 1 | letters | ja | noun | "お" | non-entity |
| "元気" | 1 | 1 | letters | ja | noun | "元気" | non-entity |
「お」がnounとして入ってしまっていますね.普通に品詞でフィルターをかけようとするときにノイズとして紛れ込むやっかいなやつです.次に,上で作った自前のマッピング関数を使ってみます.
mecabOpt = mecabOptions('POSExtractor',@myPOSExtractor);
tkn1 = tokenDetails(tokenizedDocument(str,'TokenizeMethod',mecabOpt));
tkn1(tkn1.PartOfSpeech=='noun',:)
| Token | DocumentNumber | LineNumber | Type | Language | PartOfSpeech | Lemma | Entity |
|---|---|---|---|---|---|---|---|
| "宅" | 1 | 1 | letters | ja | noun | "宅" | non-entity |
| "坊" | 1 | 1 | letters | ja | noun | "坊" | non-entity |
| "元気" | 1 | 1 | letters | ja | noun | "元気" | non-entity |
狙ったとおり,接頭辞の「お」を排除することができました.
おわりに
mecabOptions の POSExtractor オプションに自前のマッピング関数を設定することで,MeCabの持つ豊富な品詞情報を利用できました.ここで紹介した方法は,最も単純なやり方ですので,もっと複雑なやり方もできるかと思います.
難点は,MATLAB側でPOSとして受け付ける文字列の内容が固定されているて,どんなに頑張っても15種類の出力しか得られない点でしょうか.力業で,POS 抽出関数を複数(例えば名詞用・形容詞用など)用意しておくという手もありますが,その分形態素解析の回数が増えるのであまりうれしいやり方ではないですね.