20210914 初稿
20210914 SimCLRを中心に修正
20210915 InfomationBottleneckについて追記
20211014 CVPRではなくICML2021でした。指摘を頂き修正しました。@theta さんありがとうございました。
1.概要
- 自己教師あり学習 Barlow Twins(ICML2021)の関連リンクとメモです。ちょこちょこ追記していく予定です。
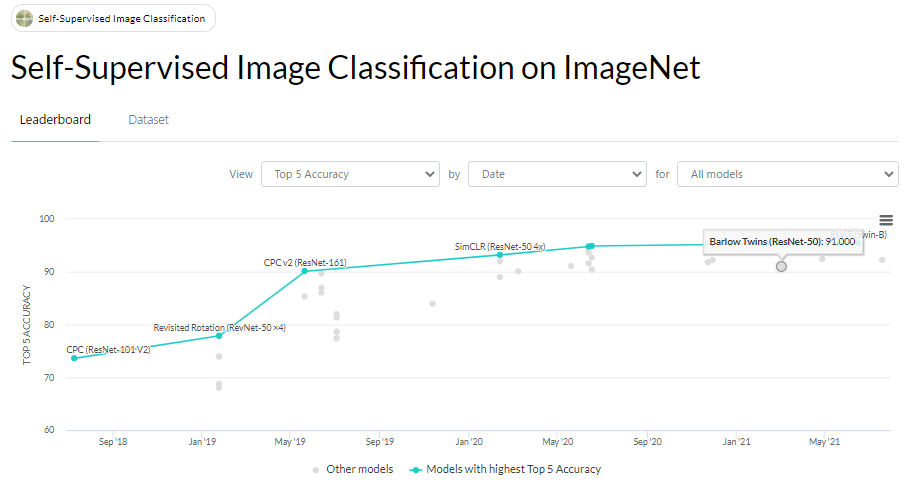
- 先行研究と比較することで、扱いやすいのにSoTAと並ぶ性能が出せる優れた手法だということが分かりました。
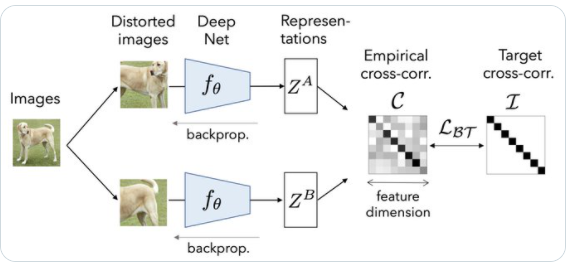
2.ところでBarlowって何ですか?
人です。大昔に本物の神経細胞の分野で「冗長性を削減するモデル」を提唱したのだそうです。
ピッタリの命名ですね。
あと進化論のダーウィンの曾孫。
Barlow(1959)は脳が段階的に(階層性のある処理で)冗長性を削減するモデルを提示し,さらに情報理論的に最適な表現を生成する(optimal coding)のが感覚情報処理だとしてモデル化することを提唱している.この論文ではCraik(1943)9)を引いて,情報理論的に最適な表現は環境のモデルになっていることも議論されている.
2020年に亡くなったのもこの名前に影響しているのかも。
↓は訃報を知らせる記事から。HoraceはBarlow氏のファーストネームです。先見性ありすぎ。活躍している期間長すぎ。
感覚経路の冗長性と相関する活動のアイデアは、「教師なし学習」に関する彼の非常に影響力のある論文の根底にあります(Neural Comput。(1989)1、295–311)。この論文は、教師あり学習や強化学習ではなく、教師なし学習の重要性に最初に注目したものの1つです。教師なし学習は、神経系(または実際には人工知能)が「統計的規則性」または入力のパターンをどのように認識するかについてであり、皮質を理解するために基本的に重要です。Horaceは、Tolmanの「認知地図」やCraikの「作業モデル」などの古いアイデアを現代のエントロピーの概念と結び付け、感覚信号の冗長性がこれらの地図に組み込まれた知識を提供すると結論付けました。このような知識により、予期しない不一致を即座に特定して対処することができます。Horaceの情報理論ベースのアプローチは、ニューラルネットワークおよびベイズ学習における教師なし学習への多くの最新のアプローチの根底にあります。
3.自己教師あり学習で起きる問題
ここからはJure(ユーリと読むらしい)さん本人の解説動画のキャプチャを軸にいろいろ足しています。
- 人によるアノテーションなしで「役に立つ」表現に変換したいというのがモチベーションです。ここでの「役に立つ」というのは、作った表現を画像分類、物体検出、インスタンスセグメンテーションといったタスクに転移学習で使えるということです。
- よくやられるのが、ネットワークのペアに別の雑音を入れた画像を入れることです。
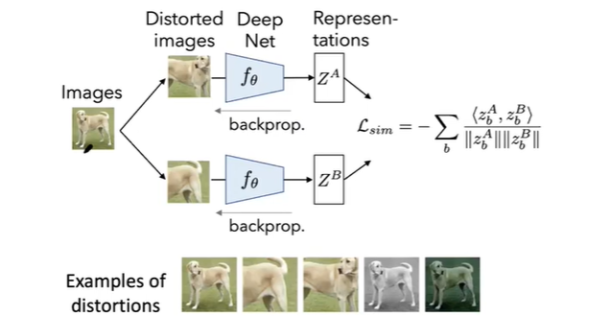
- すると得られる解はトリビアルなものになってしまうという問題が発生します。この場合はLossを-1にするためにベクトル$Z_A$と$Z_B$の全部成分が1になってしまいました。このトリビアルな解になってしまう現象をCollapseと呼ぶそうです。
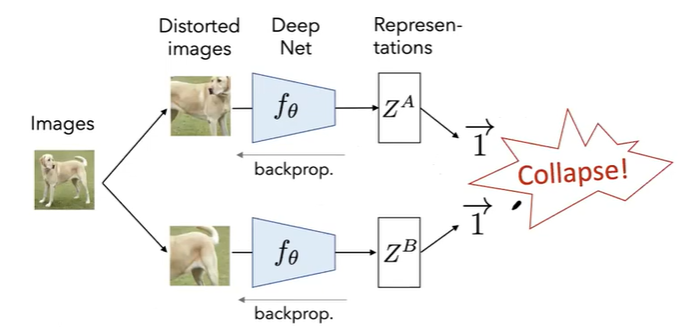
4.先行研究
このCollapseを回避する先行研究達です。
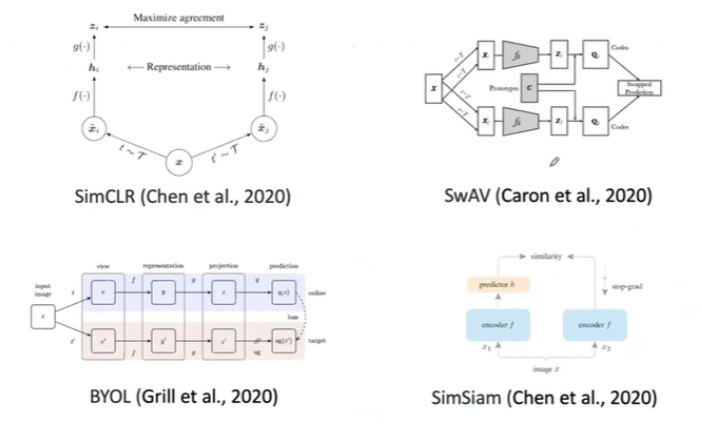
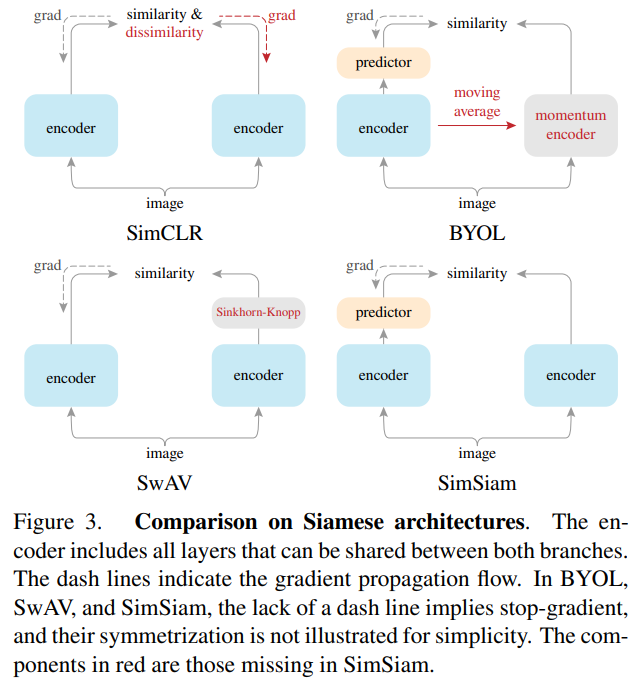
SimSiam視点の比較画像もありました。個人的にはこれが分かりやすいです。
4-1.SimCLR:A Simple Framework for Contrastive Learning of Visual Representations(2020/2)
-
Contrastive Learning(対照学習) の代表的な手法です。
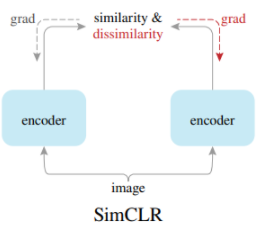
-
Lossの変更で対処します。Negative Sampleを使います。
違う画像同士ではコサイン類似度が-1になって、同じ画像なら1になることを目指します。
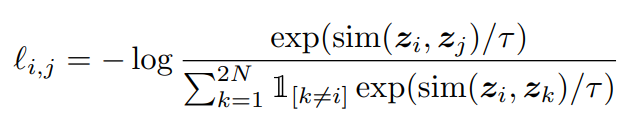

-
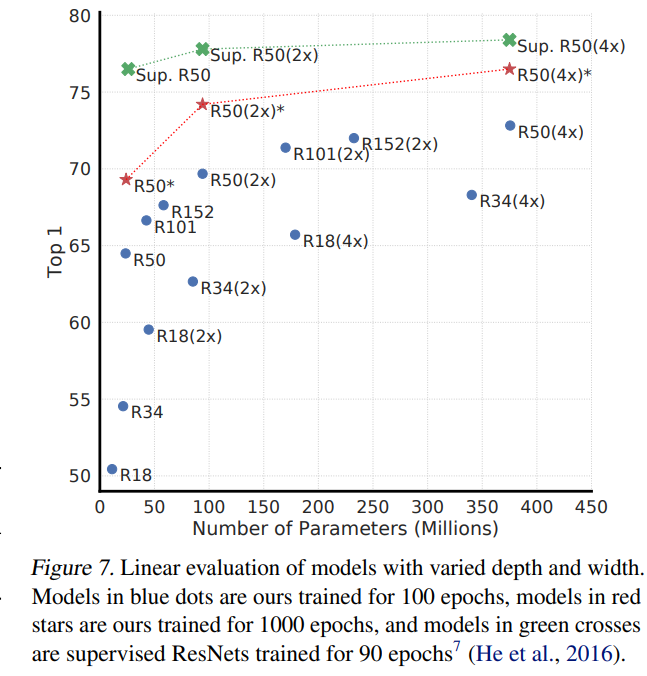
画像分類で教師ありに並ぶような性能。
-
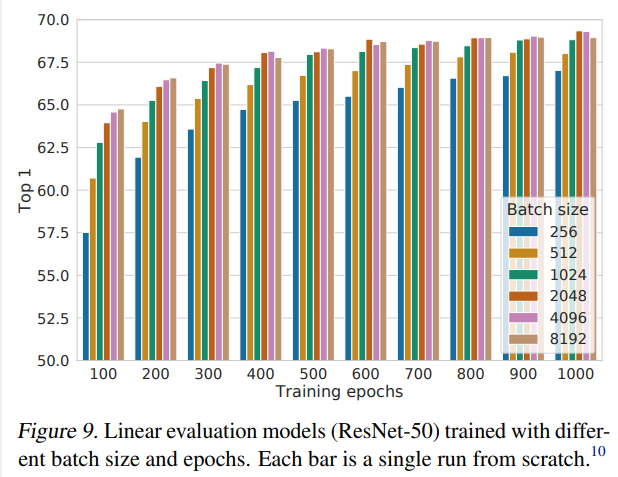
Negative Sampleが要るのでバッチサイズとエポック数がエグいです。
4-2.BYOL:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning(2020/6)
- Lossではなくアーキテクチャの変更で対処します。
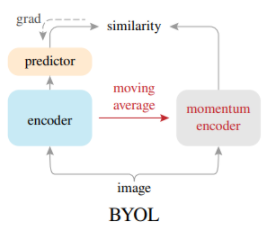
- 画像分類タスクでSimCLRを上回りました。
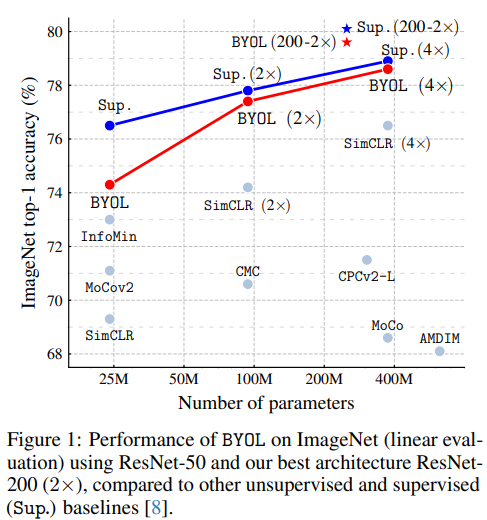
- Negative Sampleが要りません。なので(?)バッチサイズの影響を受けにくいです。
- 逆伝搬によるウェイトの更新は片方だけします。もう片方は更新されたウェイトにExponential Moving Average($\tau$でカットオフ周波数が決まる1次のローパスフィルタ)をかけたものにします。これはこれで遅いです。
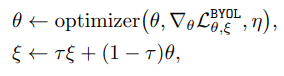
4-3.SimSiam: Exploring Simple Siamese Representation Learning(2020/11)
- アーキテクチャの変更で対処しました。
- Negative Sampleが要りません。
- Exponential Moving Averageが要りません。
- ウェイトは2つパスで共通にして、片方にpredictor(MLPのヘッド)を追加して対称性を崩しています。
- と思いきや、反対側につけたものも計算して平均しています。

とはいえ、だいぶシンプルな方法になってきました。
5.Barlow Twins: Self-Supervised Learning via Redundancy Reduction(2021/03)
このあたりからはこちらの動画のキャプチャが多いです。
5-1.特徴
- SimCLRに近いLossを工夫するアプローチです。
- だけどNegative Sampleが要りません。
- アーキテクチャを変更しません。
- Exponential Moving Averageが要りません。
5-2.方法
- 方針
本物の神経がとっている戦略をニューラルネットワークに真似させます。
つまり、Barlowが唱える説のように特徴量(ニューロン)に対して冗長性の削減を要求します。
①data augmentation に対して不変(augumentationをかけても同じ成分同士の相関が1)
これくらい変化をしても区別して表現せず、犬は犬だと思いなさいということ。

②それぞれの特徴量は独立(別の成分同士の相関が0)
二つ以上の成分で同じことを表現するのは無駄なのでやってはいけません。
-
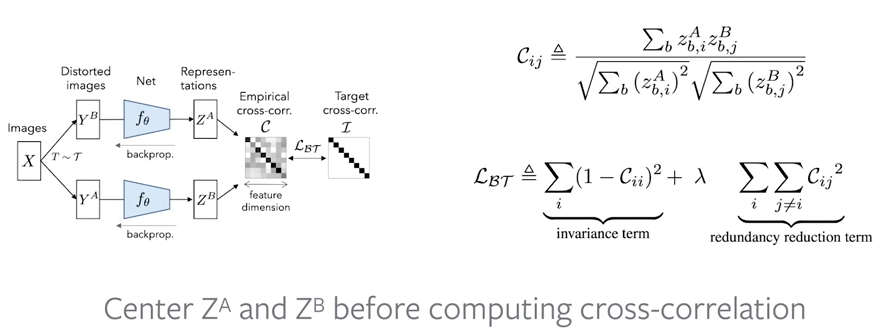
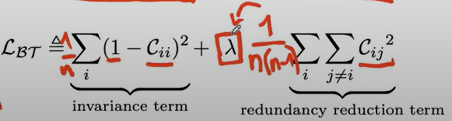
図解と定式化したのがこちらです。$i$は特徴量ベクトルの成分、$b$はバッチ方向の成分を表します。
$C_{ii}$の各成分が特徴量の各成分同士の相関を表します。
あと、計算を簡単にするために平均0の分布にしています。
-
疑似コードに次元を書いてくれているのでわかりやすいです。

-
ネットワークはこれ。

-
非対角項が多いので素直にやるとベクトルの全成分がゼロに向かう。ラムダで調整している。
ユーリさんはこんな感じで書いている。
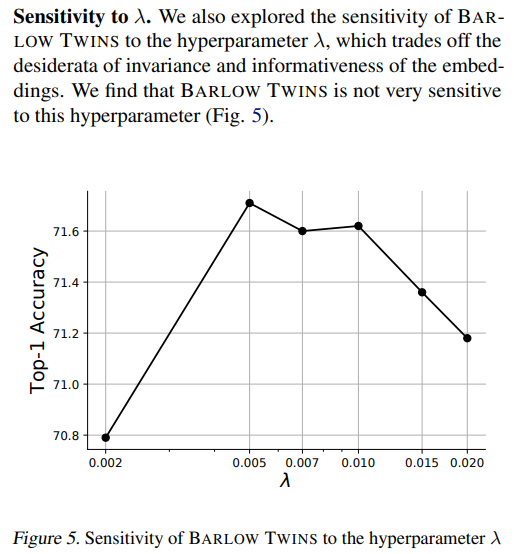
実際には、探索で決めています。特徴量ベクトルの次元の逆数に対して非対角成分は結構大きめです。
5-3.結果
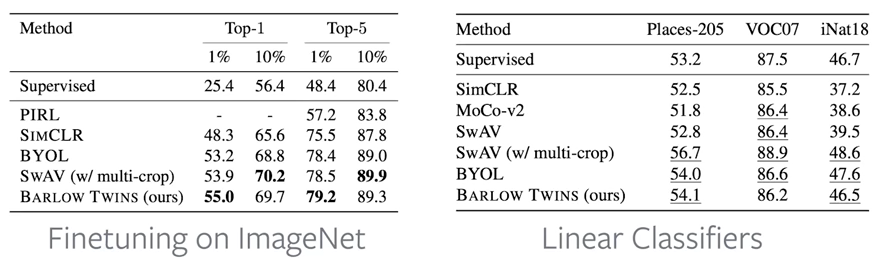
- 転移学習でSOTAに並ぶ性能です。
- imagenetの1%、10%の画像で(ラベルありの)finetune
- バックボーンを固定して線形分離機だけ学習
- 細かい学習の条件は論文の付録C
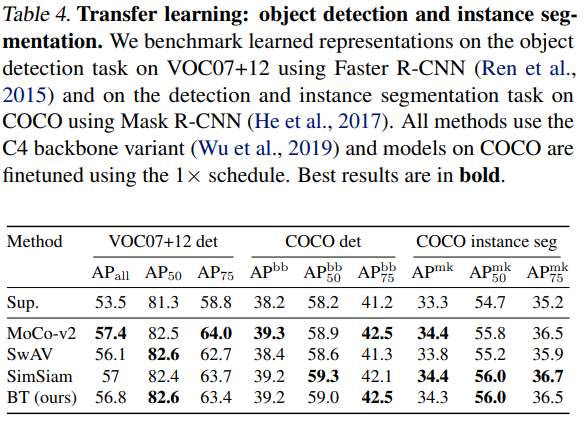
- 物体検出の転移学習に使うなら、supervisedを使うより良いみたいですね。
- バッチサイズが小さくてもいいです。
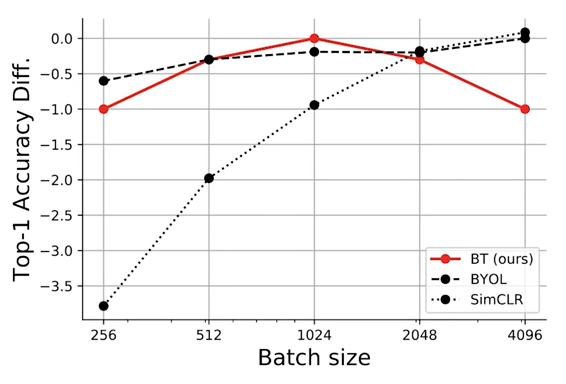
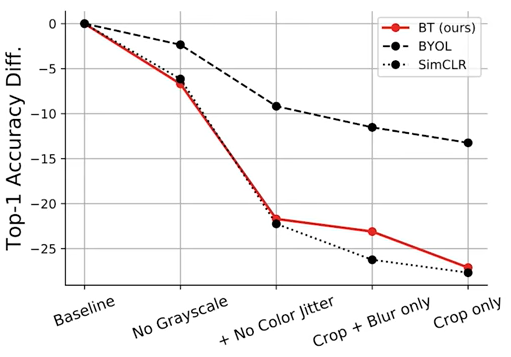
- augmentationを減らすと性能が低下していきます。同一だとみなすaugmentationの選択に素直に反応していると言っていました。確かにこのほうが扱いやすいかもしれませんね。
- 「学習するときの」ベクトルの成分の大きさに依存します。冗長性を削減するはずだったのでは?これはユーリさんにとっても意外だったようで、逆になると思っていたと言っていました。評価するときは2024成分の層を使っているので後ろの層の成分の数が影響するのもまた不思議ですが、特に考察は見つけられませんでした。
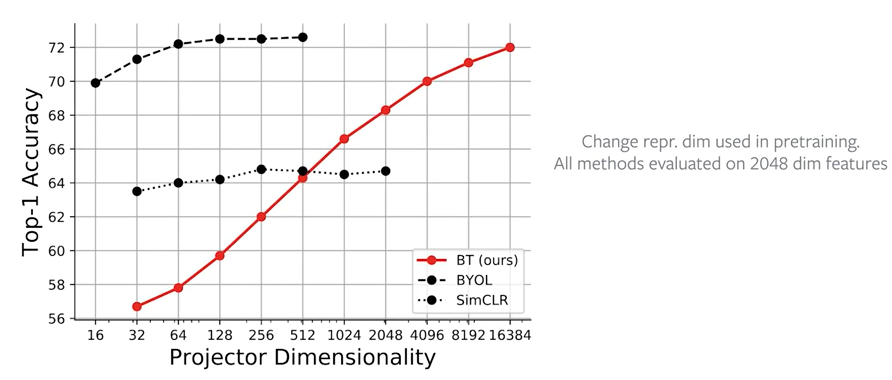
- 評価するときの2024というのは、resnet50をbackboneとして使うときの成分の数ですね。
5-3. Information Bottleneck Principle との関係
T.B.D.
少しずつ追記中です。
情報ボトルネックについてはこれらが分かりやすかったです。
現実には歪み関数d として適切なものが何であるのか判断するのが難しい状況がある。
代わりに、「ある別の変数Yに関する情報を最大限保ちつつなるべく小さな空間にエンコードする」という問題を考えるというのがinformation bottleneckの発想である。
まとめ
- Lossの変更だけ(アーキテクチャを触らず)で使えるのに、バッチサイズは小さくていい。
- Lossだけ変えるのにNegative Sampleのことを考えなくていい。
- こんなに気軽なのにSOTAと並ぶ性能。
参考
arXiv
arXiv Vanity (Vanityはweb表示なので翻訳が簡単😁)
github(公式)
第一著者本人が解説する動画!Jureはユーリと読むらしいです。
共著者のtwitter。背景やモチベーションはこの一連のポストが一番まとまっているかも。
共著者による解説動画。グラフについているコメントがいちいち分かりやすい。
日本語解説記事。