はじめに#
エキサイトのL&C事業部ではオンプレ環境からクラウド環境に順次に移行しております。その中にオンプレOracleのデータベース移行は最も難易度が高いです。ここで2つの選択肢があります
- ①オンプレOracle → AWS Oracle
- ②オンプレOracle → AWS PosgreSQL
表題通り分析基盤についてお話ししたいので、AWS環境のRDS(Oracle/PostgreSQL)からどうやって分析基盤を構築するのか紹介したいと思います。
実現したいモデル#
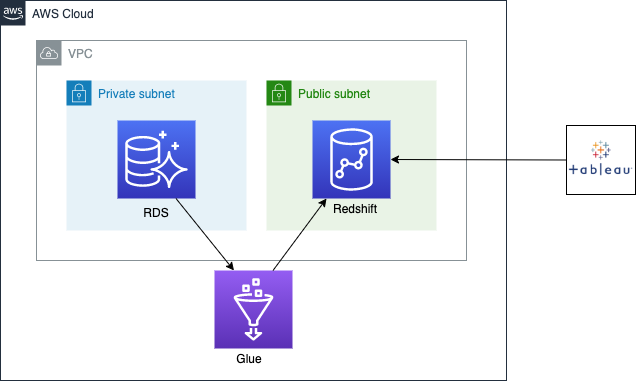
ゴールは、RDSからRedshiftにデータ転送の際に、個人情報が含まれるデータをハッシュ化したり、不要なデータを削除したりします。また、面倒なバッチを書きたくないので、フルマネージド型のETLサービスのGlueを選択しました。
実際に検証してみる#
AWS PostgreSQL → Redshiftへデータ転送##
結論から話せれば、Glueで結構簡単に実現できまました。場合によって若干Glueジョブのスクリプトに手を加えることもありますが、以下のようにほぼほぼいけます。
- STEP1:AWS PostgreSQL上に分析用のユーザーとViewを作成します。
- STEP2:AWS Glue上にCrawlerがPostgreSQLのViewを参照して、Data Catalogテーブルを作成できます。
- STEP3:AWS Glue上にジョブを作成して、データソースにPostgreSQLのData Catalogテーブルを指定、ターゲットにRedshiftを指定すれば、自動でRedshift側にテーブルが作成され、データが転送されます。
AWS Oracle → Redshiftへデータ転送##
このケースの大きな問題は、AWS Glue上にCrawlerがOracleのViewを参照できないのです。公式ドキュメント上にはっきりとできないと書いていないが、AWS担当者に問い合わせしたところ、実現ができないと回答していただきました。ここで2つの選択肢があります。
- AWS Glueのジョブから直接にOracleのViewを参照するように実装
- OracleのViewを経由せずに、直接にOracleのテーブルを参照する。不要なデータ削除や個人情報のハッシュ化などは、Glueのジョブで実装します。
結論#
AWS Oracle → Redshiftへデータ転送のケースは、OracleのViewを経由せずに直接にGlueジョブのスクリプトに手を加えた方が幸せだと考えます。