FirstN,LastN
コレクションやテーブルから最初のN要素、最後からN要素を取得する関数がPower Appsでは用意されています。
それがFirstN、LastNです。名前もそのままなのでわかりやすいですね。
一方で、Power Automateではというと、first関数、last関数はありますが、firstN、lastNはその名前では存在しません。
今回はPower AppsでのFirstN、LastNに対応するような関数を紹介します。
そもそもどういうときに使おうか
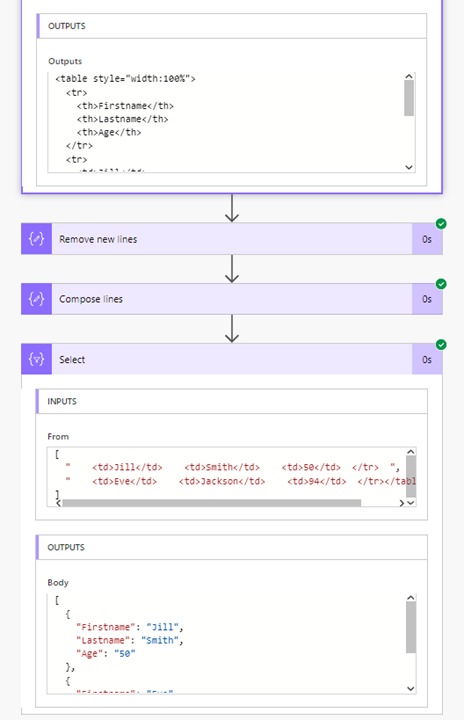
たとえばPower Automateの文脈で私がよく使うとすれば、以下のようなHTMLを分解してデータ化するときです。
<table style="width:100%">
<tr>
<th>Firstname</th>
<th>Lastname</th>
<th>Age</th>
</tr>
<tr>
<td>Jill</td>
<td>Smith</td>
<td>50</td>
</tr>
<tr>
<td>Eve</td>
<td>Jackson</td>
<td>94</td>
</tr>
</table>
このテーブルをデータにするために、素直にやるのが、trでsplitして、得られた配列をさらにtdでsplitとします。ここで余分なのは、最初のtrでsplitしたときの先頭です。
split結果は以下のような配列になります。(見やすさのために改行コードは取り除いてあります)
[
"<table style=\"width:100%\">",
"<th>Firstname</th><th>Lastname</th><th>Age</th></tr>",
"<td>Jill</td><td>Smith</td><td>50</td></tr>",
"<td>Eve</td><td>Jackson</td><td>94</td></tr></table>"
]
一目瞭然、最初に余分な要素がありますね。これを取りのぞきたい!
また各行を今度はtdでsplitしますが、その際には、
[
"<td>Jill",
"<td>Smith",
"<td>50",
"</tr>"
]
今度は最後に余計な要素が入っている。。。
このような、最初の1行が不要/最後の1行が不要 のような場合に、使える関数が**take()** と**skip()** です。
take = 最初のN要素を取得する
実際は文字列も対象とできるのですが、割愛します。
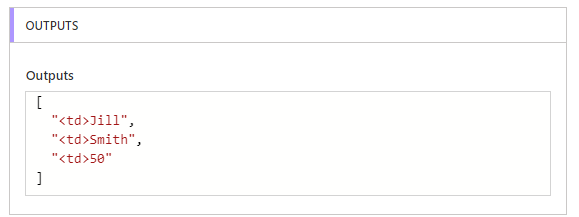
take関数は配列の先頭N要素を取得する関数です。先ほどの配列["<td>Jill","<td>Smith"...] のケースでいえば、
take(....,3)
と書くことで、最後の1つ余分な要素を除外できます。結果以下のような配列が得られます。
もし一般的に書きたい場合には、
take([元の配列], sub(length([元の配列]),1))
このように書けば、最後の1つを取り除いた結果が任意の行数の配列で得られます。
skip = 最後のN要素を取得する
引数の指定は少し違いますが、大体意味は同じです。
skip関数は配列の先頭M個をスキップした(取り除いた)結果を返します。
skip(createArray(0,1,2,3),2) --> [2,3]
ですね。
LastNと同じように、最後からN要素を指定したい場合には、skipの2個目の引数として
sub(length([元の配列]),N)
を与えればよいです。
最初の配列ではもっと単純に最初の1要素を飛ばしたいので、skip(...,1)とします。
[
"<table style=\"width:100%\">",
"<th>Firstname</th><th>Lastname</th><th>Age</th></tr>",
"<td>Jill</td><td>Smith</td><td>50</td></tr>",
"<td>Eve</td><td>Jackson</td><td>94</td></tr></table>"
]
結果は
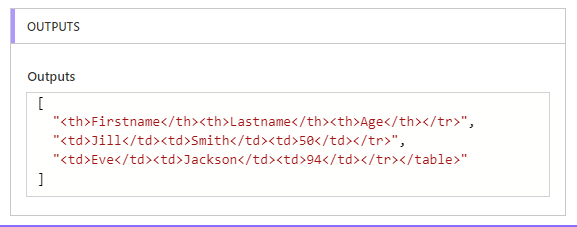
目的の配列が得られました。
補足
最初のHTMLのテーブルですが、skipとか使うときれいにデータ化できます。(このくらい簡単な場合にはxml化してもよいですが)