この記事は freeeデータに関わる人たち Advent Calendar 2020 11日目のエントリーです。
データエンジニアという仕事をやってます。今年もいろいろなデータを調べました。そのときに使ったものとかを紹介します。
データエンジニアとしてよくやること、データを調べる
令和のこの時代一口にデータエンジニアと言っても様々だと思います。
- 汚いデータをなんとかして読めるようにする人
- 大量データのETL処理を回す人
- 担当する人がいないから仕方なく基盤ぽいものを作る人
それに応じて使う技術スタックも様々ですが、すべからくやっているのは多分データを見るという行為。データを見るとは生データを見ると言い換えてよいです。
最近はデータ・ログをないがしろにするという文化は廃れて、全くフリーダムなデータ (一つのファイルに日本語文字コードが混ざっているとか、CSVでも文中のカンマがどうやっても分離できないとか、ヤヴァイやつ) はさほど見ることはない・はずですが、それでも
- 想定外のデータが来てETLが止まる
- 処理がまともに動かない
- 集計結果がおかしい
は有ります。こうなったときにデータを見ます。そんなときに使っている方法を書きます。あとデータはjsonを想定してます。
単ファイルを読む場合 vd
今年出会った一番coolなのはこいつ vd こと visidata
https://github.com/saulpw/visidata
CUIでデータを読むには最強と言って良いツールです。自分のblogでも書いているし、ググればそこそこ出てくるので詳しくは書きませんが、jsonを眺めるのが最高にいいです。見た目だけなら jq なり使えばいいですがデータを掘るには最高です。このツールは習うより慣れろなのでごちゃごちゃ書きません。SSだけ貼っときます
手元に合った package-lock.json を掘ってます

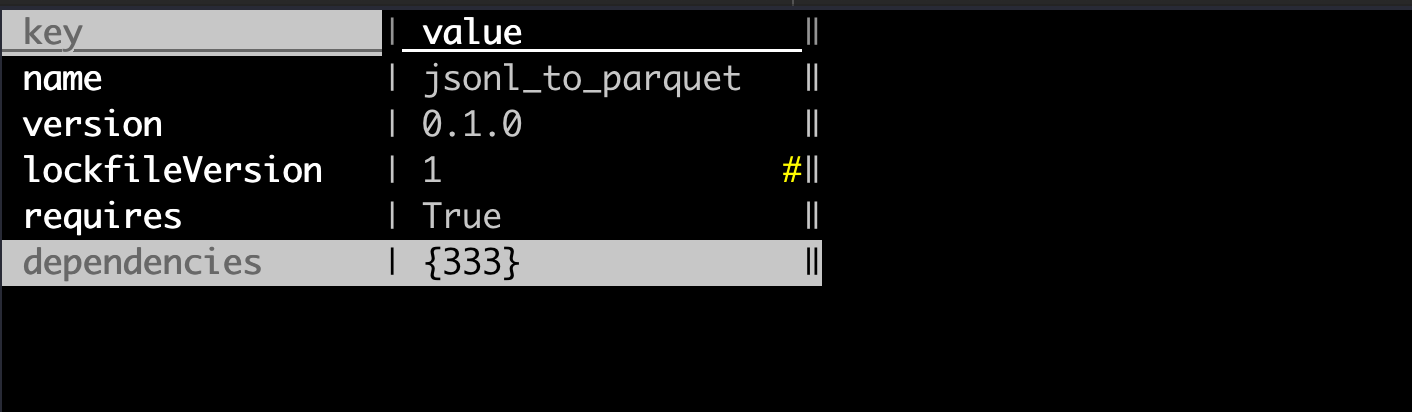
複雑な構造の jsonを掘って、掘った先の key一覧を別ファイルに保存とかもできます。なぜかyamlファイルだとこの動きにならないので、 yamlはjsonに変換してやってます。
複数ファイルを一気に調べるなら dask
複数ファイルの在り処は別にローカルFSでもいいですが基本はS3などObjectStorageを指します。この役割だとdaskが良いはずです。 dask
daskはpandasをスケールさせるものです、pandasとかと同じで基本は分析屋が使うもののはずですが、データを調べるときにも使えます。データエンジニアとして、データを調べるときに欲しいのは、S3上の大量なファイルのうち、どこに入っているかです。分析時はそんな情報なんてどうでもいいですが、異常なデータを探すときには必要です。データを直すから。
意外なことにこの「このデータの源泉は s3://hoge/fuga.gz ですよ」というのを簡単に取れるものは私が知る限りほとんど存在しません。そこで daskの databagです。
import dask.bag as db
import json
if __name__ == "__main__":
b = db.read_text(
's3://bucket/jsonlogs/2020/12/01/*',
include_path=True).map(lambda x: dict(json.loads(x[0]), _filepath=x[1]))
対象ファイルは json想定です、csvとかなら、 read_csvに引数つければ取れるらしいです。
https://docs.dask.org/en/latest/dataframe-api.html#dask.dataframe.read_csv
めちゃ時間かかりそうですが、それなりの速度で動いてます。詳しいことはよくわかりません。やってることの解説は、各ファイルにjson.loads() を掛けるのと同時に、 databag で取れたファイルパスを _filepath というキーでDictに追加してます。こっから先は焼くなり煮るなり。
もっとたくさんのファイルかつ、最新データも調べたいなら Athena + Partition Projection
$path という特殊カラムで調べられるらしいです。presto(Hive)由来っぽい
これと Partition Projection という機能を使って実現します。
Partition Projection ってなんや?
Athenaは事実上、partitionを適切に切ってないと使い物ならないですが、この partiitonを切るのは結構面倒です。特にパーティションの数が増えてくると、MSCK repair table を掛けてもAthenaの実行限界時間に達しても終わらないことはザラ。Glueクローラを回しても数時間はしょっちゅうです。パーティションが少ないうちは問題にならないが、増えるととたんに面倒になります。
そこで Partition Projection です。これは現時点ではAthenaでしか通用せず、Spectrumに使えないのが残念ですが、例えば dt=yyyy-mm-dd のようなパーティションでS3上のパスも同じ用に切っている場合(Hive_Partion)、いちいち個別にadd partitionせずとも勝手にpartitionが切られた状態になります。Hive_Partitionのルールからずれていてもカバーできます。
やり方はググれば出てくるので調べてください。
スキーマレスじゃない弱点/DDLの作成
Athenaの弱点というかめんどくさい点がスキーマレスじゃない点です。CSVとかならスキーマはカチッと固まってますが、JSONの場合なら、このキーはあったりなかったりはザラです。 ArrayやStructを使えば複雑なネスト構造は定義できますが、ちゃんとあっていないとだめです。DDL作るのが大変
これに関しては jsonを餌にしてDDLを生成するは、自分でも思いついたのですでに先人がやってます。AWSのDocumentにも書いてありました。 hive-json-schema
しかしこれ、餌にしたjson専用のスキーマになるので、構造が違うデータには対応できないはず。
まとめ
- ファイルの量がちょっとだったり、1ファイルのJSON構造を見るなら
vd - プログラムでゴリゴリやるなら
dask - JSONのスキーマ揺らぎがそんなにないなら Athena with Partition Projection
- 本当にスキーマレスが必要なら ElasticSearchのようなDocumentDB
- Loadが必要なので、現状では手軽とはいかない