はじめに
Node.jsでは非同期I/OのAPIが実装されているために,時間のかかる処理を行なっても,その間に他のリクエストを受付実行できるのでサーバの処理性能が高いといわれています.非同期I/OのAPIが用意されている場合にはそれを使えばいいのですが,時間のかかる処理を自分で書かなければならない場合には,どうすればその重たい処理をNode.jsサーバに対して非同期IOのように見せられるのか?が本記事のテーマです.
本記事のソースコードには行番号が付いているために,そのままコピーしてもnode.jsで動作できません.実際に試してみたいなら,下記レポジトリからダウンロードしてください.
https://github.com/h-hata/asyncIO
準備(非同期IOのAPI例,コールバックとイベントエミッタの再確認)
ファイルを読み出す場合のAPIには同期型のfs.readFileSyncと非同期型のfs.readFileがあります.下のコードはtest.txtというファイルを読み込みコンソールに表示するだけの簡単なプログラムですが,最初fs.readFileSyncを使って読み,そのあとfs.readFileで読んでいます.
1: const fs=require("fs");
2: let text;
3: console.log("-----------Start readFileSync");
4: text=fs.readFileSync("test.txt","utf-8");
5: console.log("-----------Return readFileSync");
6: console.log(text);
7: console.log("-----------Start readFile");
8: fs.readFile("test.txt","utf-8",function(err,data){
9: console.log("******callback");
10: console.log(data);
11: console.log("******error:"+err);
12: });
13: console.log("-----------Return readFile");
実行してみると
$node readFile.js
-----------Start readFileSync 3:
-----------Return readFileSync 5:
File Contents 6:
-----------Start readFile 7:
-----------Return readFile 13:
******callback 9:
File Contents 10:
******error:null 11:
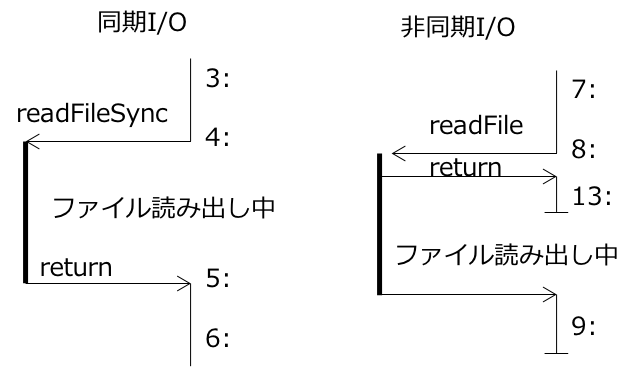
各行の末尾の数値はスクリプトの行番号に対応しています.2回の処理のそれぞれで,test.txtの内容である"File Contents"という文字列が読み取れています.このプログラムの見所は以下の2つだろうと思います.
ポイント(1)9:と13:の実行順序が記述順序と逆転している
ポイント(2)13:実行後にプログラムは終了していない
1: const fib=function(num) {
2: if (num <= 1) return 1;
3: return fib(num-1) + fib(num-2);
4: }
5: var m=0;
6: if(process.argv.length == 3){
7: m=parseInt(process.argv[2]);
8: }
9: console.log("fib(%d)=%d",m,fib(m));
再帰で書けば漸化式そのものを実装できて本体は2行です.
パソコンのCPUはCorei7 7660Uですが,パラーメータが30くらいまでなら瞬時に値が返ります.しかし40を越えると反応が悪くなり,50を越えると使い物になりません(断じて年齢の話とは無関係です).
これからこのフィボナッチ数列関数を非同期IO化してゆくのですが,事前にどれくらいのパラメータが重たい処理になるのかの見当をつけておいてください.だいたい40半ばあたりが,体感的に重いと感じる値になるのではないでしょうか(繰り返しますが年齢の話とは無関係です).
claire:fe hata$ node fib.js 10
fib(10)=89
claire:fe hata$ node fib.js 20
fib(20)=10946
claire:fe hata$ node fib.js 40
fib(40)=165580141
claire:fe hata$ node fib.js 50
fib(50)=20365011074
改善されるべきHTTPサーバの例
このフィボナッチ関数を組み込んだHTTPサーバを作ると以下のようになります.
1: const http = require('http');
2: const server = http.createServer();
3: const fib=function(num) {
4: if (num <= 1) return 1;
5: return fib(num-1) + fib(num-2);
6: }
7: server.on('request',function(req,res){
8: const url = req.url.toString().substr(1);
9: let n=parseInt(url);
10: let str;
11: if(isNaN(n) || n<=0){
12: str="illegal value "+url;
13: }else{
14: console.log("Start Fib"+n);
15: const f=fib(n);
16: str="fib("+n+")="+f;
17: console.log("Return "+f);
18: }
19: res.writeHead(200, {'Content-Type': 'text/plain'});
20: res.end(str);
21: });
22: server.listen(3333);
23: console.log("server listening ...");
サーバを起動してブラウザからアクセスしてみます.ポートは3333で起動しています.フィボナッチ関数に与えるパラメータはURLに直接指定します.例えば40を与えたければ,"http://127.0.0.1:3333/40"です.
claire:fe hata$ node fib1.js
server listening ...
URL=40
Start Fib40
Return 165580141
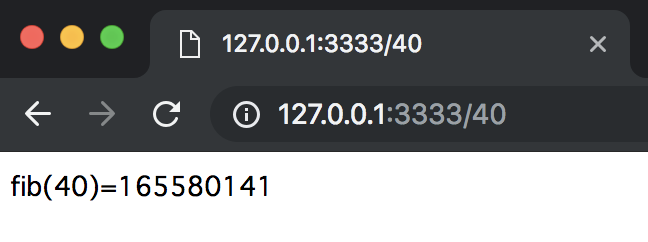
フィボナッチ数$F_{40}$がサーバから返されていることがわかります.
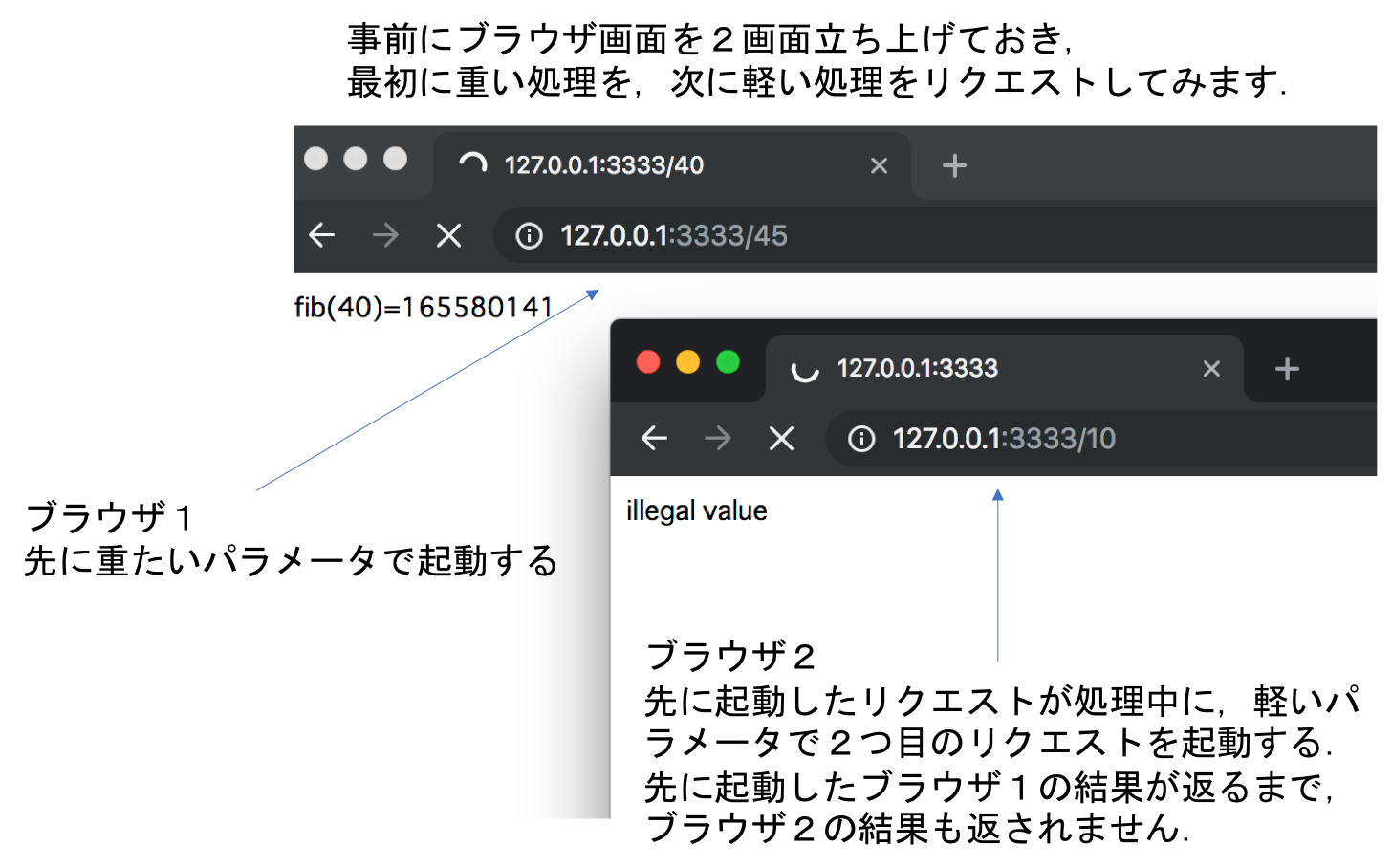
次に事前にブラウザ画面を2つ立ち上げておき,最初に重い処理(パラメータ45)を,次に軽い処理(パラメータ10)をリクエストしてみます.すると2つのリクエストの結果がほぼ同時に返ってくることを確認できると思います.軽い処理が,重たい処理を追い越せず待たされてしまっています.
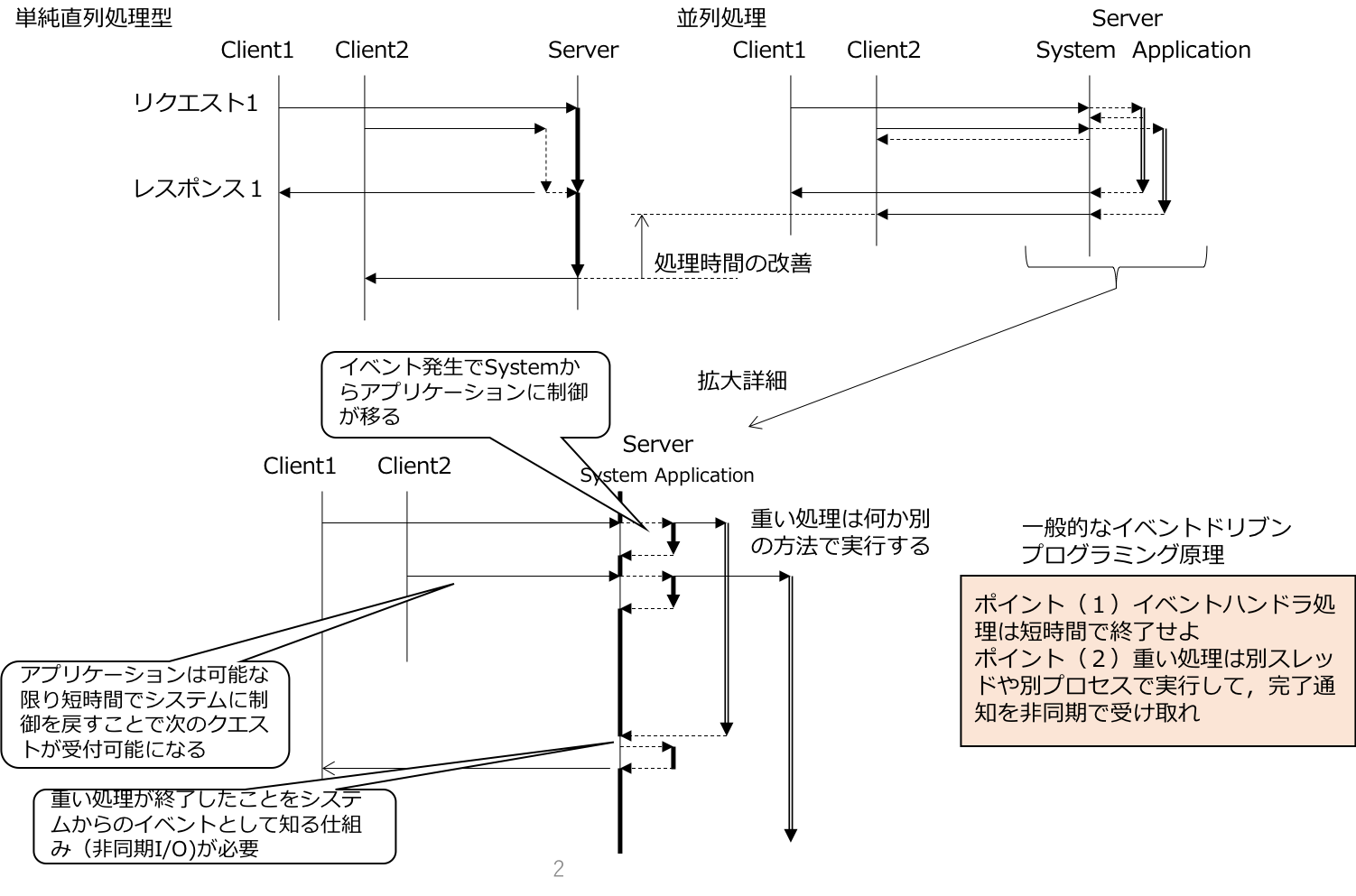
「Node.jaはワンスレッドなので速い」と言われているのですが,ワンスレッド処理は片側1車線道路のようなものなのでバックエンドの重たい処理にまでワンスレッドを持ち込むとダンプカーの後を走るスポーツカーまで遅くなってしまうのです.これをイメージ図で表すと下図左側の単純直列処理型のようなことが起こっています.これを右側の並列処理のようにNode.jsのシングルスレッドの高速性を捨てないで,リクエストを同時進行するHTTPサーバに改造して行きます.
ディスパッチャ,ワーカ,スケジューラ
HTTPサーバのフロントエンド部はワンスレッドで,バックエンドはマルチスレッドにするために両者を分離する戦略はC言語のソケットプログラミングでも実践されており,TCPコネクションごとに新たなプロセス(ここではプロセスとスレッドをほぼ同じものの意味としています)を立ち上げて,一つのクライアントに一つのプロセスに担当させる方法が取られてきました.これが下図の並行サーバです(並行pararellと並列concurrentもほぼ同じ意味で,マルチスレッドを意味するものとしています).同時に処理するリクエストが数百程度であればこれでもよかったのですが,数千を超えてくると新たにスレッドを生成する処理や,スレッドを切り替える処理が負担になり本来の仕事(例えばフィボナッチ数列計算)を圧迫するようになりました.このために,バックエンドのプロセスをリクエストがくるたびに新たに生成するのではなく,事前にいくつかのプロセスを生成しておき(これをワーカプロセスといいます),フロントエンドのディスパッチャプロセスはリクエストを受け取るとその仕事をワーカプロセスに任せ,すぐに次のリクエストを受け取ることに専念させるプログラミング方法が主流になりました.ワーカプロセスはスレッドプールといわれることもあります.OSやライブラリでスレッドプールをサポートしているものもありますが,ここでは自分で実装してみます.ワーカププロセスの数は,担当する仕事の質にもよりますが,フィボナッチ数列計算のような純粋なコンピュートタスクの場合にはCPUのコア数と同数で,ワーカがデータベースやネットワークのIOを行う場合にはそれより多めに作っておきます.
ディスパッチャがワーカに仕事を渡す方法をスケジューリングといいます.単純なスケジューラはラウンドロビンです.この方法はやってくる仕事を,順番にワーカに割り当てる方法です.割り当てられる仕事の性質が,ネットワークアクセスやデータベースアクセスのようなIOが多いものであれば,一つのワーカで複数の仕事を同時に受けもてるのでラウンドロビンは有効です.C言語のlibeventライブラリはラウンドロビン方式のディスパッチャと数個のワーカスレッドで数千コネクションを同時に処理できます.しかし,フィボナッチ数列のようなIOが発生しないコンピュートタスクではIO待ち時間がないため複数の仕事を受けもてなくなります.このような仕事のスケジューラにラウンドロビンを採用すると,一巡してもまだ処理の終わっていないワーカに仕事を割り当てる可能性があり,運の悪いリクエストは忙しいプロセスに割り当てられてレスポンスが遅くなります.
それに対して待ち合わせ系と呼ばれるスケジューラでは,暇にしているワーカにしか仕事が割り当てられません.待ち合わせ系(インターネット検索する場合には"待ち合わせ型スケジューリング"とフルネームを指定してください.そうしないと,あなたの検索履歴には不名誉な記録が残ります)は,待ち行列(キュー)を向かい合わせに配置します.一方のキューには,ディスパッチャが仕事を入れます.これをジョブキューといいます.他方のキューには仕事を割り当てらていないワーカが入ります.こちらはワーカキューです.2つのキューの先頭同士が組み合わさって,その仕事がワーカにによって処理されます.暇な時には仕事がなく,暇なワーカが右側のワーカキューに並んで仕事を待ちます.忙しい時には,ワーカキューが空になって,処理待ちの仕事が左側のジョブキューに並びます.
待ち合わせ系は一つのワーカで一つの仕事を受け持つので,フィボナッチ数列のようなコンピュートタスクには有効ですが,ネットワークサーバのようなIO待ち時間がある仕事では,IO待ち時間に他の仕事を行わないので,ワーカ数が少なければ仕事を待たせることになり,待ち合わせ系を採用する利点が見出せなくなります.
スケジューラは仕事の性質によって適切に選択しなければなりません.本記事ではIOの発生しないコンピュートタスクの非同期化を,待ち合わせ系で実現してみます.
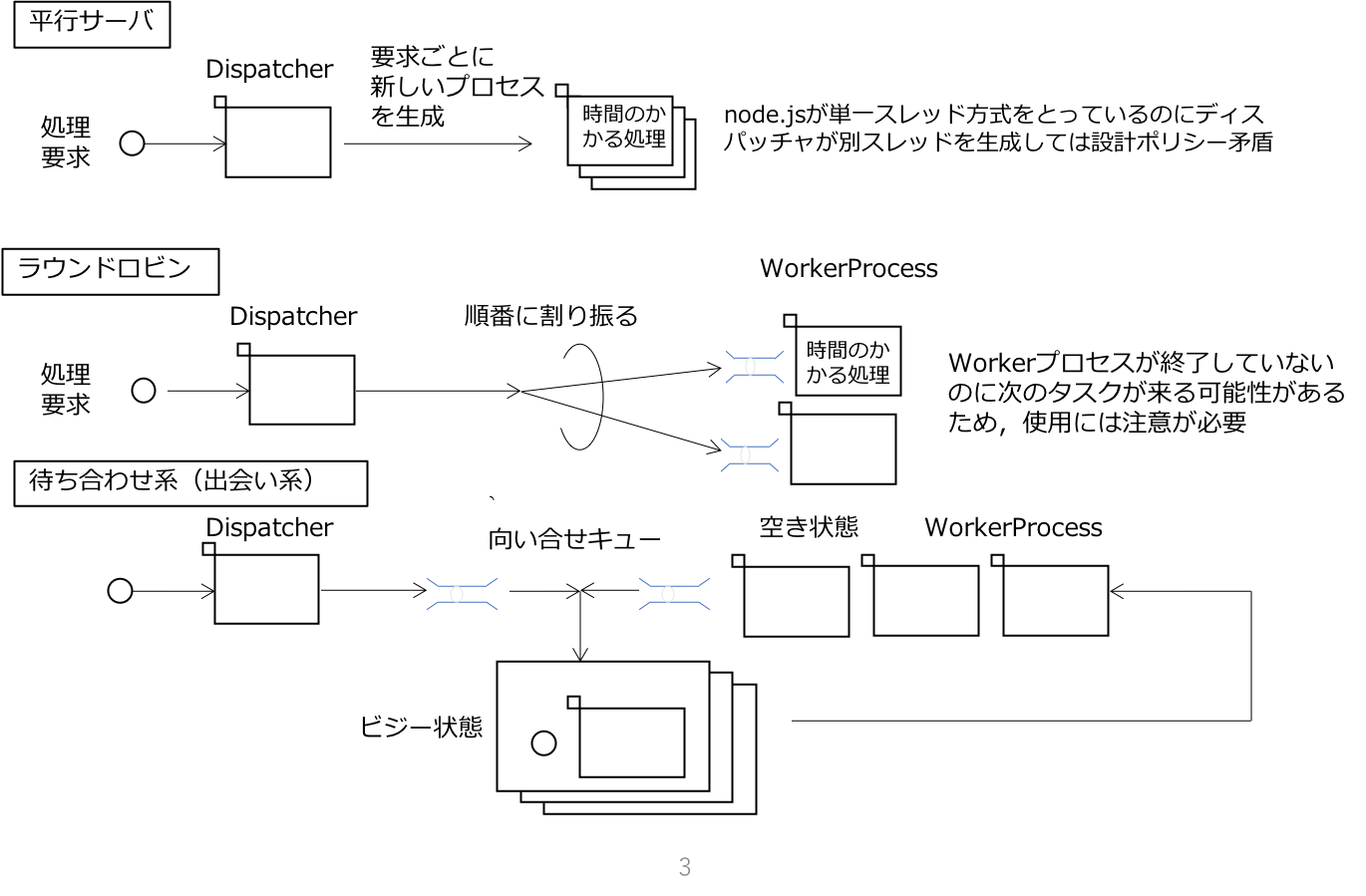
待ち合わせ型スケジューラの実装例
ワーカプロセス
フィボナッチ数列計算の関数をワーカプロセスに移して,ディスパッチャと繋ぐ待ち行列にRabbitMQを使ってみます.RabbitMQのインストール方法や使い方については,良い入門記事が多くあります.ここではRabbitMQが起動済みで,gensub,genpubという二つのアカウントが有効になっているものとしています.

ワーカプロセスはwork1というキューを作成して受信待ちします.このキューがジョブキューです.ジョブキューに入るジョブは,フィボナッチ数列計算の入力パラメータをJSON形式で表現した文字列です.mがフィボナッチ計算入力で,nは任意の整数でジョブIDとします.ワーカはwork1からジョブを取り出すとフィボナッチ計算を行い,計算結果をJSON形式に埋め込みwork2に入れます.出力のfが計算結果です.nは入力のn値をそのまま返します.ワーカキューは表に見えず,RabbitMQシステム内部に存在します.work2は計算結果を入れるもので,後ほど作成するディスパッチャのイベントエミッタになります.
1: var amqp = require('amqplib/callback_api');
2: const fib=function(num) {
3: if (num <= 1) return 1;
4: return fib(num-1) + fib(num-2);
5: }
6: amqp.connect('amqp://gensub:rabbitmq@localhost:5672', function(err, conn) {
7: conn.createChannel(function(err, ch) {
8: var q = 'work1';
9: var q2 = 'work2';
10: ch.assertQueue(q, {durable: true});
11: ch.prefetch(1);//1メッセージ受け取ったら受信の一時停止を通知
12: ch.consume(q, function(msg) {
13: var data = JSON.parse(msg.content);
14: console.log("m:"+data.m+",n:"+data.n);
15: var f=fib(data.m);
16: console.log("f:"+f);
17: ch.assertQueue(q2,{durable:true});
18: var resp=JSON.stringify({"f":f,"n":data.n});
19: var b=new Buffer(resp);
20: console.log(resp);
21: ch.sendToQueue(q2,b,{persistent: true});
22: ch.ack(msg);//再び受信を再開
23: }, {noAck: false});
24: });
25: });
ディスパッチャはまだできていませんが,動作確認をしてみます.無パラメータで起動してRabbitMQ Management画面からwork1にジョブを入れてみます.
 右側のターミナル(Windowsではコマンドプロンプト)からワーカを起動すると,RabbitMQに接続してwork1が作られます.そこでwork1に,行末改行なしで{"m":45,"n":1}と入れてみます.それが上図左側のブラウザ画面です.Publish messageを押すと,右側のワーカにJSONデータが取り込まれてフィボナッチ計算が始まります.しばらくして計算結果が表示されたらwork2を見てみます.
右側のターミナル(Windowsではコマンドプロンプト)からワーカを起動すると,RabbitMQに接続してwork1が作られます.そこでwork1に,行末改行なしで{"m":45,"n":1}と入れてみます.それが上図左側のブラウザ画面です.Publish messageを押すと,右側のワーカにJSONデータが取り込まれてフィボナッチ計算が始まります.しばらくして計算結果が表示されたらwork2を見てみます.
 上図の画面はwork2からGetMessage(s)ボタンを使ってメッセージを取り込んだところです.Payloadに計算結果のJSON形式文字列が得られています.
上図の画面はwork2からGetMessage(s)ボタンを使ってメッセージを取り込んだところです.Payloadに計算結果のJSON形式文字列が得られています.
マルチワーカプロセス
 ワーカがマルチプロセスになればどのような効果があるのかを確認します.このために2つのプロセスを同時起動します.上図のように一つのworker1キューを複数のプロセスで待っているようなイメージです.

上図右側のようにターミナルを2つ開いて,それぞれでfibs.jsを起動するだけでマルチプロセスで一つのキューを待っていることになります.この状態で左側のブラウザから,work1に二つのJSONメッセージをPublishします.一つ目は重めなジョブ{"m":48,"n":1}で,二つ目は軽いジョブ{"m":10,"n":2}です.一つ目のジョブを上のターミナルのプロセスが受け取り,処理を開始しました.上のターミナルはまだ計算中なのですが,下のターミナルはジョブを受け取ると瞬時に結果を表示しています.上のターミナルが計算を完了したらwork2での結果を見てみます.
ワーカがマルチプロセスになればどのような効果があるのかを確認します.このために2つのプロセスを同時起動します.上図のように一つのworker1キューを複数のプロセスで待っているようなイメージです.

上図右側のようにターミナルを2つ開いて,それぞれでfibs.jsを起動するだけでマルチプロセスで一つのキューを待っていることになります.この状態で左側のブラウザから,work1に二つのJSONメッセージをPublishします.一つ目は重めなジョブ{"m":48,"n":1}で,二つ目は軽いジョブ{"m":10,"n":2}です.一つ目のジョブを上のターミナルのプロセスが受け取り,処理を開始しました.上のターミナルはまだ計算中なのですが,下のターミナルはジョブを受け取ると瞬時に結果を表示しています.上のターミナルが計算を完了したらwork2での結果を見てみます.
 メッセージを拾い出すと,一つ目に軽いジョブの結果が入っています.RabbitMQサーバにはまだ一つのメッセージが残されているという表示も出ています.この後に重い処理の計算結果が置かれています.
このようにRabbitMQを使ってマルチワーカプロセスを実現して,重い処理と軽い処理を並列して行って,軽い処理が重い処理を追い越して即座に結果を返せるようにしました.
メッセージを拾い出すと,一つ目に軽いジョブの結果が入っています.RabbitMQサーバにはまだ一つのメッセージが残されているという表示も出ています.この後に重い処理の計算結果が置かれています.
このようにRabbitMQを使ってマルチワーカプロセスを実現して,重い処理と軽い処理を並列して行って,軽い処理が重い処理を追い越して即座に結果を返せるようにしました.
ディスパッチャ
ディスパッチャのコードはHTTPサーバ部分(下のコード28行めまで)と,RabbitMQに接続してworker2を受信する部分(29行目以降)の2つのパートで構成されます.そしてその間をtasksというテーブルで結びつけています.
1: const http = require('http');
2: const amqp = require('amqplib/callback_api');
3: const server = http.createServer();
4: let chan;
5: let count=0;
6: let tasks=[];
7: const q1 = 'work1';
8: const q2 = 'work2';
9: server.on('request',function(req,res){
10: const url = req.url.toString().substr(1);
11: let m=parseInt(url);
12: if(isNaN(m) || m<=0){
13: let str="illegal value "+url;
14: res.writeHead(200, {'Content-Type': 'text/plain'});
15: res.end(str);
16: }else{
17: console.log("Start request %d",m);
18: count++;
19: console.log("Start(%d) Fib(%d)",count,m);
20: tasks.push({"n": count, "res": res,"m":m});
21: let cmd=JSON.stringify({"m":m,"n":count});
22: let b=new Buffer(cmd);
23: chan.assertQueue(q1,{durable:true});
24: chan.sendToQueue(q1,b,{persistent: true});
25: }
26: });
27: server.listen(3333);
28: console.log("server listening ...");
29: amqp.connect('amqp://genpub:rabbitmq@localhost:5672', function(err, conn) {
30: conn.createChannel(function(err, ch) {
31: console.log("amqp channel established");
32: chan=ch;
33: ch.assertQueue(q2, {durable: true});
34: ch.consume(q2, function(msg) {
35: var data = JSON.parse(msg.content);
36: console.log("f:"+data.f+",n:"+data.n);
37: for(var i=0; i<tasks.length; i++) {
38: if(tasks[i].n == data.n) {
39: console.log('response for #('+data.n+')');
40: str="fib("+tasks[i].m+")="+data.f;
41: tasks[i].res.writeHead(200, {'Content-Type': 'text/plain'});
42: tasks[i].res.end(str);
43: tasks.splice(i, 1);
44: break;
45: }
46: }
47: }, {noAck:true});
48: });
49: });
50: console.log("amqp setup ...");
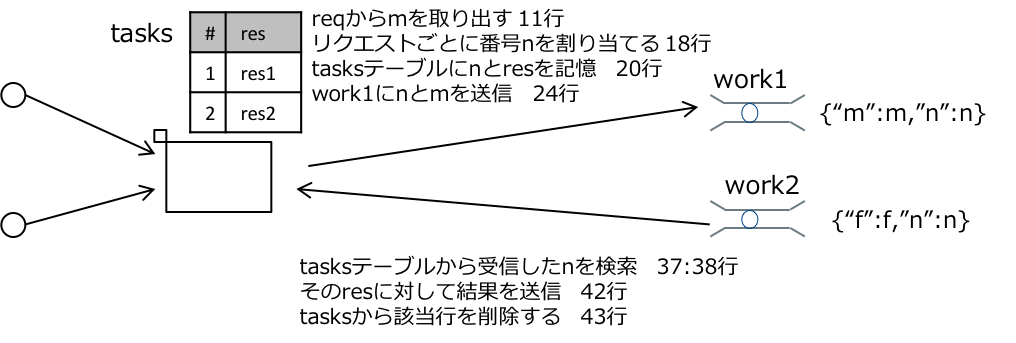
ディスパッチャはには2つのイベントエミッタがあります.一つはHTTPサーバで,もう一つはrabbitMQのwork2です.
HTTPサーバとしてリクエストを受け取ると,10行目から動き始めますが,すぐには結果を返せないのでとりあえずtasksテーブルに結果を返す先のレスポンスを登録して,リクエストをJSONにしてwork1に送ります.work1に送ったら,次のリクエストを待ち受けるために即座にリターンします.
一方work2に結果が入れられると35行目から動きはじめて,受信した結果からtasksテーブルに記憶されている結果返送先レスポンスを探し出して,そこに計算結果を送信します.では実際に動作を確認してみます.
実験
重たいリクエストのために軽いリクエストが待たされないようになったことを,3つのターミナルと2つのブラウザで確認します.一つのターミナルでディスパッチャfib2.jsを起動します.残りの2つのターミナルではワーカプロセスfibs.jsを起動します.3つ全てのプロセスはRabbitMQに接続してリクエスト待ち状態になります.
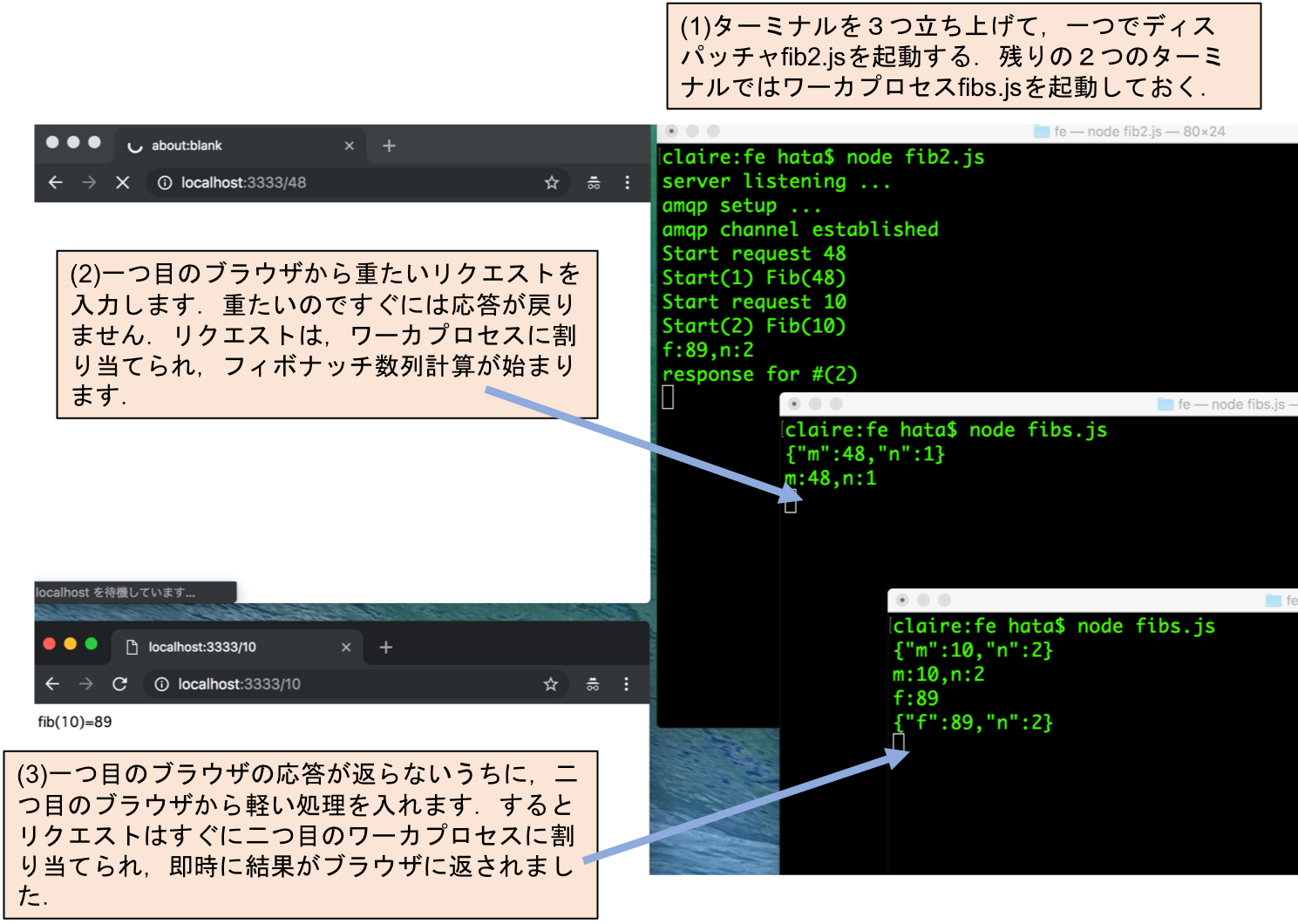
一つ目のブラウザから重たいリクエストを投入します.応答はすぐには戻りません.フィボナッチ数列計算に時間がかかりますので,その間に二つ目のブラウザから軽い処理を入れます.前回やった時には2つ目のブラウザも応答が返りませんでしたが,今回は一つ目のブラウザが処理中にも関わらず二つ目のブラウザには即時に計算結果が表示されます.2つ目のリクエストが一つ目のリクエストを追い越したことを確認できました.
非同期APIに組み込む
これで非同期APIを作る材料は整いました.最初の例で使ったfs.readFileのような非同期APIのフィボナッチ数列版を作ってみます.それが下のコード の11行目から始まるasyncFibという関数です.第1引数はフィボナッチ数列の入力パラメータ,第2引数はユーザが自由に設定して良いデータです.第3引数はフィボナッチ数列の計算が完了した時点で呼ばれるコールバック関数で,第2パラメータはコールバック関数の引数としてそのまま返されます.asyncFibを呼ぶと,そのコールごとにIDが割り当てられて,このIDもコールバックで返されます.
30行目でこのasyncFibをコールしていますが,コールバック引数は4つあります.最初の2つはasyncFibをコールした時の第1パラメータと第2パラメータが設定されます.第3パラメータは呼ばれた時に返されたIDで,第4パラメータがフィボナッチ数列の計算結果です.
fib2.jsではHTTPレスポンスに対する送信処理までプログラムの後半のAMQP側コールバックに含まれていましたが,fib3.jsで非同期API化することでHTTPに関する処理はAMQPのコールバック関数内から取り除かれて,HTTP処理は前半に,AMQP側は後半分離することができています.
1 const http = require('http');
2 const amqp = require('amqplib/callback_api');
3 const server = http.createServer();
4 let chan;
5 let count=0;
6 let tasks=[];
7 const q1 = 'work1';
8 const q2 = 'work2';
9
10
11 var asyncFib=function(m,priv,cb){
12 count++;
13 tasks.push({"n": count, "priv": priv,"m":m,"cb":cb});
14 let cmd=JSON.stringify({"m":m,"n":count});
15 let b=new Buffer(cmd);
16 chan.assertQueue(q1,{durable:true});
17 chan.sendToQueue(q1,b,{persistent: true});
18 return count;
19 }
20
21 server.on('request',function(req,res){
22 const url = req.url.toString().substr(1);
23 let m=parseInt(url);
24 if(isNaN(m) || m<=0){
25 let str="illegal value "+url;
26 res.writeHead(200, {'Content-Type': 'text/plain'});
27 res.end(str);
28 }else{
29 console.log("Start request %d",m);
30 c=asyncFib(m,res,function(m,res,n,f){
31 console.log("callback c=%d m=%d f=%d",n,m,f);
32 str="fib3("+m+")="+f;
33 res.writeHead(200, {'Content-Type': 'text/plain'});
34 res.end(str);
35 }
36 );
37 console.log("Start(%d) Fib(%d)",c,m);
38 }
39 });
40 server.listen(3333);
41 console.log("server listening ...");
42 amqp.connect('amqp://genpub:rabbitmq@localhost:5672', function(err, conn) {
43 conn.createChannel(function(err, ch) {
44 console.log("amqp channel established");
45 chan=ch;
46 ch.assertQueue(q2, {durable: true});
47 ch.consume(q2, function(msg) {
48 var data = JSON.parse(msg.content);
49 console.log("f:"+data.f+",n:"+data.n);
50 for(var i=0; i<tasks.length; i++) {
51 if(tasks[i].n == data.n) {
52 console.log('response for #('+data.n+')');
53 tasks[i].cb(tasks[i].m,tasks[i].priv,tasks[i].n,data.f)
54 tasks.splice(i, 1);
55 break;
56 }
57 }
58 }, {noAck:true});
59 });
60 });
61 console.log("amqp setup ...");
まとめ
本記事ではnode.jsで作ったHTTPサーバを例に非同期APIを作成しました.HTTPサーバに限らず,AndroidやiOSでのスマートフォンアプリやWindowsの.netFramework上のデスクトップアプリでも,一般的に「時間のかかる処理はメインスレッドで処理しない」という原則があります.そのため,メインスレッドが呼べる非同期APIを準備する必要がありました.非同期APIは仕事を裏方に依頼するだけで即座にリターンする関数なので,メインスレッドはコールバック関数で結果を受け取る必要があります.このコールバックを発生させるためのイベントエミッタとしてRabbitMQを使いました.RabbitMQは,結果がキューに入れられた時にコールバックさせることに加えて,待ち合わせ系を実現するためのスケジューラとしても機能しています.
プログラムはもっとシンプルにかける余地もあったでしょうが,わかりやすくするために冗長なところもあります.また分量が多くなるため,RabbitMQのライブラリであるAMQPの使い方等の説明を省いていますがご容赦ください.