はじめに
プログラミングを学習し始めて最初にくるハードルが配列です。筋の良い学生でも、配列と代入が組み合わさるとちょっと怪しくなります。配列への代入による影響について7つの問題を(高専本科2年生むけ)前期中間試験想定としてやってみましょう。
問題
問1 何が表示されますか
let x;
let y;
x = 1;
y = x;
x = 5;
console.log(y);
問2 何が表示されますか
x = [1, 2];
y = x;
x[0] = 5;
console.log(y[0]);
問3 何が表示されますか
x = [1, 2];
y = [...x];
x[0] = 5;
console.log(y[0]);
問4 何が表示されますか
x = [
{ a: 1, b: 2 },
{ a: 3, b: 4 },
];
y = [...x];
x[0].a = 5;
console.log(y[0].a);
問5 何が表示されますか
x = [
{ a: 1, b: 2 },
{ a: 3, b: 4 },
];
y = x.map((p) => ({ ...p }));
x[0].a = 5;
console.log(y[0].a);
問6 何が表示されますか
x = ["A", "B"];
y = x;
x[0] = x[0].replace("A", "C");
console.log(y[0]);
問7 何が表示されますか
x = ["A", "B"];
y = x;
x[0] = x[0].replace("A", "C");
console.log(y[0]);
解答
問題1から7までのプログラムを一気に走らせた結果は以下の通りです。
1
5
1
5
1
C
A
解説
問題1 y=x

まず代入を変数とデータの2階建てモデルで考えます。let xのように変数を宣言すると、2階の変数エリアにxが現れます。そしてx=1という代入は、イコールの左側の変数からイコールの右側のデータに関連付けすることだとします。y=xでは右側に変数がありますが、イコールの右側の変数は矢印の先にあるデータに変換されてから(これを変数の評価といいます)イコールの左側の変数にそのデータが代入されます。この矢印を参照といいます。変数はデータを参照して、データは変数から参照されます。x=5は再代入といって、既存の矢印を破棄して新しい矢印をイコールの右側のデータに向けます。再代入されたのはxであり、yから出る矢印には影響はありません。したがって、yはそのままで 1が表示されます 。
一つの変数から出る矢印は最大1です。変数から出る矢印0の場合がjavascriptでいうundefinedです。いっぽうデータは複数の変数から参照されてもかまいません。x=yは、データは変化せずyからでる矢印が新しくできることを意味します。代入により直接影響を受けるのはイコールの左側だけです。参照数(入ってくる矢印の本数)が0になると、そのデータは自動的に消滅します。
問題2 y=x

配列は1階部分が2つに分かれて中2階ができるモデルを考えます。この中2階は1階の一部であり、変数から参照されます。x=yは、問題1でデータは変わらずyから出る参照だけが一つ増えるということでした。xとyは同じデータを参照します。その後、x[0]を書き換えると配列の0番目に再代入が起こります。このためy[0]も間接的に影響を受けて5が表示されます。
問題3 y=[...x]

...xはスプレッド構文といい、xが配列やオブジェクトなら括弧[]や{}を外したものといわれます。[...x]は括弧を外して、また括弧をつけるってどういうこと?と混乱するかもしれません。まず、この問題の場合y=[のようにイコールの右側に括弧[が現れています。これは新たな配列がデータ領域に確保されてそれを変数yで参照しているということになります。その配列要素ですが、xは配列なのでその要素が括弧内に展開されてy=[1,2]となります。その後、x[0]に5が再代入されますが、y[0]から伸びる矢印には影響は及びません。この結果y[0]は1のままです。
問題4 y=[...x]

問題3に似ていますが配列の要素が基本データ型ではなくオブジェクトになっています。問題3と同様にyの参照先に新しく配列が作られますが、その新しい配列の参照先はx[0]やx[1]の参照先のままです。x[0]とy[0]は同じオブジェクトを参照しています。これは [...x]を[{a:1,b:2},{a:3,b:4}]のように解釈するのではなく、[x[0],x[1]]と考えます。そうすると配列はコピーされて別のデータとして確保されるのだけれど、その要素はコピーされない訳が分かると思います。このように、配列はコピーされるけどその要素は2つの配列で同じものを参照しているようなコピー方法をシャロー(浅い)コピーといいます。この状態でx[0].aに5を再代入しても問題3と同様y[0]から伸びる矢印には影響は及びません。しかし参照先のデータ内容に変更があり、y[0].aも5に変更されます。
問題5 { ...p }
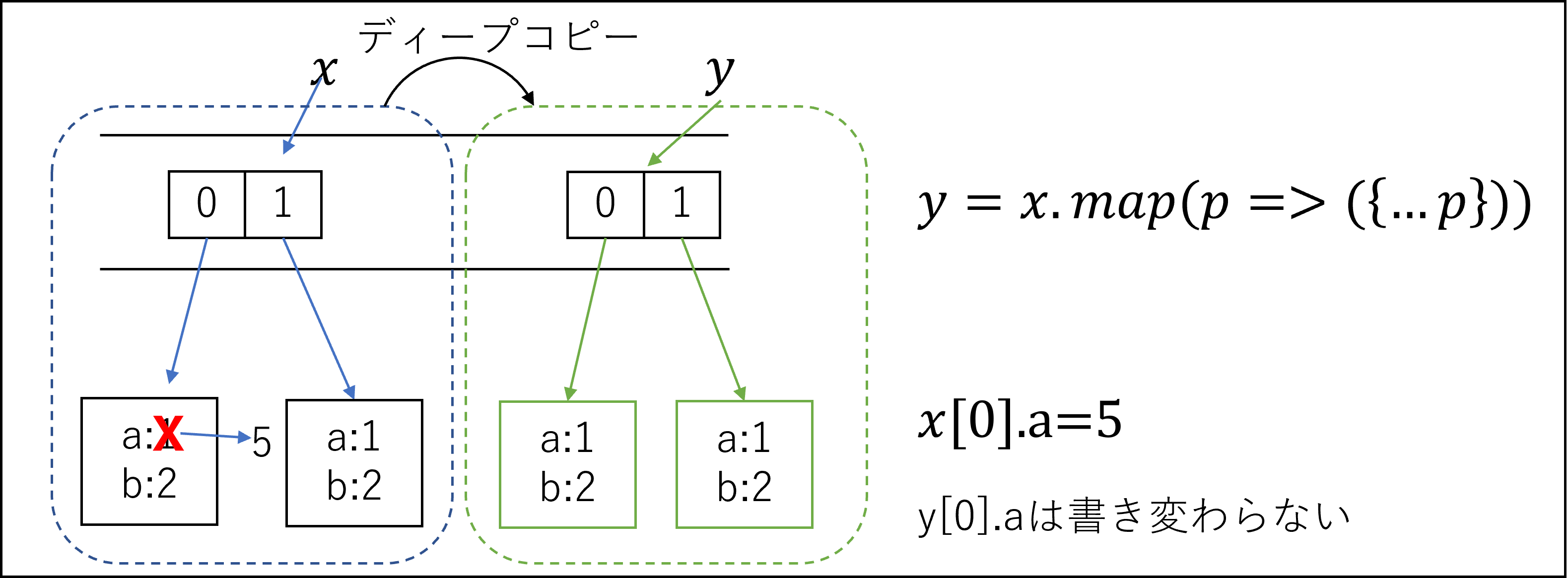
それでは配列の要素までコピーをしたい場合はどうすればよいでしょうか。それがy = x.map((p) => ({ ...p }));です。配列のmapメソッドは一つの配列から別の新しい配列を産みだします。そして、元の配列の要素一つひとつをmapメソッドのパラメータに指定した関数で処理した結果を新しい配列の要素とします。もとの配列の要素がpなら、新しい配列の対応する要素は{...p}です。この波括弧は新しいオブジェクトを作ることを意味します。本来ならy = x.map((p) => {return{ ...p }});のようにアロー関数式の本体を表す波括弧を外側につけるべきですが、return文1文だけなら波括弧を省略できるルールに則るとy = x.map((p) =>{ ...p });のようになって波括弧がオブジェクトの生成なのかアロー式の本体なのか曖昧なります。そこで丸括弧で囲ってreturnされる式であることを表しています。よってこの波括弧は新しいオブジェクトを作ることを意味します。配列の参照先までコピーされます。この結果x[0].aに5を再代入しても、y[0].aは1のままです。
問題6 y=x

問題3と同じく、配列はコピーされず変数が一つ追加されているだけなので、x[0]に再代入が起きるとy[0]の参照先も変わります。よってy[0]は"C"に変化します。ここでちょっと待てよ、replaceって部分文字の置き換えメソッドだったのだけど、再代入になるのだっけ?と思われるかもしれません。replaceは部分文字を置き換えた新しい文字列を生成します。ですからx[0].replace("A", "C")だけではx[0]は書き変わらず、x[0]=x[0].replace("A", "C")のように元の変数に再代入しなければならなかったのです。これを意識して次の問題7に臨みましょう。
問題7 y=[...x]

再びシャローコピーです。問題3では配列のシャローコピーは一方の再代入が発生しても他方の配列の影響は受けず、問題4では要素の参照先の内容が変更されると、他方の参照先にも変更があったように見えることを学びました。簡単にいえば、シャローコピーでは、基本データ型の配列は問題3、オブジェクトデータ型の配列は問題4のように見えるのでした。それでは、文字列の配列のシャローコピーは、一方の配列の要素の文字列を変更すると他方の配列には影響が及ぶのでしょうか?というのが問題7の趣旨です。答は影響されない、です。問題3のように、文字列はオブジェクトでありながら基本基本データ型のように再代入しなければ要素を変更できないのでした。基本データ型の性質は、参照矢印を移動させずオブジェクトの内容だけを変更する問題4のような操作ができないというところです。文字列もいったん作成したらその内容を変更できず、変更する場合は別の文字列として新規に作成してもとの変数に再代入しなければなりません。このようなデータのことをimmutable(不変)といいます。文字列が基本データ型に分類されているのは、このimmutableな性質を持っているからです。問題1でx=1からx=5に再代入するのは、1というオブジェクトの内容を5に変更したのではなく、1というオブジェクトから別の5というオブジェクトに参照先を変更するというモデルで理解しました。文字列も同様に再代入によるしか内容を変更できないことが分かれば、シャローコピーで一方の配列の文字列を変更しても、他方に影響が及ばない訳も理解できるのではないでしょうか。
追加課題 配列のソート
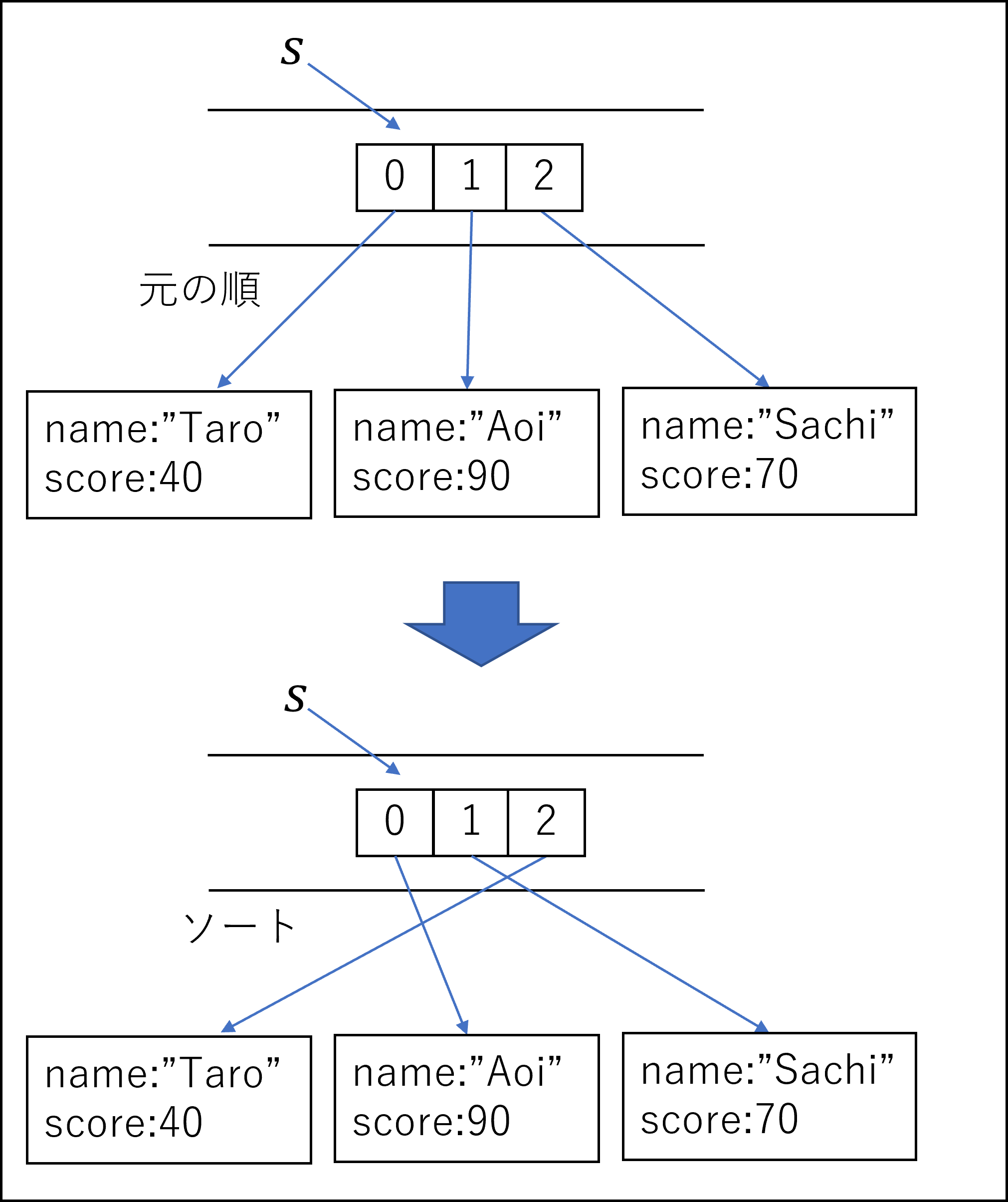
学生3名の成績データを保持する配列があります。バックアップをとってから成績順に並び替えます(ソートします)。
バックアップの方法は、方法1代入、方法2シャローコピー、方法3ディープコピーのいずれかです。
s = [
{ name: 'Taro', score: 40 },
{ name: 'Aoi', score: 90 },
{ name: 'Sakura', score: 70 },
];
//Backupをとってから成績順にソートします
//Backupの取り方は以下の3行のいずれか1つとします。
bak = s;//方法1
//bak = [...s];//方法2
//bak = s.map(p=>({...p}));//方法3
s.sort((p, q) => p.score - q.score)
s[0].score = 0;
//原本はソートされて、から成績トップだった学生を0点に上書きしました
console.log(s);
console.log(bak);
方法1、2、3の各々で
バックアップはソートされているでしょうか?YES/NOで答えてください
バックアップの学生データは0点に上書きされたでしょうか?YES/NOで答えてください
解答
配列をソートするモデルとして、データ自体の内容は全く変化がなく配列から伸びる参照先が変わるだけでものと考えましょう。
方法1(これはいけません)
バックアップデータは ソートされています(YES) データ上書きされます(YES)
配列は一つだけなので、ソートされるとyまでソートされたように見えます。
s
0:{name: 'Aoi', score: 0}<==もともと90点だったので配列のトップに来るが0点で上書きされた
1:{name: 'Sachi', score: 70}
2:{name: 'Taro', score: 40}
bak bakに対して何も変更操作していないのにデータはsと同じになっている
0:{name: 'Aoi', score: 0}
1:{name: 'Sachi', score: 70}
2:{name: 'Taro', score: 40}

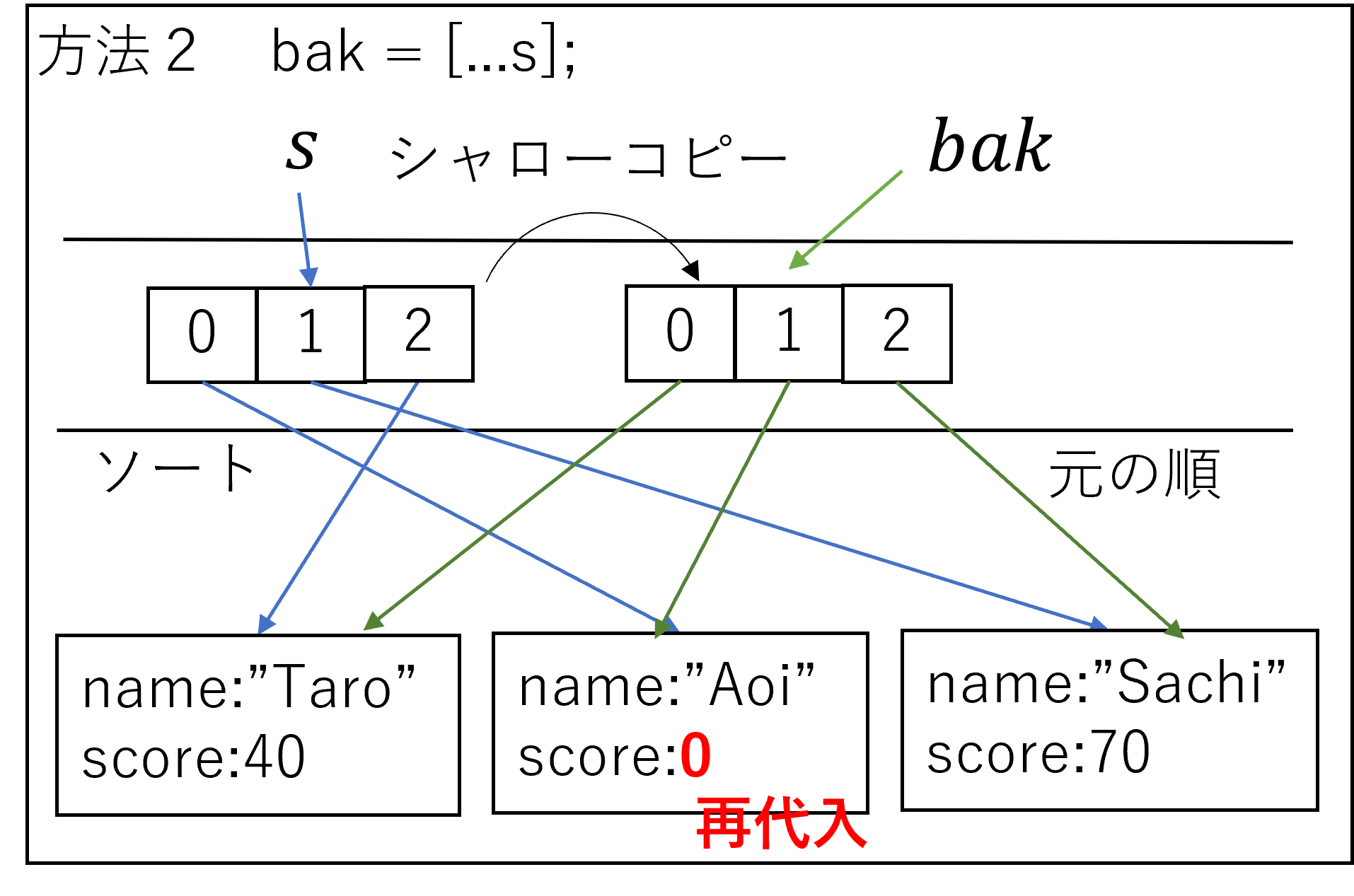
方法2(まあまあイケます)
バックアップデータは ソートされていません(NO) データ上書きされます(YES)
シャローコピーで配列がコピーされます。ソートされるとsの参照先の配列だけがソートされ、bakの参照先配列はそのまま元の順序のままです。しかし1階部分のデータがコピーされていませんので、書き換えるとbakの配列の要素も書き変わります。
s
0:{name: 'Aoi', score: 0}
1:{name: 'Sachi', score: 70}
2:{name: 'Taro', score: 40}
bak
0:{name: 'Taro', score: 40}
1:{name: 'Aoi', score: 0}<==ソートされてないがデータが書き変わった
2:{name: 'Sachi', score: 70}
方法3
バックアップデータは ソートされていません(NO) データ上書きされていません(NO)
ディープコピーでは1階部分のデータもコピーされます。sの配列をソートしたり、配列の要素を変更してもbakの配列や要素には影響がありません。しかし、じつはこれでも完ぺきではありません。それは次のスプレッド構文で説明しています。
s
0:{name: 'Aoi', score: 0}
1:{name: 'Sachi', score: 70}
2:{name: 'Taro', score: 40}
bak
0:{name: 'Taro', score: 40}
1:{name: 'Aoi', score: 90}<==ソートされておらずデータも書き変わっていない
2:{name: 'Sachi', score: 70}

スプレッド構文を使ったディープコピーの注意点(配列やオブジェクトの要素にオブジェクトが含まれると要注意)
bak=[...s]で配列のコピーができました。...sはスプレッド構文で、sが配列やオブジェクトなら[]や{}の括弧を外したものと学んだかもしれません。注意すべきは括弧を外したあとに残るものなのですが、文字列が残るのではなくオブジェクトが残ると、考えましょう。
たとえばa=[1,2,3]のように要素が基本データ型なら...aは1,2,3になるので、b=[...a]はb=[1,2,3]となり、配列のコピーが作られます。繰り返しになりますが、a=[{x:1},{x:2}]のように要素がオブジェクトの場合には、b=[...a]はb=[{x:1},{x:2}]と文字列展開のように考えてはなりません。この場合はb=[a[0],a[1]]のように解釈すべきでしょう。これがシャローコピーになる理由です。配列のコピーは作成されるけれど、要素のコピーは作成されていません。
おなじように、a={x:1,y:2}をスプレッド構文でコピーを作ってみます。問題5では、mapメソッド内の関数、b={...a}で、b={x:1,y:2}のように展開されaのコピーをbに簡単に作れました。しかしこれは、aに含まれるプロパティがすべて基本データ型だから許されたのです。aのプロパティに配列やオブジェクトが含まれる場合、たとえばa={x:1,y:{p:2,q:3}}では、b={...a}が完全なディープコピーになりません。b={x:1,y:yの参照先オブジェクト}と展開されるので、下図の左側のようにa.yとb.yが同じ参照先になります。ディープコピーをとりたければb={...a}だけではなく、b.y={...a.y}のようにオブジェクト要素のコピーも必要です。これにより、下図右側にのようになります。どのようなプロパティをもつオブジェクトでも一発でディープコピーを作成できる方法はなく、コピー元に別のオブジェクトが含まれるならそのオブジェクトのコピー階層的に深くまで降りてコピーをとる必要があります。
const copy = (from)=>{
to = { ...from }
to.b={...from.b}
return to;
