はじめに
本記事は、【オンライン】ゆるふわマシンラーニング vol.5 - connpassのために取り組んだことの、年末振り返り記事です。
わたしは、enebularとTeachable Machineハンズオンを見ながら、enebularを使って、機械学習をやるにあたってのメリットとデメリットを自分なりに考えてみました。
enebularで機械学習をやるメリット
1. (なんと言っても)プログラムの実行フローをGUIで操作・把握できること
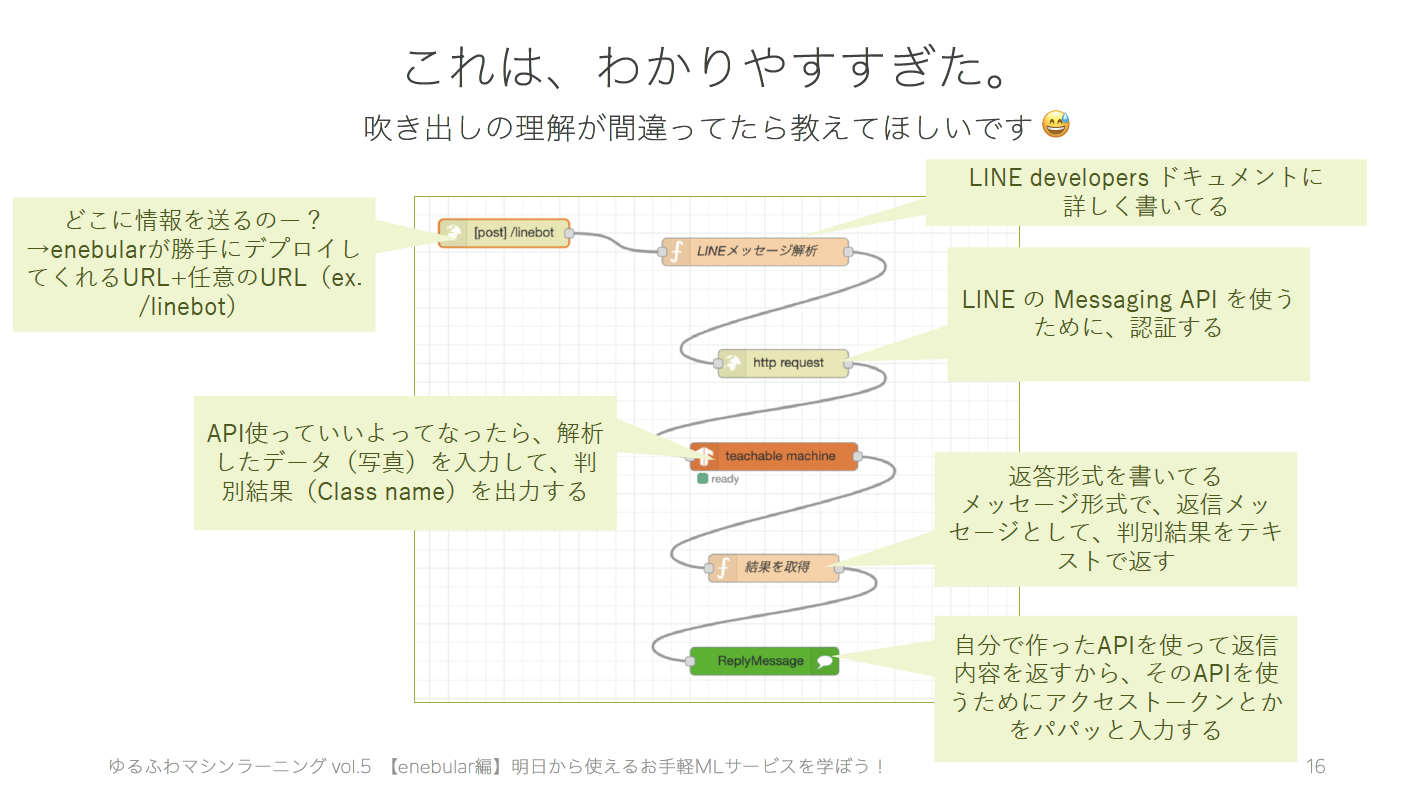
わたしはGUI操作でプログラムを書く(?)事自体がはじめてだったので、とても新鮮でした。
2. ほぼ数行のコードで期待する機能を実装できること
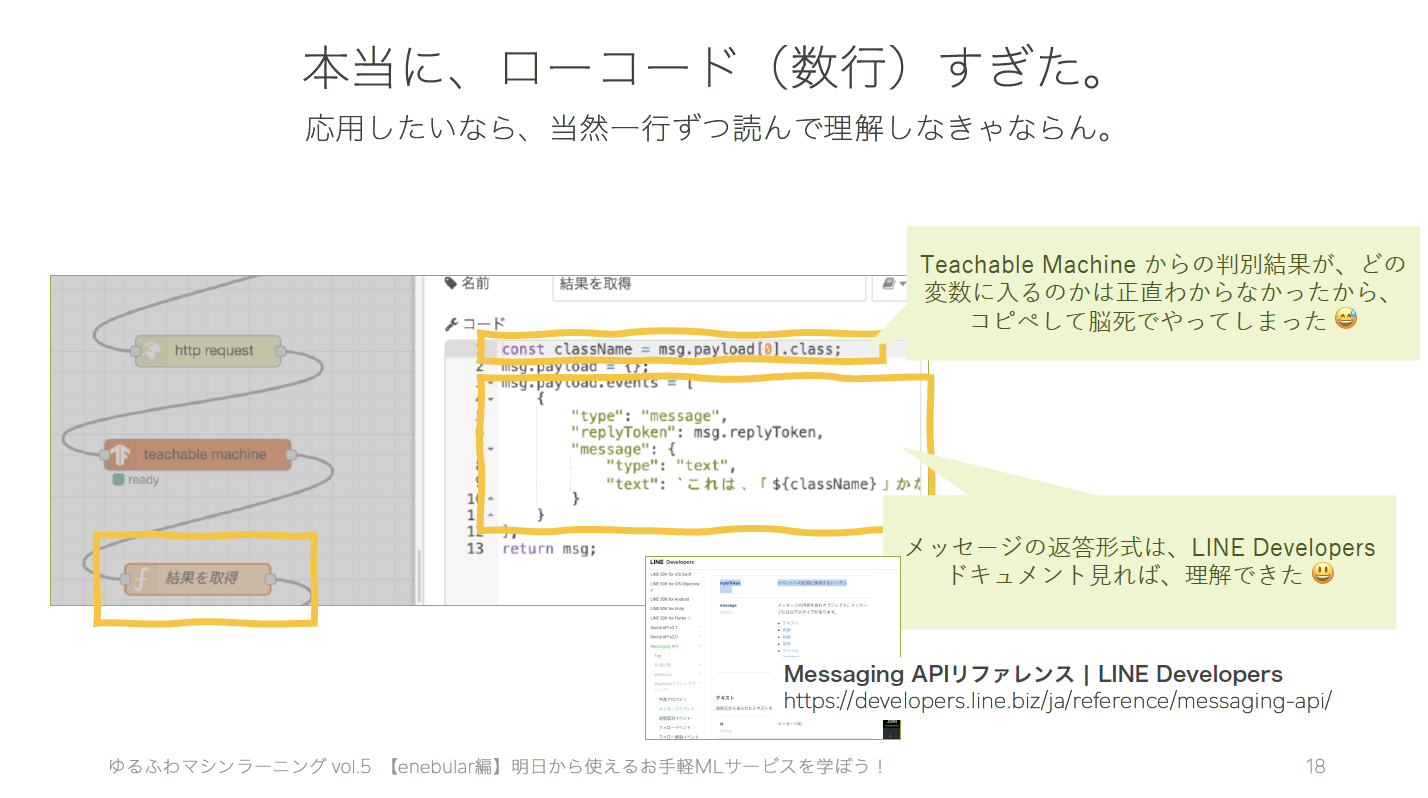
データの入力形式を理解する必要はありますが(後述)、それでも、こんなにも数行でいいのか?と驚きを隠しきれませんでした。サクッと試しに作ってみようか!がもっとサクッとできるようになる世界を覗いてしまったドキドキ感がありました。
たぶん、初学者エンジニアよりも中堅以上のエンジニアのほうがこの魅力に気づきやすいし、体感しやすい気がします。
3. コミュニティの記事が参考になる
enebularはコミュニティ記事が豊富で、無料で試しに使ってみるときにとても参考になりました。enebular blogは定期的に記事が更新されていて、(お、enebularでこんなこともできるのか!)という発見があります。
enebularで機械学習をやるデメリット|やってみて感じたこと
初学者よローコードに甘んずることなかれ
enebularを使うことで、わたしははじめてNode−REDと呼ばれるローコード開発の門を叩いたわけですが、このローコードというのは、あくまでも設計力があるエンジニアに与えられたご褒美であると感じました。
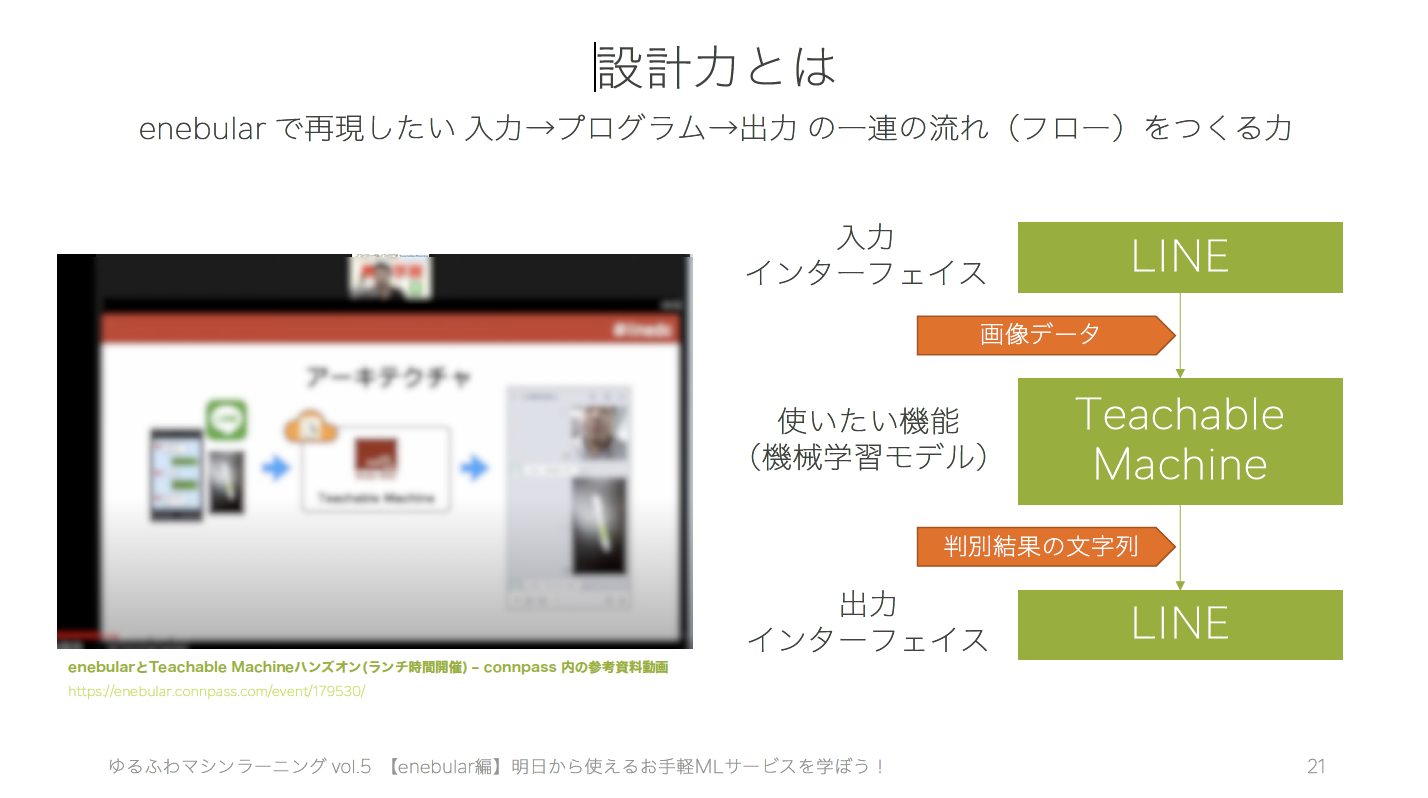
設計力というのは、**どういうデータをどんな形式でプログラムに入力し、どのような機能(処理をするのか)を考え、どこにどのような形式で何を出力するのか?**を考えられる力のことです。
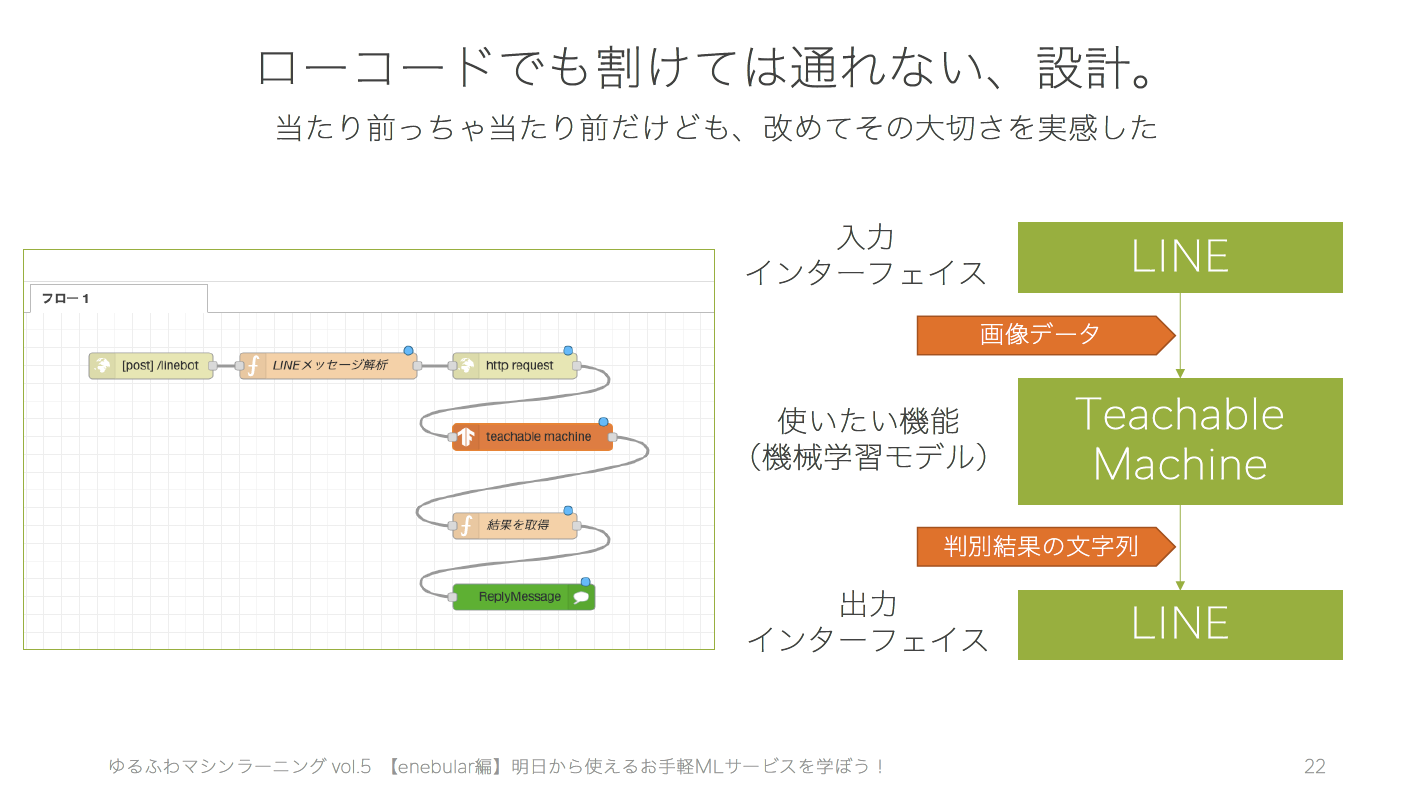
「したいこと(出力結果)」だけ考えてenebularに触れると、フローについて考えさせられます。
わたしはデータ分析や機械学習モデルをつくることが多いので、プログラミングにおいての設計力の大切さを改めて実感しました。
OSSコミッターに甘えていることを改めて自覚せよ
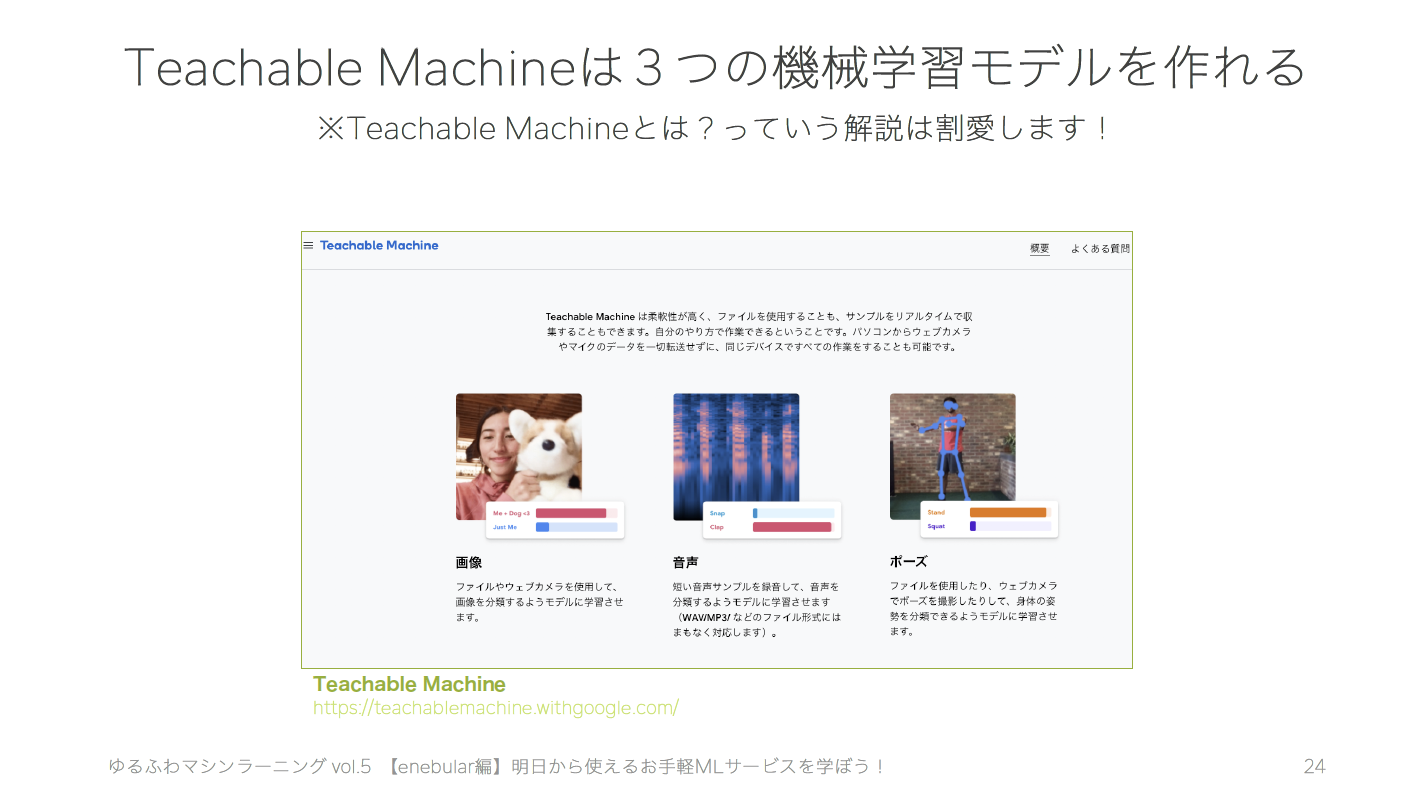
今回は、Googleが提供する
TeachableMachineのAPIをNode-RED経由で実行しました。
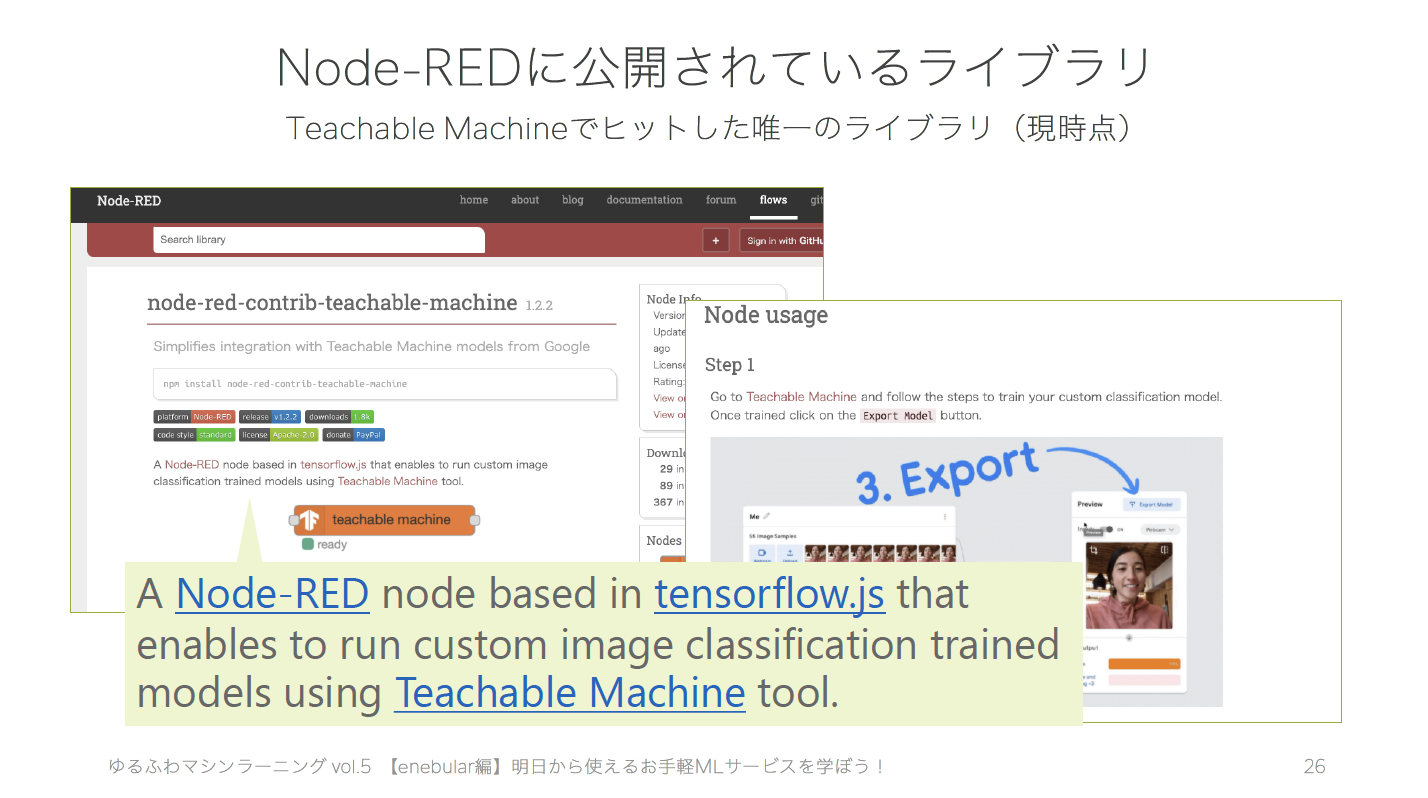
翻訳してみると…
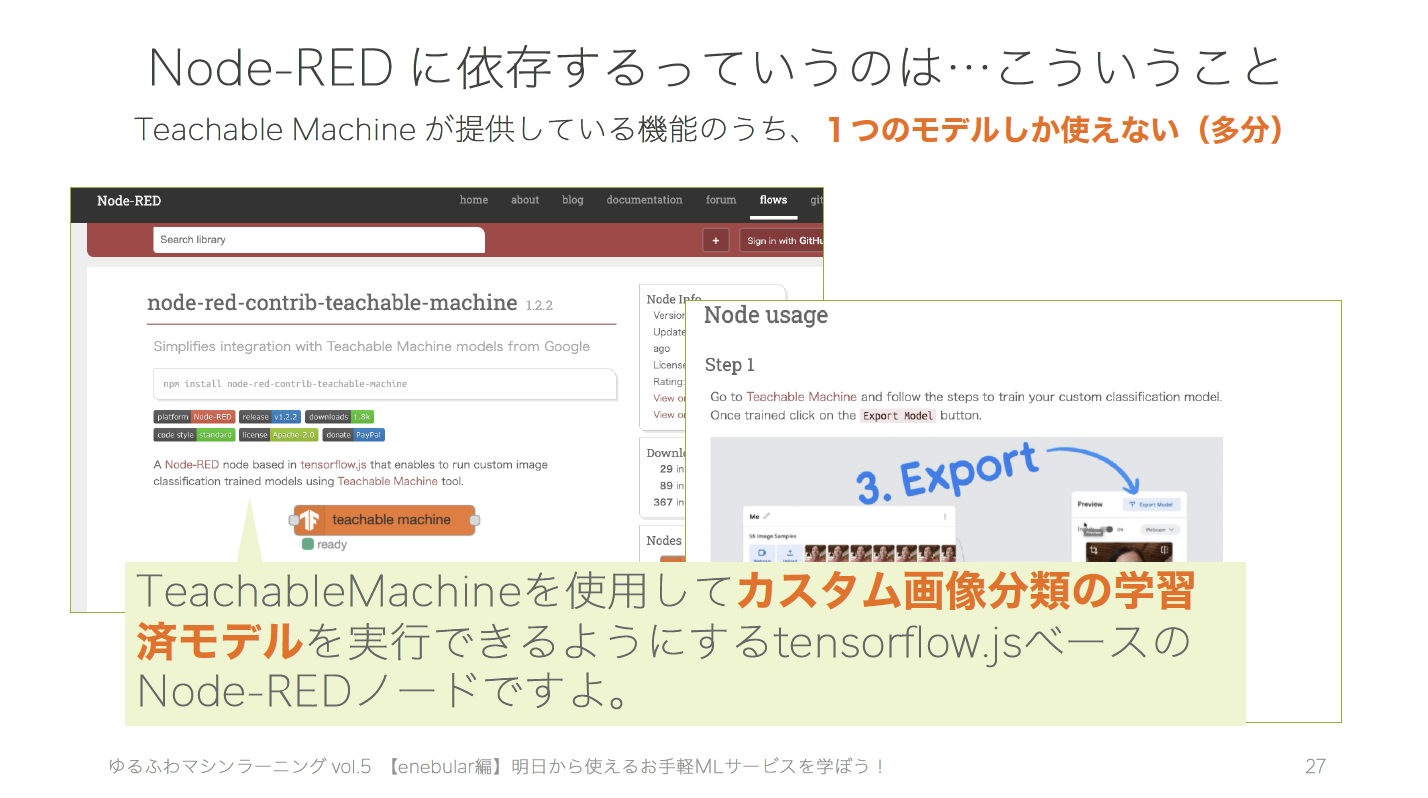
カスタム画像分類の学習済みモデルのライブラリのみ使用可能でした。
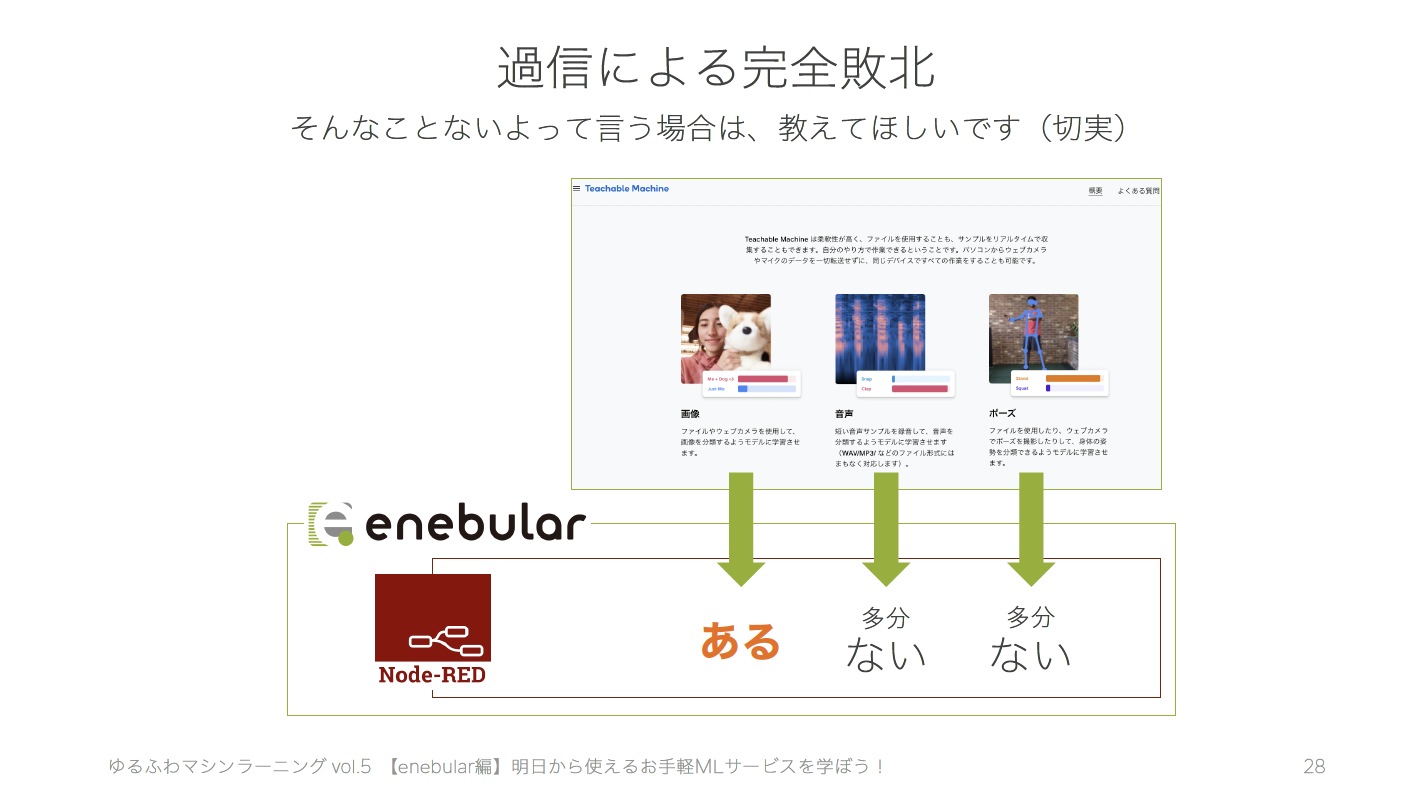
つまり、Node-REDでは、TeachableMachineでできる三種類の機械学習モデルのうち、1つしか使えませんでした。 普段の業務で当たり前のように無償ライブラリを駆使してデータ分析をやっている身からすると、改めてOSSコミッターのおかげで自分はプログラミングを楽しめたり簡単にキャッチアップしてコードを書くことができているんだなぁと実感しました。
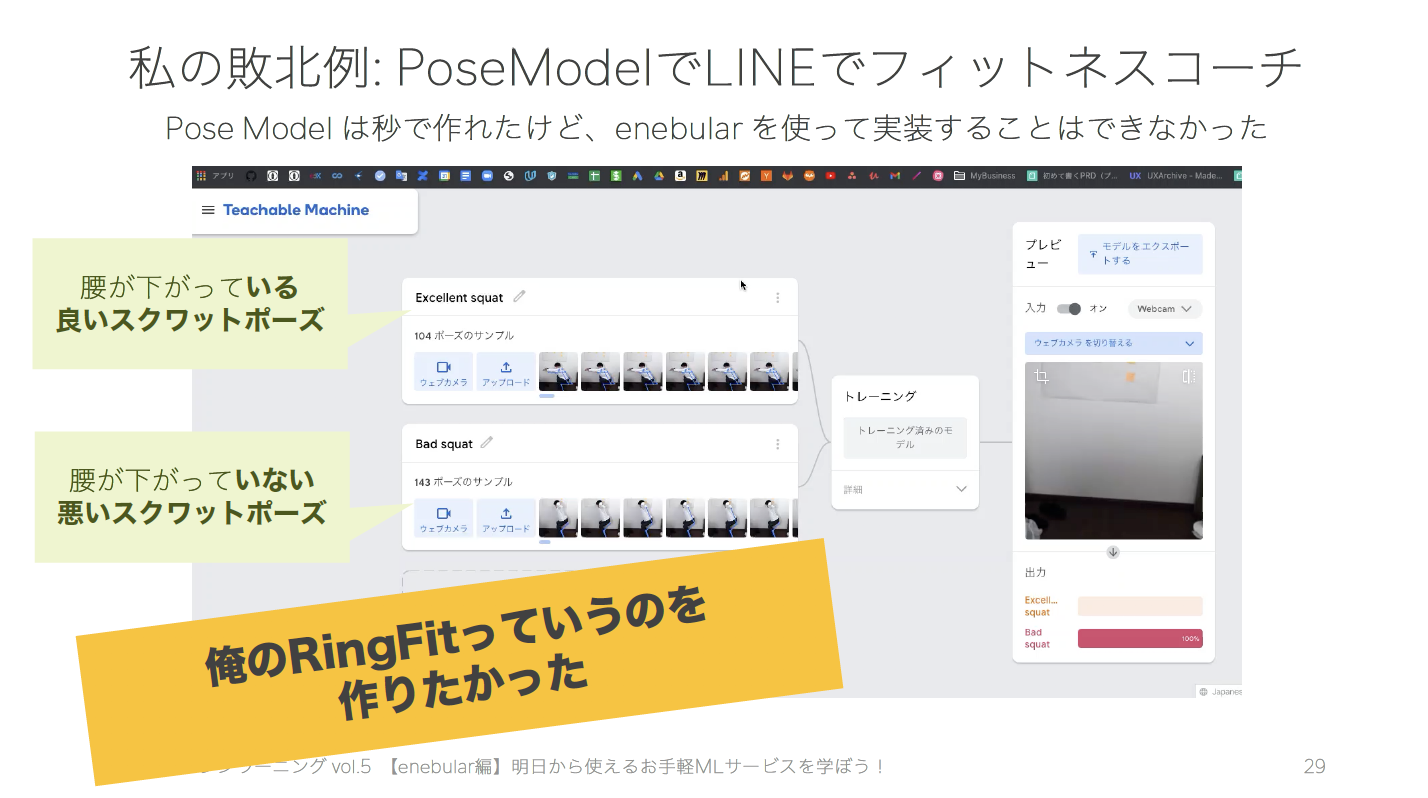
本当は、他の学習済みモデルで、「俺のRingFit」を作りたかったのです。!
おまけ
TeachableMachineの学習済みモデルによって、手軽に仕組みをつくれるということは、間違った予測結果を出力しがちというトレードオフの関係にあります

まとめ
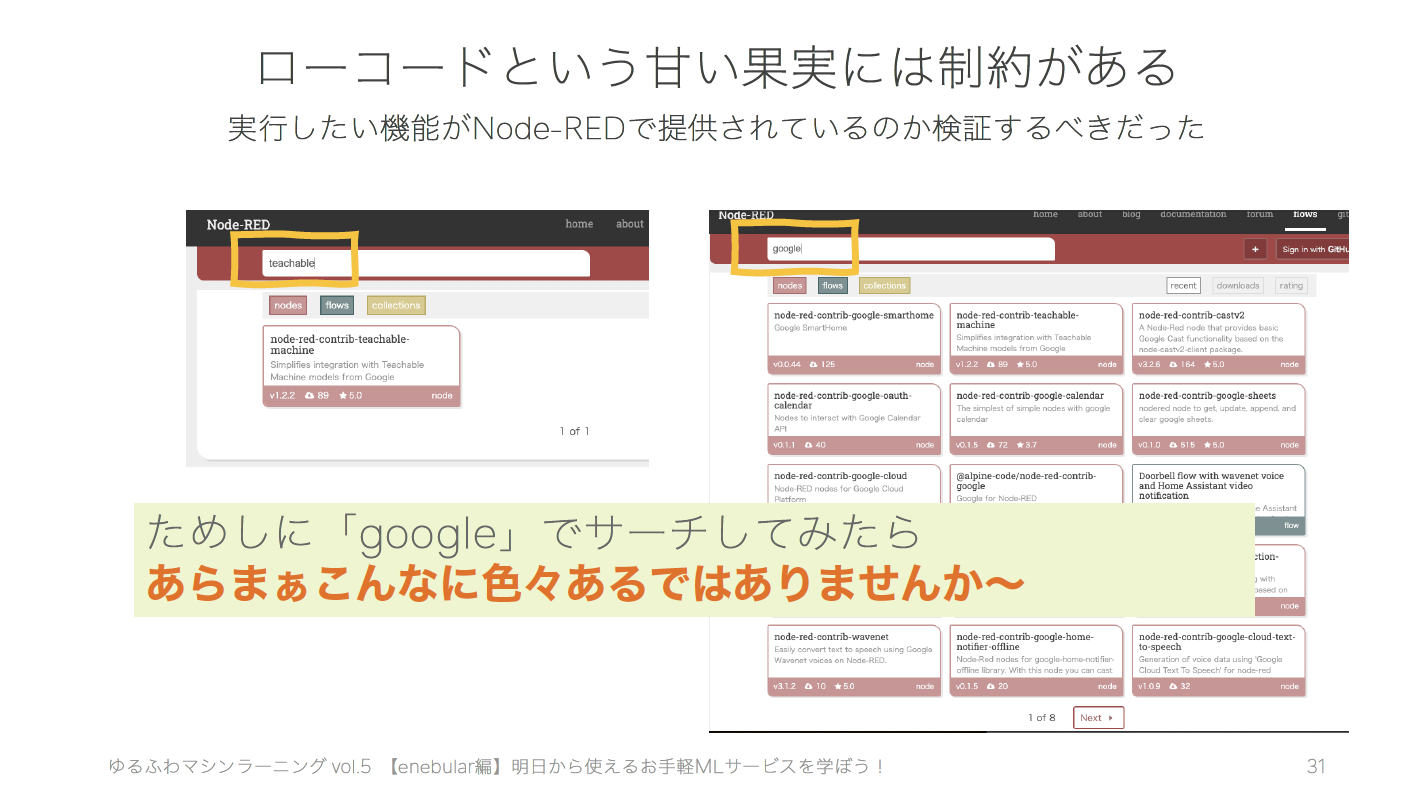
というわけで、enebular×ML(機械学習, マシーンラーニング)をやる場合は、実装したい機械学習ライブラリがNode-REDのライブラリに含まれているのかどうか?を探すことが先かもしれません。
自分が欲しいライブラリを作れる側になると、きっともっとenebularが楽しくなるなと思いつつ、メジャーな機械学習モデルを組み込んだプロトタイプを作ってみるのであれば、enebular×MLは確実に最高でGoodです。