本記事でやること
- Google のFLAN-UL2 を RTX 3090 一枚で動かす。
- CPUメモリを併用し,fp16にすることで動かすことができる。
- flanモデルを使ってai-chat-botのようにする。
プロンプトの仕組みはPrompt-Engineering-Guideを参考にする。- すでにgoogle colab上で実装されている方もいた。すごい。
@sakasegawa さん Google の FLAN-20B with UL2 を動かしてChatGPT APIのように使ってみる!
- すでにgoogle colab上で実装されている方もいた。すごい。
- ついでにstremamlitを使ってWEBAPPにしておく。
イメージ
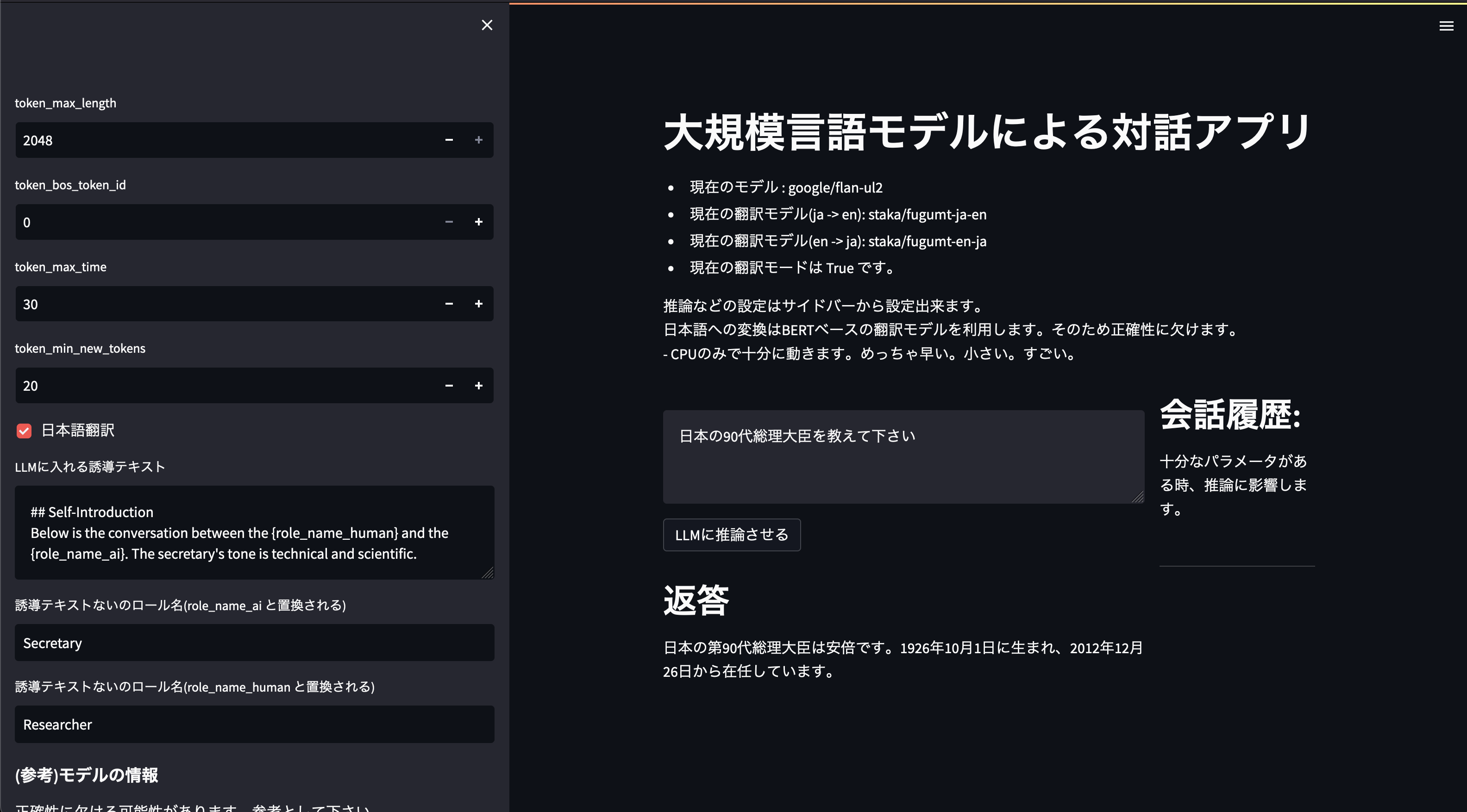
コード
動作のキモ
# GPUに全部は乗らないので、CPUメモリに載せる。
# RTX 3090想定
max_memory_mapping = {0: "22GiB", "cpu": "60GiB"}
if modelname == "google/flan-ul2":
# 8bitにしてもGPUに乗らないので、float16でCPUにも乗せる。
# 一度CPUに読み込ませたものを再割り当てするのが肝
config = AutoConfig.from_pretrained(new_path)
with init_empty_weights():
model = AutoModelForSeq2SeqLM.from_config(config)
device_map = infer_auto_device_map(
model,
max_memory=max_memory_mapping,
dtype=torch.float16,
no_split_module_classes=["T5Blocks"],
)
model = load_checkpoint_and_dispatch(
model, dtype=torch.float16, checkpoint=new_path, device_map=device_map
).eval()
最後に
20Bのモデルではうまく"コンテキストの理解"や"なりきり"がなされない模様。
175Bのモデルを動かすコストを考えるとChatGPT-APIのコストは異常に安い。どうなっているのだろう。
何か問題があればご連絡ください。