この記事について
kaggleに投稿されたこのKernelに沿って実装を行いつつ、手順の流れを噛み砕いて解説します。
筆者は初学者であるため、うまく説明できない部分も多々あると思いますのでご了承ください。
この記事の想定している対象読者はデータ分析の初学者、もしくはDota2等のMobaプレイヤーで機械学習に興味がある方です。
Dota2とは
Valve社からリリースされている無料のPCゲームです。5対5のチーム戦で行われます。
Esportsタイトルとして世界大会の賞金が大変高額であることで有名で、
「賞金20億円以上の大会が~」等とメディアで報道されていたら100%このゲームのことです。
2年前にkaggleで勝率予測の公式コンペを開催していたり、
最近だとOpenAI社と共同で強化学習を用いたゲーム内AIを開発し、プロチームと対戦させるというような試みも行っており、
データサイエンスと密接な関係を持っているゲームであるといえます。
何をするのか、あらかじめまとめ
試合開始時に各チームが選ぶHero(キャラクター)と、試合終了時の各プレイヤーの所持アイテム(1人につき6枠 × 5人 =30個)のデータから、どちらが勝利したのかをscikit-learnで決定木分析します。
試合終了時のデータを使用しているので、試合が始まる前から予測するモデルではなく、あくまで「(勝敗の結果だけ隠して)どっちが勝ったでしょうか?」という問いに答えるものとなっています。
というわけで、説明変数は以下の4つになります:
・RadiantのHero
・RadiantのItem
・DireのHero
・DireのItem
(Dota2を知らない方向け:Radiant,Direというのは陣営名であって、名前そのものに意味はありません。紅組・白組ぐらいのイメージでOKです)
データセット
こちらからDLできます。
実際に行われた50000戦について、選択したキャラクター、試合時間、勝敗など様々なデータが揃っています。
データの取得、確認
import pandas as pd
%matplotlib inline
players = pd.read_csv('../input/players.csv')
matches = pd.read_csv('../input/match.csv')
heroes = pd.read_csv('../input/hero_names.csv')
items = pd.read_csv('../input/item_ids.csv')
players.head(12)
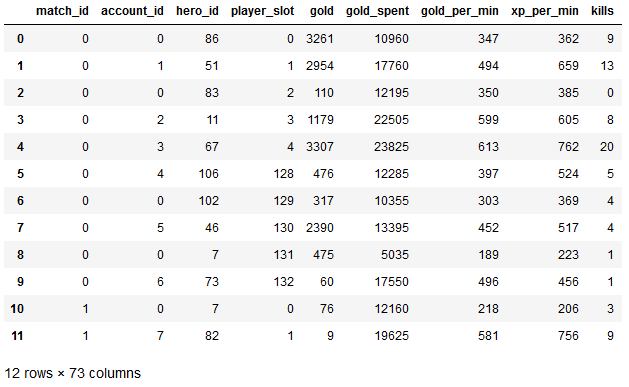
indexはプレイヤー、match_idは試合毎に振り分けられます。5対5のゲームなので1試合につき10人いることがわかります。
player_slotは0~4がRadiantチーム、128~132がDireチームなので、match_idで抽出したときの上5人と下5人がチームメイトになります。
データの整形
型の変更
今回使用するのはHeroとアイテムのデータですが、players.csvにおいてはいずれもidのint値(hero_id, item_0, ... , item_5)として保存されているので、名称の文字列を用いた列データを生成しておきます。
# hero名の文字列が入るcol "hero" を新たに生成
hero_lookup = dict(zip(heroes["hero_id"], heroes["localized_name"]))
hero_lookup[0] = "Unknown"
players["hero"] = players["hero_id"].apply(lambda _id: hero_lookup[_id])
players.loc[:,"hero"].head()
"""
>>>
0 Rubick
1 Clockwerk
2 Treant Protector
3 Shadow Fiend
4 Spectre
Name: hero, dtype: object
"""
# col "item_0", ... ,"item_5" の型を整数からゲーム内名称の文字列に変更
item_lookup = dict(zip(items['item_id'], items['item_name']))
item_lookup[0] = 'Unknown'
def find_item(_id):
return item_lookup.get(_id, str(_id))
players['item_0'] = players['item_0'].apply(find_item)
players['item_1'] = players['item_1'].apply(find_item)
players['item_2'] = players['item_2'].apply(find_item)
players['item_3'] = players['item_3'].apply(find_item)
players['item_4'] = players['item_4'].apply(find_item)
players['item_5'] = players['item_5'].apply(find_item)
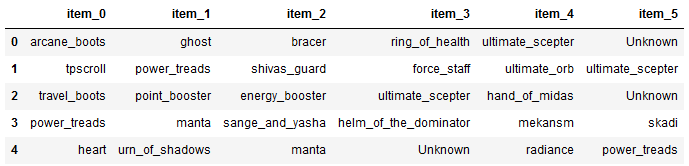
players.loc[:, "item_0":"item_5"].head()
変数の処理(dummy化)
先程完成した7つのcolについて、ダミー化を行います。
先程の作業をする前のidの整数値のままでダミー化・分析しても問題はありませんが、今回はidそのものの大小に意味がないことと、dfの可視性を良くするために行っています。
# "hero"列のダミー化
player_heroes = pd.get_dummies(players['hero'])
player_heroes.head(12)
# "item_0"から"item_5"列のダミー化
item0 = pd.get_dummies(players['item_0'].fillna(0))
item1 = pd.get_dummies(players['item_1'].fillna(0))
item2 = pd.get_dummies(players['item_2'].fillna(0))
item3 = pd.get_dummies(players['item_3'].fillna(0))
item4 = pd.get_dummies(players['item_4'].fillna(0))
item5 = pd.get_dummies(players['item_5'].fillna(0))
item0.info() #500000人分のitem1枠目の情報(どれかの列が1,それ以外全部0)
ここまで、アイテムの6スロットについて独立に考えていましたが、
このゲームにおいてスロットの入れ替えは自由であり、[アイテムA,アイテムB]という順番で保持しているのと[アイテムB,アイテムA]という順番ではゲームの結果に何も影響しません。(使うために押すコマンドが変わるぐらい)
よって、各列の各要素を足し合わせて一つの列にしてしまいます。
# 各スロットのアイテム情報を足し合わせたcol"player_items"を生成
player_items = item0 \
.add(item1, fill_value=0) \
.add(item2, fill_value=0) \
.add(item3, fill_value=0) \
.add(item4, fill_value=0) \
.add(item5, fill_value=0)
player_items.info() #500000人分のitemの情報(持ってるitemの列に持ってる個数が入る,持ってないアイテムには0)
このように、「データのどの部分に意味があり、どの部分に意味が無いのか」という事前知識が要求される点が、個人的には一筋縄ではいかず面白いと思っています。
所属チーム分け
変数が4つ必要なので、ここまで整理したHeroとItemのデータをチーム毎に再配置する必要があります。
# 各チームのheroのcol名リストを作成
radiant_hero_cols = list(map(lambda s: 'radiant_' + s, player_heroes.columns.values))
dire_hero_cols = list(map(lambda s: 'dire_' + s, player_heroes.columns.values))
# 各チームのitemのcol名リストを作成
radiant_items_cols = list(map(lambda s: 'radiant_' + str(s), player_items.columns.values))
dire_items_cols = list(map(lambda s: 'dire_' + str(s), player_items.columns.values))
from os.path import isfile
X = None
if isfile('mapped_match_hero_item.csv'):
X = pd.read_csv('mapped_match_hero_item.csv')
else:
radiant_heroes = []
dire_heroes = []
radiant_items = []
dire_items = []
# groupby("match_id").groups = {"特定のマッチid": そのindexのリスト}
for _id, _index in players.groupby('match_id').groups.items(): # ex. [0,1,...,9]
# 1マッチのradiantのhero5体のリスト[0,0,1,0,...]を作成 indexはheroid,つまり1が5カ所であとは0
radiant_heroes.append(player_heroes.iloc[_index][:5].sum().values)
# 1マッチのdireのhero5体のリスト[0,0,1,0,...]を作成 (上に同じ)
dire_heroes.append(player_heroes.iloc[_index][5:].sum().values)
# 1マッチのraidantのitem全部のリスト[0,0,1,0,...]を作成 indexはitemid,つまりチーム全体の所持数
radiant_items.append(player_items.iloc[_index][:5].sum().values)
# 1マッチのdireのitem全部のリスト[0,0,1,0,...]を作成 indexはitemid,つまりチーム全体の所持数
dire_items.append(player_items.iloc[_index][5:].sum().values)
radiant_heroes = pd.DataFrame(radiant_heroes, columns=radiant_hero_cols)
radiant_heroes.head()
dire_heroes = pd.DataFrame(dire_heroes, columns=dire_hero_cols)
radiant_items = pd.DataFrame(radiant_items, columns=radiant_items_cols)
dire_items = pd.DataFrame(dire_items, columns=dire_items_cols)
X = pd.concat([radiant_heroes, radiant_items, dire_heroes, dire_items], axis=1)
X.to_csv('mapped_match_hero_item.csv', index=False)
X.info() # 50000試合分のチーム毎のhero,itemにちゃんとなっているか確認
"""
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Columns: 612 entries, radiant_Abaddon to dire_yasha
dtypes: float64(390), int64(222)
memory usage: 233.5 MB
"""
これで説明変数Xのデータが完成しました。
次に、目的変数yを設定します。
各行はXと同じくmatch idが、列には「勝利したチーム」のデータが入るようなものを用意します。
y = matches['radiant_win'].apply(lambda win: 1 if win else 0)
classes = ['Dire Win', 'Radiant Win']
y.head()
"""
>>>
0 1
1 0
2 0
3 0
4 1
Name: radiant_win, dtype: int64
"""
決定木モデルの作成
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
元のKernelでは決定木の可視化も行っていましたが、筆者が完全に理解できていない点があるため本記事では省略します。
def build_decision_tree(X, y, depth=None):
dt = DecisionTreeClassifier(random_state=42, max_depth=depth)
print('CV score:', cross_val_score(estimator=dt, X=X, y=y).mean()) # 交差検証スコアを表示
dt.fit(X, y) # 決定木予測モデルを構築
return dt
dt = build_decision_tree(X=X, y=y, depth=10)
# CV score: 0.8341599902671333
まとめ
ザックリ言うと、約83.4%の確率で勝敗を正しく予想するモデルが作れました。
自分のDota2の経験と知識をもってこの予測問題をやらされたとすると、多分正答率70数%ぐらいかなあと勝手に思っています。
今回の内容を少し書き変えるだけでも、試合開始前のHero選択において、相手や味方のHeroを見てから「勝ちやすい」Heroを選ぶような問題に当てはめることができそうなので、後日挑戦してみます。