VOICEPEAKの音声に字幕をつけて動画をつくる際に便利なPythonスクリプトをつくったので記事にします。
このスクリプトを使えばVOICEPEAKで音声ファイルを大量に出力した時でも、
ほぼドンピシャのタイミングで字幕を出すことができるはずです。1
この記事の成果物のサンプル(Youtube)
この記事で紹介するスクリプトで作成した動画です。
※ この動画は簡単のため黒背景に音声と字幕だけですが、ちゃんと映像も入れられます。
本記事の構成
- 記事の前半でVOICEPEAK〜動画編集ツールまでの一貫した流れで手順を説明します。
- 記事の後半で具体的なコードの内容を説明します。
- 記事の末尾にコード全文を掲載します。(コピペ用)
本記事の想定読者
- VOICEPEAKユーザー
- VOICEPEAKの音声にあわせて字幕を出したい! と思っている
- Python3を実行できる環境がある(Python3.10で動作確認)
- SubRip(.srt)ファイルで動画に字幕をつけるツールがある。2
このスクリプトは何をするものか?
- VOICEPEAKが出力した各音声ファイルの再生時間を計算する
- 計算した再生時間をもとに各セリフの字幕を出すタイミングを割り出す
- 字幕を出すタイミングとセリフの内容をSubRipファイルとして書き出す
前半: 字幕ファイル作成の手順
手順の概要
- VOICEPEAKで動画にしたいファイルを作成する
- 音声とセリフを保存するための新規フォルダを作成する
- 作成したフォルダに音声とセリフを連番で保存する
- 本記事のスクリプトを使って字幕ファイルを作成する
- 音声と字幕ファイルを動画編集ツールに読み込ませる
手順詳細
1. VOICEPEAKで動画にしたいファイルを作成する
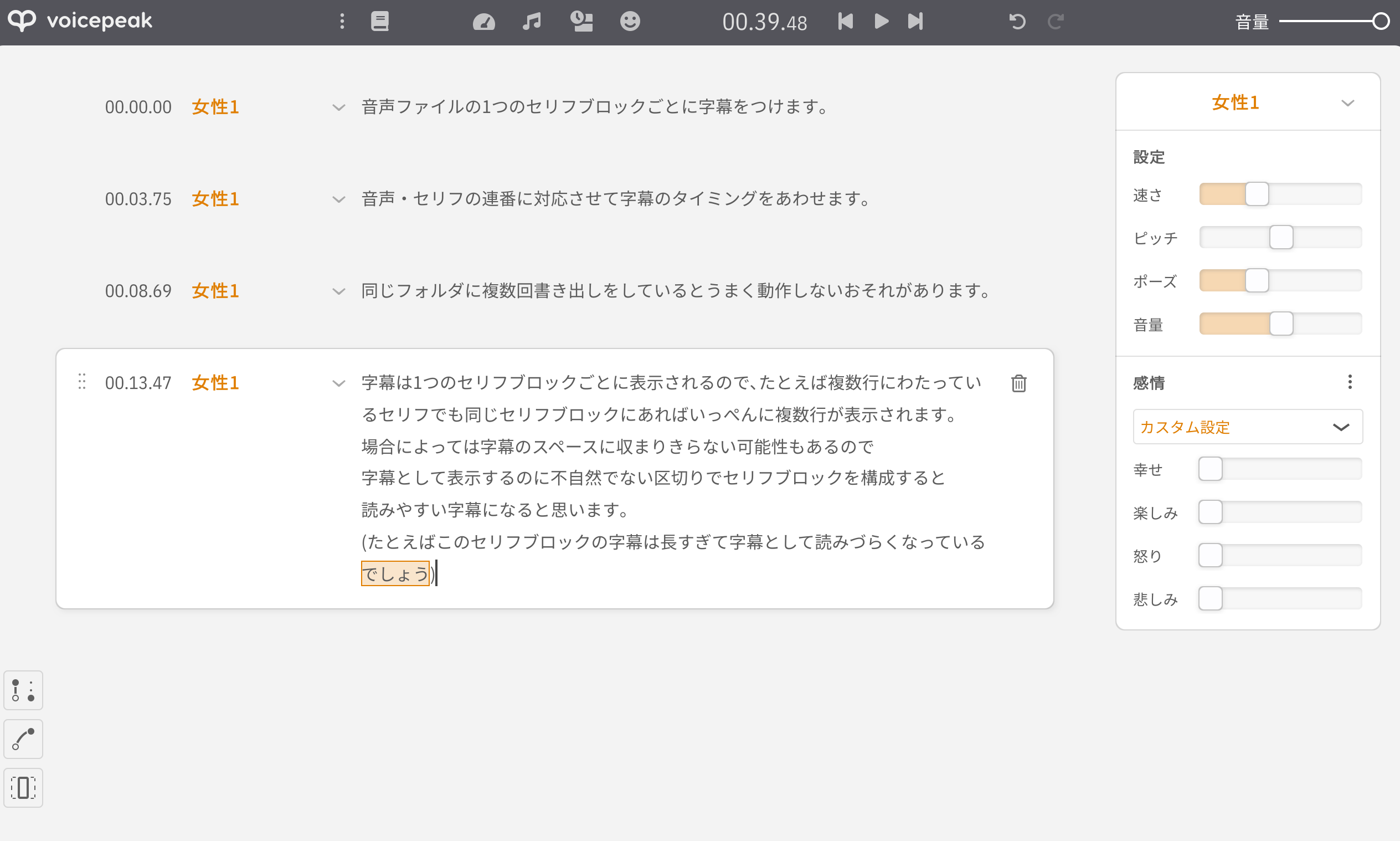
たとえば以下のような内容のファイルに字幕をつけることを考えます。
2. 音声とセリフを保存するための新規フォルダを作成する
フォルダの位置は好きなところで構いません。
3. 作成したフォルダに音声とセリフを連番で出力する
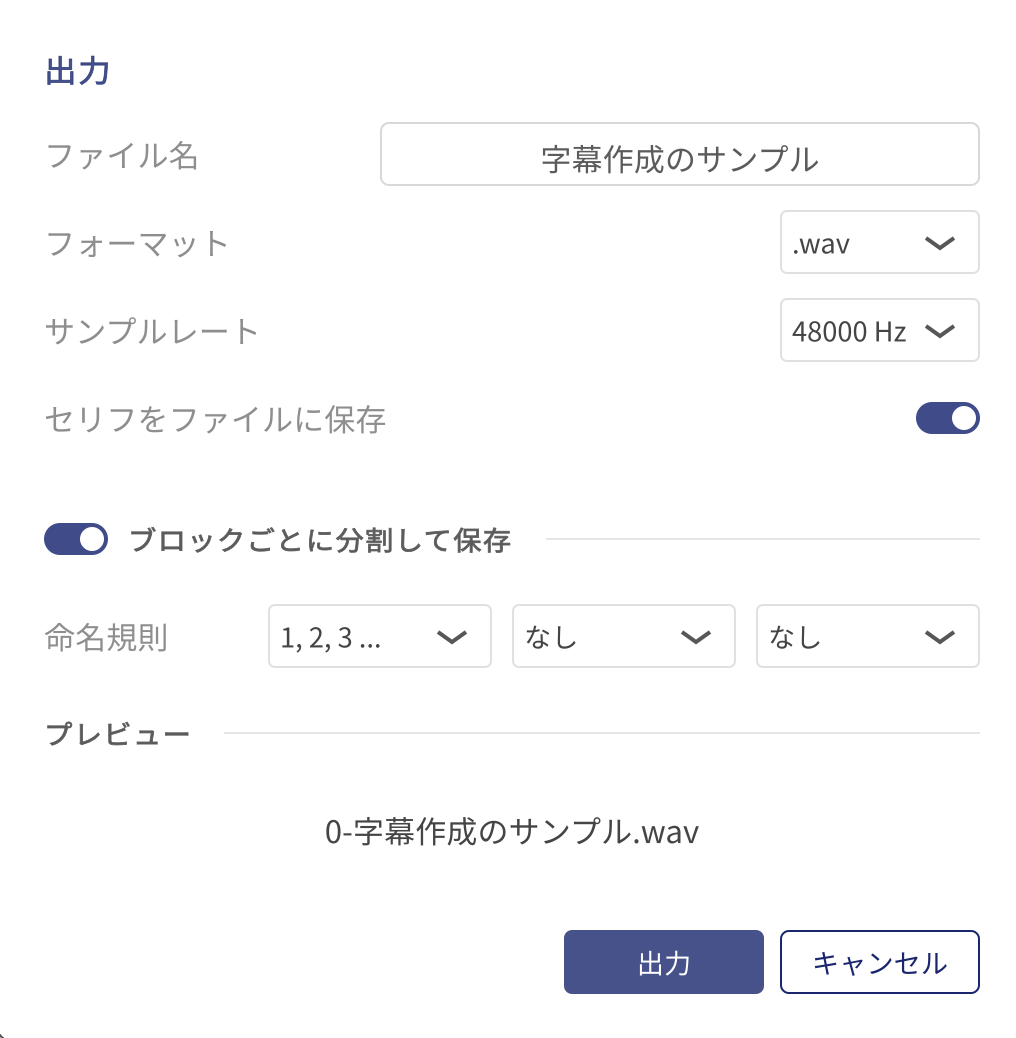
- [︙メニュー]>[出力]を選択
- [セリフをファイルに保存]をONにする
- [ブロックごとに分割して保存]をONにする
- 命名規則で[1,2,3…]を選択する
- 手順2で作成したフォルダにファイルを出力する
4. 本記事のスクリプトを使って字幕ファイルを作成する
- 手順2で作成したフォルダを指定して本記事のスクリプトを実行する
make_srt_file(folder='sample_folder', filename='sample_jimaku.srt')
コードの内容については記事の後半で説明します。
スクリプトの実行結果の例を以下に示します。3
1
00:00:00,000 --> 00:00:03,743
音声ファイルの1つのセリフブロックごとに字幕をつけます。
2
00:00:03,743 --> 00:00:08,670
音声・セリフの連番に対応させて字幕のタイミングをあわせます。
3
00:00:08,670 --> 00:00:13,432
同じフォルダに複数回書き出しをしているとうまく動作しないおそれがあります。
4
00:00:13,432 --> 00:00:40,303
字幕は1つのセリフブロックごとに表示されるので、たとえば複数行にわたっているセリフでも同じセリフブロックにあればいっぺんに複数行が表示されます。 場合によっては字幕のスペースに収まりきらない可能性もあるので 字幕として表示するのに不自然でない区切りでセリフブロックを構成すると 読みやすい字幕になると思います。 (たとえばこのセリフブロックの字幕は長すぎて字幕として読みづらくなっているでしょう)
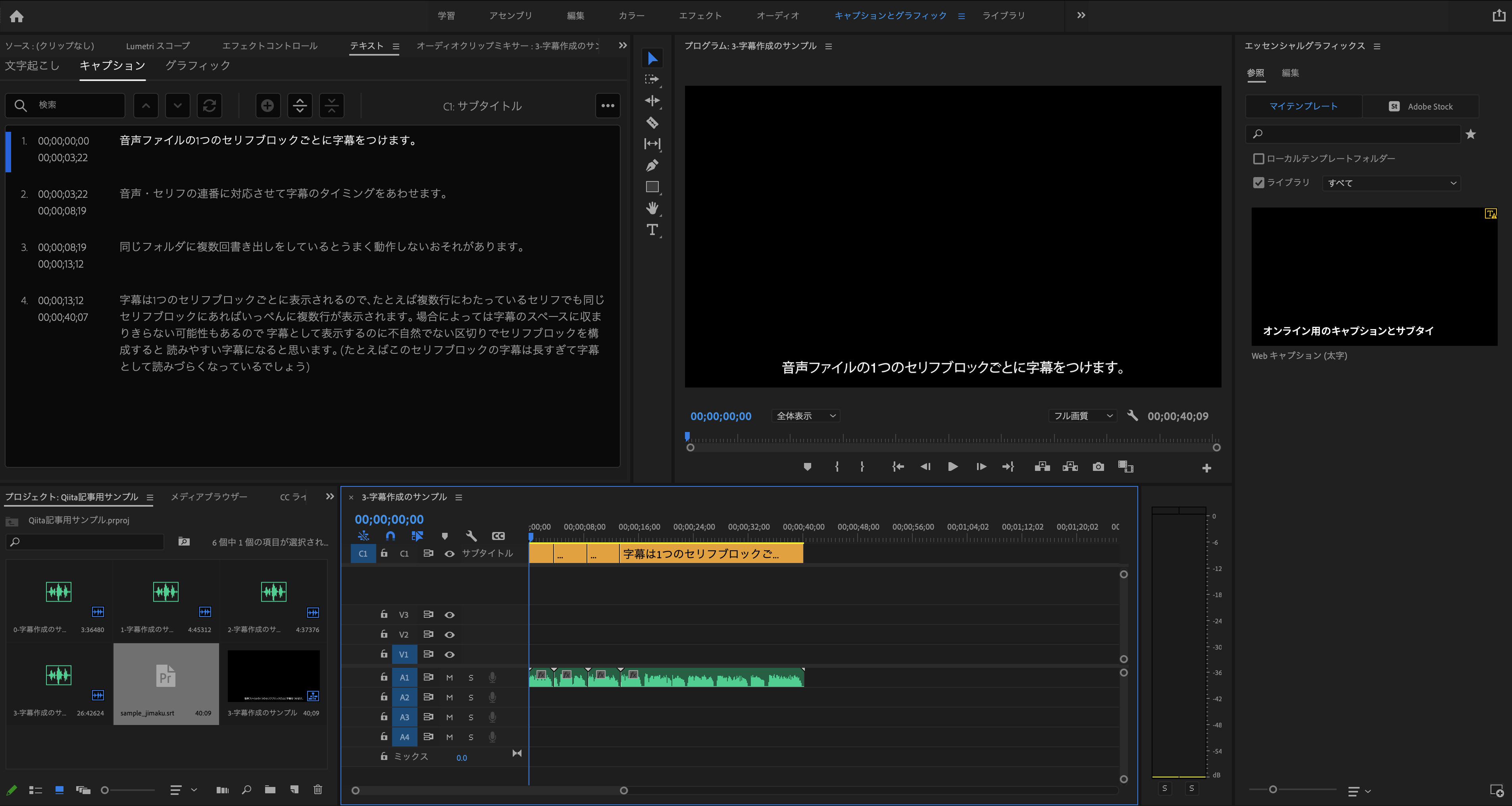
5. 音声・字幕ファイルを動画編集ツールに読み込ませる
本記事ではPreimere Proを利用しました。
ツールの使い方の説明は各ツールのマニュアル等に譲ります。
後半: 字幕ファイルをつくるスクリプト
コード全文は記事末尾に記載しています。
このスクリプトは何をするものか?(再掲)
- VOICEPEAKが出力した各音声ファイルの再生時間を計算する
- 計算した再生時間をもとに各セリフの字幕を出すタイミングを割り出す
- 字幕を出すタイミングとセリフの内容をSubRipファイルとして書き出す
実行環境
platform.python_version()
# '3.10.2'
platform.platform()
# 'macOS-12.2.1-x86_64-i386-64bit'
コードの解説
関数をピックアップしながらざっくりとコードの説明をします。
用語の注意
これ以降字幕用のSubRip(.srt)ファイルを単にsrtファイルと呼びます。
必要なライブラリのimport
import wave
import glob
import textwrap
from typing import NamedTuple
from datetime import timedelta
1つの字幕を生成するのに必要なデータを入れるNamedTupleの定義
class SrtInfo(NamedTuple):
"""SubRipファイル(.srt)に必要なデータを格納する
最終的に以下のような形式のファイルを作成する
---
1
00:02:16,612 --> 00:02:19,376
Senator, we're making
our final approach into Coruscant.
---
上記の場合の各変数は以下のとおり
num = 1
start = '00:02:16,612'
end = '00:02:19,376'
text = 'Senator, we're making\nour final approach into Coruscant.'
"""
num: int
start: str
end: str
text: str
srtファイルをつくる関数本体の定義
この関数内に現れる他の関数はこのあと登場します。
なお、srtファイルの書き込みを追記モード(mode='a')で行う都合上、
最初に書き込みモード(mode='w')でファイルを初期化しています。
def make_srt_file(folder: str, filename: str) -> None:
"""指定したフォルダのデータからSubRipファイルを出力する
Args:
folder(str): 音声・テキストファイルがあるフォルダ名
ここでは1フォルダに複数種類の音声・テキストはないものとする
filename(str): 書き出すファイル名(拡張子.srtを含める)
(例) jimaku.srt
Return:
None
"""
txtfiles = get_txt_files(folder)
wavfiles = get_wav_files(folder)
# SubRipファイルの初期化
with open(filename, mode='w') as f:
f.write('')
srtinfo_list = make_srtinfo_list(txtfiles, wavfiles)
for srtinfo in srtinfo_list:
write_srttime(srtinfo, filename)
セリフテキストと音声のファイル名を取得する関数
セリフテキストと音声の対応付けはそれぞれの関数のsorted()で行っています。
他のファイルが混ざったりすると字幕のタイミングがズレるおそれがあります。
def get_txt_files(folder: str) -> list:
return sorted(glob.glob(f'{folder}/*.txt'))
def get_wav_files(folder: str) -> list:
return sorted(glob.glob(f'{folder}/*.wav'))
テキスト・音声ファイルからsrtファイルに必要な情報を抽出する関数
この関数内に現れる他の関数はこのあと登場します。
なお、筆者の環境では単純に再生時間を累計するとズレが生じたので、途中で微調整を入れています4。
def make_srtinfo_list(txtfiles: list, wavfiles: list) -> list:
"""SubRipファイルに必要な情報をまとめたSrtInfoのリストをつくる"""
basetime = timedelta(0, 0, 0)
srtinfo_list = []
for i, (t, w) in enumerate(zip(txtfiles, wavfiles)):
text = get_text(t)
start = format_srttime(basetime)
playtime = calc_playtime(w)
# 若干時間を削ったほうが整合する。丸め誤差の影響か?
playtime -= 0.017
basetime = basetime + timedelta(seconds=playtime)
end = format_srttime(basetime)
srtinfo = SrtInfo(i+1, start, end, text)
srtinfo_list.append(srtinfo)
return srtinfo_list
セリフのテキストファイルを読み込む関数
筆者が使っているPreimere Proでは1行の字幕の文字数が300文字程度を超えるとエラーを起きました。
そのエラーを回避するために200文字でテキストを改行するようにしています。
def get_text(txt_file: str) -> str:
with open(txt_file, mode='r') as f:
text = f.read()
# 一行あたりの文字数が300あたりを超えるとPremiere Proがエラーを起こすので改行を挟む
return textwrap.fill(text, 200)
再生時間の計算結果をsrtファイル形式の時間表示にする関数
この関数については過去に単独で記事を書いたのでよければ参照してください。
def format_srttime(timedelta: timedelta) -> str:
"""timedeltaをSubRip形式の時間表示にフォーマットする"""
ss, mi = divmod(timedelta.total_seconds(), 1)
mi = int(round(mi, 3)*1000)
mm, ss = divmod(ss, 60)
hh, mm = divmod(mm, 60)
srttime = f'{int(hh):02}:{int(mm):02}:{int(ss):02},{mi:03}'
return srttime
再生時間を計算する関数
waveファイルから単純に再生時間を取得することができなかったので、
フレームレートとフレーム数から再生時間を計算しています。5
def calc_playtime(wav_file: str) -> float:
"""waveファイルのフレームレートとフレーム数から再生時間を計算する"""
with wave.open(wav_file, mode='rb') as wr:
fr = wr.getframerate()
fn = wr.getnframes()
playtime = fn/fr
return playtime
srtファイルを書き出す関数
ようやく最後の関数です。
srtファイルのお作法にならって書き出します。
def write_srttime(srt: SrtInfo, filename: str) -> None:
"""SrtInfoを受け取ってSubRipファイルに必要な情報を順次加筆していく"""
with open(filename, mode='a') as f:
srt_items = [
str(srt.num)+'\n',
f'{srt.start} --> {srt.end}\n',
srt.text+'\n\n'
]
f.writelines(srt_items)
まとめ
この記事の成果物のサンプル(Youtube) ※ 再掲
上記のスクリプトでsrtファイルをつくり、字幕を埋め込んだのが冒頭の動画です。
これで動画編集時にセリフにあわせてテキストを再入力する手間が省けます。
これでVOICEPEAKを使った動画編集が捗りそうですね!6
おまけ動画
筆者が過去にこのスクリプトを使って作成した動画を掲載します。
民法 第一編 総則 (条文読み上げ)
民法の条文をVOICEPEAKが読み上げてくれて、字幕もついてきます。7
上記の動画以外にも民法第二編〜民法第四編の動画も作りました。
合計すると7時間分くらいの動画になります。
これに手作業で字幕つけることを考えるとぞっとしますね。
コード全文
コード全文(クリックで表示)
import wave
import glob
import textwrap
from typing import NamedTuple
from datetime import timedelta
class SrtInfo(NamedTuple):
"""SubRipファイル(.srt)に必要なデータを格納する
最終的に以下のような形式のファイルを作成する
---
1
00:02:16,612 --> 00:02:19,376
Senator, we're making
our final approach into Coruscant.
---
上記の場合の各変数は以下のとおり
num = 1
start = '00:02:16,612'
end = '00:02:19,376'
text = 'Senator, we're making\nour final approach into Coruscant.'
"""
num: int
start: str
end: str
text: str
def make_srt_file(folder: str, filename: str) -> None:
"""指定したフォルダのデータからSubRipファイルを出力する
Args:
folder(str): 音声・テキストファイルがあるフォルダ名
ここでは1フォルダに複数種類の音声・テキストはないものとする
filename(str): 書き出すファイル名(拡張子.srtを含める)
(例) jimaku.srt
Return:
None
"""
txtfiles = get_txt_files(folder)
wavfiles = get_wav_files(folder)
# SubRipファイルの初期化
with open(filename, mode='w') as f:
f.write('')
srtinfo_list = make_srtinfo_list(txtfiles, wavfiles)
for srtinfo in srtinfo_list:
write_srttime(srtinfo, filename)
def get_txt_files(folder: str) -> list:
return sorted(glob.glob(f'{folder}/*.txt'))
def get_wav_files(folder: str) -> list:
return sorted(glob.glob(f'{folder}/*.wav'))
def make_srtinfo_list(txtfiles: list, wavfiles: list) -> list:
"""SubRipファイルに必要な情報をまとめたSrtInfoのリストをつくる"""
basetime = timedelta(0, 0, 0)
srtinfo_list = []
for i, (t, w) in enumerate(zip(txtfiles, wavfiles)):
text = get_text(t)
start = format_srttime(basetime)
playtime = calc_playtime(w)
# 若干時間を削ったほうが整合する。丸め誤差の影響か?
playtime -= 0.017
basetime = basetime + timedelta(seconds=playtime)
end = format_srttime(basetime)
srtinfo = SrtInfo(i+1, start, end, text)
srtinfo_list.append(srtinfo)
return srtinfo_list
def get_text(txt_file: str) -> str:
with open(txt_file, mode='r') as f:
text = f.read()
# 一行あたりの文字数が300あたりを超えるとPremiere Proがエラーを起こすので改行を挟む
return textwrap.fill(text, 200)
def format_srttime(timedelta: timedelta) -> str:
"""timedeltaをSubRip形式の時間表示にフォーマットする"""
ss, mi = divmod(timedelta.total_seconds(), 1)
mi = int(round(mi, 3)*1000)
mm, ss = divmod(ss, 60)
hh, mm = divmod(mm, 60)
srttime = f'{int(hh):02}:{int(mm):02}:{int(ss):02},{mi:03}'
return srttime
def calc_playtime(wav_file: str) -> float:
"""waveファイルのフレームレートとフレーム数から再生時間を計算する"""
with wave.open(wav_file, mode='rb') as wr:
fr = wr.getframerate()
fn = wr.getnframes()
playtime = fn/fr
return playtime
def write_srttime(srt: SrtInfo, filename: str) -> None:
"""SrtInfoを受け取ってSubRipファイルに必要な情報を順次加筆していく"""
with open(filename, mode='a') as f:
srt_items = [
str(srt.num)+'\n',
f'{srt.start} --> {srt.end}\n',
srt.text+'\n\n'
]
f.writelines(srt_items)
-
筆者はこのスクリプトで1本の動画あたり最大で約1200件の音声ファイルに字幕をつけました。
ただし、動画の編集時に音声のタイミングを変更をしたら字幕も手動であわせる必要があります。
とはいえゼロベースよりだいぶ楽になるとは思います。 ↩ -
本記事ではAdobeのPreimere Proを使いました。
Youtubeであれば動画をアップしたあとに字幕をつけることもできるようです。 ↩ -
筆者はsrt拡張子ファイルの中身の確認にVisual Studio Codeを使いました。
SubRipファイルについてはこちら; SubRip -Wikipedia- ↩ -
具体的には約1200ファイルを同時に読み込んだ際に音声と字幕に20秒程度のズレが生じました。
再生時間を毎回-0.017秒ずつ引くとズレが解消したのでそれをコードに反映しています。 ↩ -
こちらの記事を参考にさせていただきました。
PythonでWAVファイルの情報を最も簡単に取得する方法 ↩ -
と言いつつ筆者は動画を作成しないのでこのスクリプトがどれくらい役に立つのか正直わかりません。 ↩
-
動画制作の実験が主眼だったためVOICEPEAKの読み上げに対してほとんど調整を入れていません。
よって用語の読み、イントネーションに不正確な部分が多々あると思います。
この動画を使った民法の勉強は自己責任でお願いします。あしからず。 ↩