今日は、「まず」質の悪い経路でもなんでもよいので探索して、次第に解を改善していくようなアルゴリズム、Anytime アルゴリズム を解説します。
Anytime Algorithm
以前お話をしたとおり、まず「とりあえずの経路」をすばやく用意して、余った時間でさらに良い解を探す、という手法は、ロボットやカーナビを含む様々なアプリケーションで有効な手法です。まさに、プログラミングに代表される継続的改善と同じですね。こうすることで、例えば「3分以内になるべく良い解を求めよ」というような要求に答えられます。
より本質的に Anytime Algorithm を特徴づけるのは、 中断可能(Interruptible) であることです。最小の時間で(質が悪くとも)何らかの経路を出力することができる Anytime Algorithm は、状況の突然の変化に対してロバストです。例えば、探索問題を解いている途中に突然停電や回線遮断が起きた場合にも、すでに求めた非最適な解をすでにどこかに送信していれば、受信先で経路の実行が不可能になるということがありません。
広義の Anytime Algorithm とは、素早い探索時間を得るために、解の なんらかのクオリティ を諦める、つまり 時間と質のトレードオフ を行う、実用的なアプリケーションを作るためのアルゴリズムです。ここで なんらかのクオリティ というのはどのような指標(metric)でもよいのですが、実用上意味があると考えられているものには以下のようなものがあります。 Zilberstein, Shlomo, and Stuart Russell. "Approximate reasoning using anytime algorithms." KLUWER INTERNATIONAL SERIES IN ENGINEERING AND COMPUTER SCIENCE (1995): 43-43. Springerでただで読めます
- 確度(Certainty) . 確度をトレードオフにするAnytimeアルゴリズムは、実際に通れる(実行可能な)経路であるかの確実性を犠牲にして、素早い意思決定を行います。確度は確率(Probability)によって計算できます。
- 精度(Accuracy) . 精度をトレードオフにするAnytimeアルゴリズムは、解のコストを犠牲にして、素早い意思決定を行います。
- 詳細度(Specificity) . 詳細度をトレードオフにするAnytimeアルゴリズムは、解の詳細な記述を諦め、経路についての大雑把な説明を得ることで、素早い意思決定を行います。
これらのアルゴリズムは、トレードオフのないアルゴリズムにはなかった様々な新たな種類の問題を提起することになります。たとえば、ある指標 X を時間とトレードオフする Anytime Algorithm A があるとして、以下のような問題を投げかけることができます。
- A の X に関する性能は どのように計測されるべきか?
- A の X に関する性能は 与えられた時間 $t$ に対してどのように変化するのか?
- X に関する最低限の指標が与えられた時、どれだけの $t$ が必要か? (2. の逆関数)
-
- が実際に問題を解いて計測しないとわからない場合、過去の実行例からどのように学習し予測を行っていくべきか?
以上のように Anytime Algorithmは、「解を見つけた、見つけられなかった」で説明できる普通のアルゴリズム(たとえばA*)とくらべて、より複雑な問題設定を抱えています。「時間」という資源に対する意思決定を行うことから、Anytime Algorithm は経済学との接点でもあります。
精度をトレードオフにする Anytime Algorithm
今日は Accuracy をターゲットにするAnytime アルゴリズムを扱います。(精度と詳細度のAnytimeは解説できますが、確度のAnytimeは自分には解説できません --- もしかして日本ってPOMDPの専門家も居ないんじゃないの?) グラフ探索において、現状そのような手法はおおよそ2つに大別されます:
- Plan Optimization. なんらかのアルゴリズムで解を求め、その後 GCC や Clang が行うような後処理最適化を施すもの。Block Deordering(Siddiqui, Haslum, JAIR 54:369–435), Neighborhood Graph(Nakhost & Muller, 2010), Dependency Analysis(Chrpa, McClusky, Osborne, ICAPS12) など。この後処理最適化にもある程度時間と探索が必要です(局所探索など)。コンパイラ技術との関連が大。
- Anytime Search. GBFS, WA* などをベースに、ヒューリスティクスの質をだんだん良くしたり、重み$w$の値をだんだん小さくしたりするもの。Anytime WA*(Hansen & Zhou, 2007), Anytime Repairing A*(Likhachev 2008), Restarting WA*(Richter, Thayer, Ruml 2010) など。
今日はさらにこの後者の話をします。AとWAの話をわかっていればそんなに難しくありません。
Anytime A*
最も単純な、ある意味、Anytime A* のベースラインとも言うべき実装は、一度解が見つかったら、見つかった解のコスト $c$ を上界として枝刈りをしつつ探索を実行するというものです。$w$もヒューリスティクスも変更しません。
この基本となるアルゴリズムはありましたが、これをAの特徴を保ったまま発展させようとした人がしばらく居なかったようです。たとえば、Depth-based Branch-and-Bound (Korf 1993), Complete Anytime Beam Search(Zhang 1998), Beam-stack Search(Zhou, Hansen 2005), ABULB(Furcy 2004) など。これらは重複検知を一部行わないアルゴリズムで、どちらかというとメモリ使用量を減らすためのIDA系のアルゴリズムです。
次に紹介する論文が出る2008年あたりまでは、ハードウェアの進歩が追いついておらず、まだA系のメモリを大量に使用するアルゴリズムは不適切だったのかもしれません。Aは、ハードウェアの制約が緩和されることによりようやく広く実用的に研究され始めたアルゴリズムと言えるでしょう。
ARA*: Anytime A* with provable bounds on sub-optimality. In Artifical Intelligence (AIJ 2008) 172:1613-1643.
ARA* (Anytime Repairing A*) は、WA* をベースに $w$ をだんだん小さくしながら解を改善していくという、いわゆる Anytime A* の問題に真正面から取り組んだアルゴリズムです。論文によれば、それまでに提案されていたアルゴリズムには、Anytime, Incremental, かつA*のように同じノードの重複検知を常に行うアルゴリズムとしては始めてであるようです。
ごちゃごちゃ色々やっているアルゴリズムなんですが、正直行って、次のよりシンプルな RWA に性能で負けてるので解説する価値がありません。誰も得しない。* よくあること。
The Joy of Forgetting: Faster Anytime Search via Restarting (Richter, Thayer, Ruml ICAPS 2010)
前回お話した トラップ のことを思い出してください。前回のトラップは「解が見つけられないような」トラップでしたが、今回のトラップは「$w$ を改善しても質の悪い解をみつけてしまうようなトラップ」です。前回と同じく迷路上の経路ですが、ワームホールがあります。
まずは、普通に一回目のイテレーション ($w=100$) で解を見つけられたとします。ここまではオッケーです。何の問題もありません。
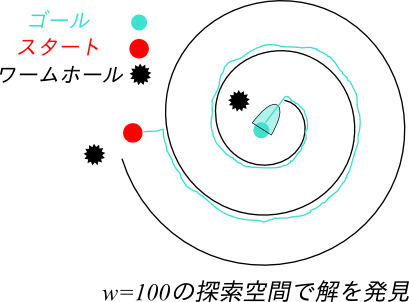
Anytime A* や ARA* は、ノードの計算などを二度以上行うのは計算時間を浪費すると考えたため、次のイテレーションに進む際、OPENリストを引き継ぎます。これは自然な判断に見えます。
しかしRWA論文は、この方式が Low-h bias と呼ばれる現象を引き起こすことを示します。たとえば、この探索状況からそのまま $w=1$ に移行することを考えてみましょう。 $W=1$ は最適Aと同じ探索条件です。ここで「素の」Aと「引き継ぎ」Aが違うのは、 OPENに含まれているノードの全ての隣接ノードが展開候補となる という点です。その結果、最適側に近づけた$w=1$ の設定を用いているにも関わらず、次の図のように、「非最適な経路の周辺が太くなる」ばかりで、ワームホールを通じた最短経路を発見できないという現象が発生します。

これが起こる原因は、非最適な経路の周辺がスタート地点よりも低い$h$を持っているからです。
さて、どうするか? シンプルに、忘れてしまいましょう!

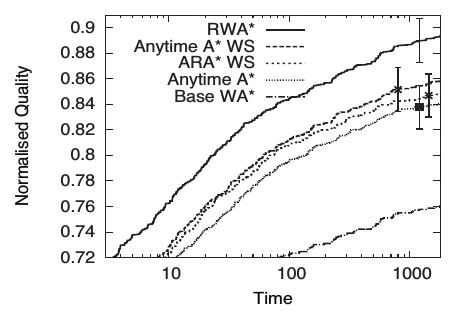
そんなんでうまく行くんかよって思うかもしれませんが、うまくいきます。下の図は、縦軸が正規化されたコストの質(最適解との比の逆数: 大きければ高性能), 横軸が経過時間です。実線のRWA*が他の様々な手法を完全に負かして、すばやく最適解に近づいていっていることがわかります。
問題設定は、International Planning Competition 2004 の問題 1096問。最適コストとの比は、問題全体の和同士で取っています。
まとめ
毎回$w$ を更新するWA*では、OPENリストは毎回捨てて独立に実行すべき、ということでした。