はじめに
今回はCVR (Conversion Rate) 予測の問題をマルチタスク学習で解く研究の論文をいくつか調べたのでまとめていきたいと思います。
CVR予測はユーザーが広告をクリックした後、商品の購入やフォームの入力などのコンバージョンが生じる確率 (Conversion Rate) を予測するというタスクです。
コンバージョンは商品の購入などが例であることから想像できるとおり、データが少なくなりやすい、クリックされていない広告はコンバージョンしないという系列的な依存関係がある、などのCVR予測特有の難しさがあります。
CVR予測に似たCTR (Click Through Rate) 予測 (クリックされる確率の予測) の手法をそのまま適用するだけでは上記の難しい点に対処しきれないため、さまざまな観点から予測精度の改善を試みた研究がなされています。
今回の記事では、コンバージョン以外のラベル (クリックなど) を活用するマルチタスク学習をCVR予測に適用することで、コンバージョンのデータの少なさを補いつつ系列的な依存関係をうまく扱うことを狙った論文を5つ紹介します。
全体の構成は、発表された時系列順になっています。
一番目のEntire Space Multi-Task Model (ESMM) をまず紹介し、そこから派生したESM^2, AITM , HM^3を紹介します。
途中に、この系列とは少し異なりますが、Multi Task field-weighted Factorization Machine (MTFwFM)という複数種類のコンバージョンを予測するためにマルチタスク学習を用いる研究を挟んでいます。
それでは見ていきましょう。
Entire Space Multi-Task Model (ESMM) [Ma+, 2018]
今回紹介する論文の基礎になる論文です。これ以降の研究はこの研究から派生したものなので、時間のない方はまずこの論文だけ抑えていただけると良いかと思います。
基本となるので、この論文は詳しく紹介し、他の論文はその差分を紹介していく形となっています。
こちらの論文では、CVR予測タスクにおける課題を2つ挙げています。
- Sample Selection Bias (SSB)
- Data Sparsity (DS)
これらの問題に対処するため、コンバージョンだけでなくクリックの情報を使ったマルチタスク学習を応用したEntire Space Multi-Task Model (ESMM)を提案しています。
以下ではそれぞれについて簡単に説明します。
詳しく知りたい方はこちらの記事も参考にしていただければと思います。
Sample Selection Bias
従来のCVR予測モデルを学習する際、clickされたデータを用いて学習を行う必要がある一方で、推論時はclickされる前の全てのimpressionに対して予測を行う必要があり、学習時と推論時で対象とするデータの集団が異なるバイアスが存在しました。
この論文のタイトルにもある"Entire Space"は推論する対象と同じ全体の空間を学習に用いるようにする、という意味が込められています。
論文中の図を引用すると、
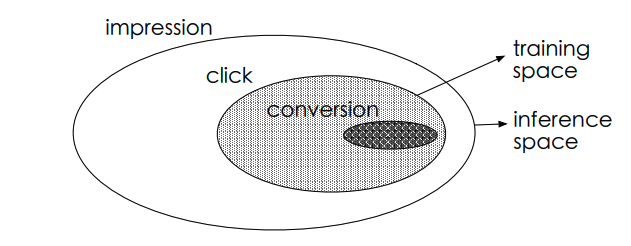
この外側のinference spaceと内側のtraining spaceがずれていることがSSBの指摘しているバイアスです。
Data Sparsity
CVR予測のタスクでは、CTR (Click Through Rate)予測のタスクと比較して、学習に用いることのできるデータの量が一般的に少ないという問題があります。
従来の手法ではクリックされたデータのみに学習データを限定するため、上で述べたSSBの問題が生じてしまうことに加え、クリックはかなり少ないことから学習データが少なくなってしまうという問題があります。
さらにクリックされたデータと比較して、コンバージョンの生じることはより稀であるため、正例の少ないデータになってしまうことが多いという問題もあります。DSはこの問題を指しています。
Entire Space Multi-Task Model (ESMM)
提案されたESMMは、大きく2つのニューラルネットのモジュールからなっており、それぞれCTRとCVRを予測するモジュールとなっています。これらのモジュールはembedding layerを共有しています。
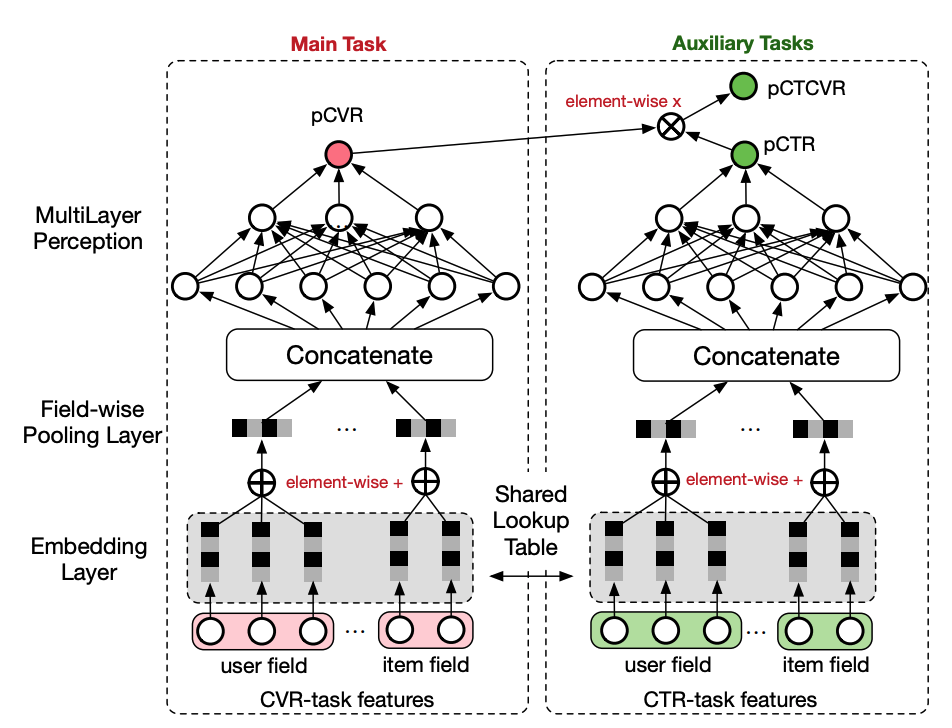
CTRとCVRを出力したのち、CTRとCVRの積をとりCTCVR (Click Through Conversion Rate)に相当する値を計算します。CTCVRはCVRと異なり、CVRはクリックされたという条件のもとでコンバージョンされる確率を指しますが、一方でCTCVRは広告が表示されたという条件のもとでコンバージョンされる確率を意味しています。
これらのモジュールによっての出力として得られたCTRとCTCVRをそれぞれ予測値とするLoglossを計算し、その和を全体の損失関数としています。
L(\theta_{cvr}, \theta_{ctr}) = \sum_{i=1}^N l(y_i, f(x_i, \theta_{ctr}))+ \sum_{i=1}^N l(y_i\&z_i, f(x_i, \theta_{ctr})\times f(x_i, \theta_{cvr}))
CVR自体を損失関数にしてしまうと、クリックされたデータのみを対象にしてしまい訓練時と推論時で対象がずれてしまう(SSBが生じる)ため、CTRと掛けてCTCVRを計算することで全impressionを対象に訓練することができています。
このため、モデル全体としてはCTRとCTCVRを予測しているような形となり、CVRは過程で得られる副産物のようなイメージですね。
SSBへの対処は上記の通りで、加えてembedding layerをCTRモジュールとCVRモジュールで共有することでDSの問題にも対処している、という構造になっています。
Multi Task field-weighted Factorization Machine (MTFwFM) [Pan+, 2019]
先ほどの研究ではCVR予測をCTR予測と組み合わせるというタイプのマルチタスク学習の適用方法でした。
この論文は、複数種類のコンバージョンの種類がある場合に、それらをマルチタスク学習で解こうという研究について書かれています。
複数種類のコンバージョンの例として、以下のようなものが論文中で挙げられています。
- lead (フォーム回答)
- view contents (ランディングページや商品ページの閲覧)
- purchase
- sign up
複数種類のコンバージョンについてそれぞれコンバージョンする確率を予測することを考えたとき、
コンバージョンの種類によって予測に効いてくる特徴量の組が異なる、ということをモデルに組み込みたいものの、
考えられる以下の2つの手法はそれぞれに問題点を抱えています。
- コンバージョンの種類ごとにモデルを分ける -> メモリの問題、他のコンバージョン情報を活かせない
- 特徴量にコンバージョンの種類を入れる -> 2wayだと表現力不足、3wayだと計算が重すぎる
このため、この論文ではField weighted Factorization Machines (FwFM)というCTR予測モデルをベースに、マルチタスク学習を適用したMulti Task field-weighted Factorization Machine (MTFwFM)を提案しています。
ベースとなっているFwFMについてはこちらの記事を参考にしてみてください。
FwFMのbias項とfieldのベクトルとfield間の交互作用の重みはタスク(コンバージョンの種類)ごとに異なるものを用意し、featureのembeddingはタスク間で共有しています。(細かいですが、FwFMの線形部分はFwFMの論文中でいうFwFM_FiLVを使っています。)
モデルの全体図で見ると、出力に近い部分がタスクごとに分かれていて(添え字に$t$がついている)、最初の方の層であるembeddingは重みを共有していることがわかります。
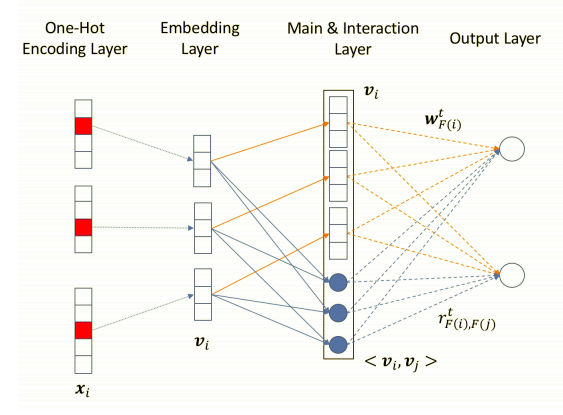
3重のFwFMだとComputing latencyがMT-FwFMの2.5倍で重いので使えない、2重のFwFM(conversion typeをfieldとする)は計算量的には問題ないので実験で比較し、提案手法のMT-FwFMの方が精度が良いことを確認しています。
Elaborated Entire Space Supervised Multi-task Model (ESM^2) [Wen+, 2020]
ここからまた本筋に戻り、1つ目に紹介したESMMを改良したESM^2を紹介します。
ESMMでは
impression-> click -> conversion
というグラフを想定してCTRとCVRを出力し、CVRと1つ前のstepの出力であるCTRを掛けてCTCVRを出力し、損失関数に与えていました。
ESM^2では、clickとconversionの間に起こるユーザーの行動を二種類に分割し、新たに作ったグラフに倣って条件付き確率の積を計算し、全impressionを対象にするように学習します。
具体的には、以下の図のようにDAction(商品をカートに入れる、ウィッシュリストに入れるなど)とOAction (Other action)に分け、それぞれのエッジに対応する条件付き確率を各モジュールが計算し、連鎖的に条件付き確率の積を取ったものを損失関数に入れます。
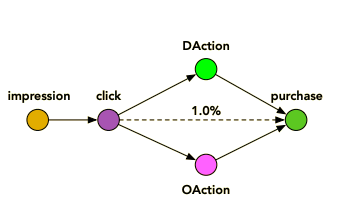
ESMMでCTRとCVRの積をとって損失関数にいれるというアイデアが出たのはCTCVRという概念があったことが大きいと思いますが、一般に条件付き確率の積で分母がimpressionの(end-to-endの、という表現がよく出てきたりします)確率を計算できるので、グラフを作れば同じような構成が考えられるというのが面白いと思います。
余談ですが、ESM^2という名前は最初どういう意味なのかよくわからなかったのですが、
Elaborated Entire Space Supervised Multi-task Model → EESSMM → $ESM^2$
という省略なのですね。英語ではよくある記法なのでしょうか?
Adaptive Information Transfer Multi-task (AITM) [Xi+, 2020]
こちらの研究では、ESMMやESM^2で1つ前のstepのラベル(コンバージョンからみたクリックなど)の情報が、予測値というスカラーでしか渡ってこないという問題があると指摘して、出力層に近いベクトル表現を次のステップに渡すような構成のモデルであるAdaptive Information Transfer Multi-task (AITM)を提案しています。
左がESMMやESM^2の構成、右側が今回提案されているAITMを含んだモデルの図になっています。
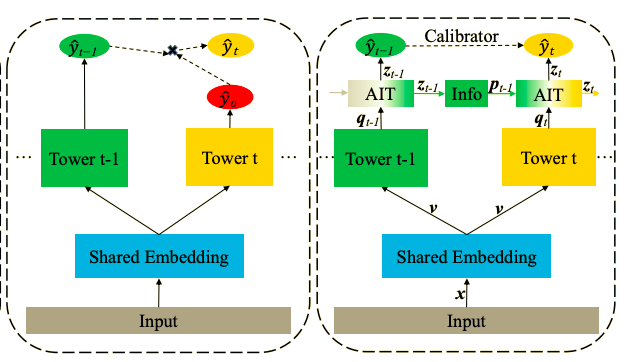
またこちらはend-to-endの予測を行うため、予測が1つ前のステップの確率より小さくなっていることを他の方法で担保する必要があるということで、Behavioral expectation calibratorという正則化項を提案しています。
Hierarchically Modeling both Micro and Macro behaviors (HM^3) [Wen+, 2021]
ESMM, ESM^2とグラフの構造を変えてその都度条件付き確率の積をとって損失関数に入れてきましたが、最後に紹介するこの論文も同じくグラフの構成を変えています。
この論文ではESM^2で提案されていたDActionとOActionをそれぞれmicro, macroという観点で分割したグラフに対してESMM,ESM^2と同様の操作をしています。
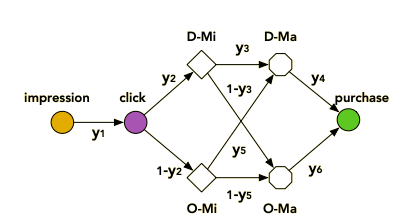
userのitemに対する行動をMacro behaviors、その中でもpurchaseに関連するMicro behavior(例えばアイテムの詳細ページの特定の部分へのuserの行動)とし、二種類を階層的に扱うモデルとのことです。
分解というよりは、ESM^2のDAction, OActionがMacro behaviorsに対応していて、Microが挿入されたという方が近い印象です。
(個人的に、このへんのグラフをちょっといじって同じことやっている論文って新規性という点でどうなんでしょう...?と思ってしまいました)
おわりに
今回はCVR (Conversion Rate) 予測の問題をマルチタスク学習で解く研究の論文を、Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
を中心に見てきました。
CTRとCVRに限らず、系列的な依存関係にあるようなデータ生成のロジックが背後にある場合に、条件付き確率の積でend-to-endの確率を出して損失関数に入れる、というアイデアは他にも使えるのではないかなと感じました。
参考にしていただければ嬉しいです。最後まで読んでいただきありがとうございました。
参考文献
- [Ma+, 2018] Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate SIGIR, 2018.
- [Pan+, 2019] Predicting Different Types of Conversions with Multi-Task Learning in Online Advertising KDD, 2019.
- [Wen+, 2020] Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction SIGIR, 2020.
- [Xi+, 2020] Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising KDD, 2021.
- [Wen+, 2021] Hierarchically Modeling Micro and Macro Behaviors via Multi-Task Learning for Conversion Rate Prediction SIGIR, 2021.