はじめに
Click Through Rate (CTR)の予測タスクにDeep Learningが用いられるようになって久しいです。
例えばこちらの記事を見てみると、2018年ごろにはDeep LearningとFactorization Machinesを組み合わせた研究が盛んだった事がわかります。
Deep LearningでCTR予測問題を解くという研究の流れが発展し、多くのモデルが提案されるに伴い、それらのモデルを実装したDeepCTRというライブラリの対応するモデルもどんどん増えていき、とても充実してきています。
DeepCTRとは、Weichen Shen氏により開発されたPythonライブラリで、深層学習を用いた各種CTRモデルを簡単に利用できるように実装されています。
対象ライブラリはtf 1.x/tf 2.xとなっていますが、PyTorch版(DeepCTR-Torch)も存在し、利用しやすいのではと思います。
対応しているモデルは2021年8月時点で20個を超えており、とても充実している事がわかります。
統一的なインターフェースでこれらのモデルが利用できるのは嬉しいですね。
今回の記事は、このDeepCTRに実装されているモデルのうち主要なモデルの解説、及び他の解説記事へのリンク集となっています。
対応しているモデル全てを解説するのは長くなってしまうため、著名な会議に通った論文を中心に扱っています。
既に日本語で書かれた解説記事があるモデルに関してはそのリンクを記載し、それらの記事で扱われていない以下のモデルについては本記事の中で解説を行っています。
- AutoInt [CIKM 2019] AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
- FiBiNET [RecSys 2019] FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
- FGCNN [WWW 2019] Feature Generation by Convolutional Neural Network for Click-Through Rate Prediction
- Deep Session Interest Network [IJCAI 2019] Deep Session Interest Network for Click-Through Rate Prediction
- IFM [IJCAI 2019] An Input-aware Factorization Machine for Sparse Prediction
- DIFM [IJCAI 2020] A Dual Input-aware Factorization Machine for CTR Prediction
今回の記事の構成上、解説するモデル間の繋がりはほとんどないため、どのモデルから読み始めても大丈夫です。
それでは見ていきましょう。
AutoInt [CIKM 2019]
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networksという論文で提案されたAutoIntについて紹介します。
AutoIntは、低次から高次までの交互作用をいい感じに自動で考慮した低次元表現を得る手法を考える、というモチベーションから提案されたモデルです。
具体的には、Multi-head Self Attentionを使ったアプローチがなされています。
なお、今回の記事ではTransformerで使われているこのMulti-head Self Attentionを用いた研究が多く登場するので、ご存知ない方は以下の解説記事などを参考にしていただければと思います。
では話を戻して、AutoIntの全体の構成はこちらです。
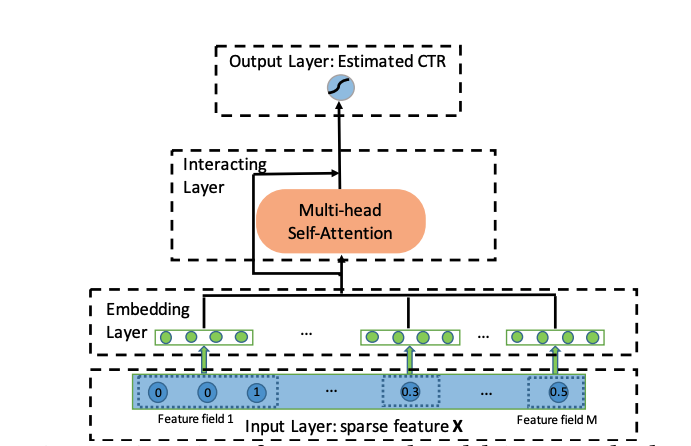
Embedding Layerでは、onehot化できるカテゴリ変数は普通に線形変換し、multi-hotな変数ははその分のベクトルを平均する、numericalなfeatureはその値をベクトルとかける、などの処理を施すことでどの種類の特徴量も同じ次元のベクトルに変換します。
Interacting Layerでは、これらをベクトルの系列としてMulti-head Self Attentionをかけます。
この層を重ねていくほど高次の交互作用が計算されていくわけですが、低次な交互作用も予測に用いたいため、Residualな構成を入れています。
図中のInteracting LayerにあるSkip Connectionの矢印がそれを表しています。
具体的には、Interacting Layerでは入力を線形変換したものと、Multi-head Self Attentionの出力をconcatしたものを足してReluに通して最終的な出力としています。
Output Layerでは全部くっつけて全結合層に入れて予測を行います。
FiBiNET [RecSys 2019]
FiBiNETは以下の2点を考慮して提案されたCTR予測モデルです。
- Squeeze-and-Excitation Network (SENet) によって特徴量の重要度を動的に学習
- 特徴量の交互作用を双線形関数で効率的に学習
前者は、各特徴量の重要度はタスクによって異なるから、動的にどの特徴量に注目すべきかを学習しようというものです。
後者は、特徴量の交互作用を計算する際に、単純にアダマール積や内積を取るのではなく、双線形関数を使って計算しよう、という主張です。
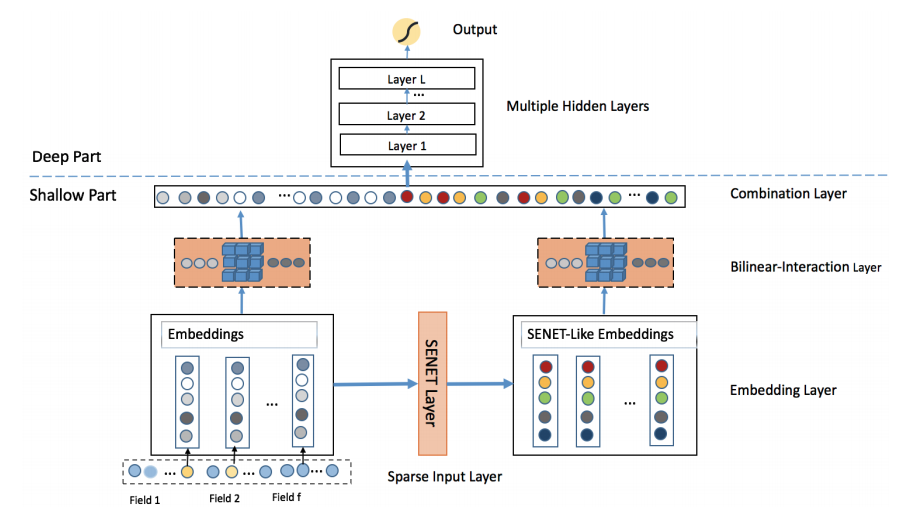
SENetは画像分野で提案された技術で、Attentionのように重要視する箇所に大きな重みを与え、重要でない部分を0に潰すような機構となっています。これをCTR予測に効く特徴量を見つける部分に使用する、という形です。
SENetについてはこちらも参考にしてみてください。
【論文紹介】Squeeze-and-Excitation Networks(CVPR 2018)
後者の、ベクトル同士から特徴量の交互作用を計算する部分に使うBiLinear Layerでは、間に行列を持ってきてアダマール積と内積を組み合わせてベクトルを作っています。
図の左がアダマール積と内積、右側が今回提案しているBiLinearの演算です。
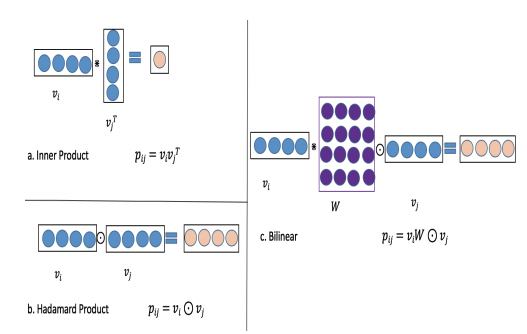
間に持ってくる行列$W$を全部で共通にするか、fieldごとに別にするか、fieldの組み合わせごとに別にするかの三種類の方法を試しています。
モデルの全体図を見てみると分かる通り、BiLinear Layerの入力は元のembeddingだけでなく、元のembeddingをSEnetに通して得られる出力もBiLinear Layerに入力する構成になっています。
それぞれBiLinear Layerを通した後は出力のベクトルをconcatして全結合層に入れて最終的な出力を得る、といった構成です。
論文を読んでいて少し気になったのですが、実験の部分でアダマール積と提案しているBiLinear Layerを比較しているのですが、結果を見てみると両者でそんな差がなく、一貫してBiLinearの方が良いという結果にもなっておらず、提案した手法の良さを主張できる結果になっていないように見えました。
一応BiLinear layer自体を完全に取り除くと性能が落ちるので必要ではあると思うのですが、アダマール積より有効であることは主張できない、と言った結論でした。
またBiLinear Layerの間に持ってくる行列$W$をどの単位で分けるかによる亜種の比較も行なっていましたが、データセットによってどれが良いかは異なり、一概にどれが良いという主張はできないという結論でした。
FGCNN [WWW 2019]
後ほどリンク集でも出てくるWide&Deepでは、特徴量エンジニアリングできるWide partとimplicitに高次の交互作用を考慮できるDeep Partを組み合わせているのですが、この特徴量エンジニアリング部分も自動で行ってくれるモジュールであるFeature Generationを提案している研究になります。
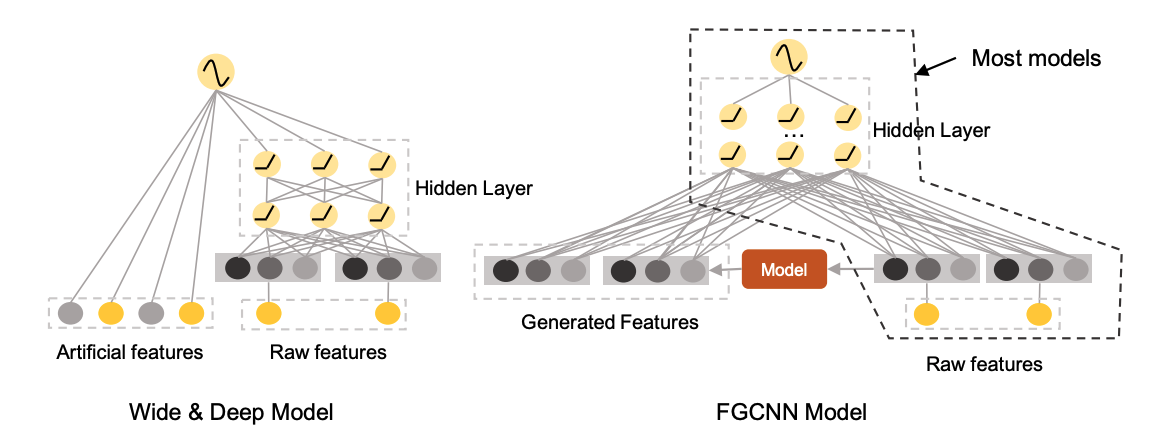
上の図で言うと右のモデルの真ん中のModelの部分が、元の特徴量から特徴量エンジニアリング部分を行うモジュールに相当します。
具体的にはCNNとMLPを組み合わせることで、localとglobalの交互作用をそれぞれ抽出してsparseで精度に効く特徴量を自動で作り出す、という構成になっています。
単純にMLPのみやCNNのみを使わない理由としては、
- 生成される特徴量がスパースになって欲しい
- CNNだけだと位置が遠い特徴同士の交互作用が考慮できない
の2点が挙げられていました。
Deep Session Interest Network [IJCAI 2019]
こちらの研究では、ユーザーの行動系列を入力にCTR予測をする問題に取り組んでいます。
行動系列を扱うモデルということで、後ほどリンク集で紹介するDeep Interest Network (DIN)やDeep Interest Evolution Network (DIEN)などの研究に近いです。
このDeep Session Interest Networkでは、ユーザーの行動系列をsessionに分けて考えます。
sessionの定義は、行動の間隔が30分以上であれば新しいsession、という単位で分けた行動の系列としています。
この研究では、同じsessionに属する行動は同じようなカテゴリのitemをみているが、sessionが異なると対象のitemのカテゴリが全く異なるという観察が元になっています。
(例えばECサイトだと、あるときは服を見ている、あるときは本を見ている、というような状況のことだと思います。確かに各sessionごとに行動の目的が違うことが多いので、想像しやすいでしょう。)
この観察からうまくsessionの構造を扱えるようなモデルであるDeep Session Interest Networkを提案しています。
具体的には、
- session内はMulti-head Self Attention
- session間はBiLSTM
- どこを重視して予測するかをtarget itemごとに変えるactivation unit
といったcomponentからなります。
IFM [IJCAI 2019]
IFMはInput-aware Factorization Machinesの略です。
実は同じIFMにInteraction-aware Factorization Machinesというモデルもあるのですが、こちらはDeepCTRには実装されていません。
注意しましょう。
今回紹介するInput-awareの方のIFMでは、同じ特徴量でもinstanceによって予測に効いてくるかどうかの影響の大きさが異なる、という問題に着目した研究です。
例として、CTR予測を考えたとき、(user,item)の特徴量が
{young, female, student, pink, skirt}
と
{young, female, student, blue, notebook}
だと、femaleという特徴は1つ目のinstanceではピンクのスカートをクリックするかという予測にとっては重要だけど、二つ目のinstanceでは女性であることはそんなに重要ではない(予測には効いてこない)、という構造を考慮したモデルを作りたい、というモチベーションです。
IFMでは、Factorization Machinesのembeddingをinstanceごとに変えよう、という方針で対応しようとしています。
通常のFMではどのinstanceでも同じ特徴量は同じembeddingになりますが、IFMはここをinputごとに変更する(input-aware)という改良を行います。
(通常のFMも、embeddingの内積をとっているところでimplicitには考慮しているのだろうけど、そこを明示的にembedding自体を変えて考慮するということでしょうか。Field-aware FMにもモチベとしては近い気がします。)
IFMの全体図はこちらです。
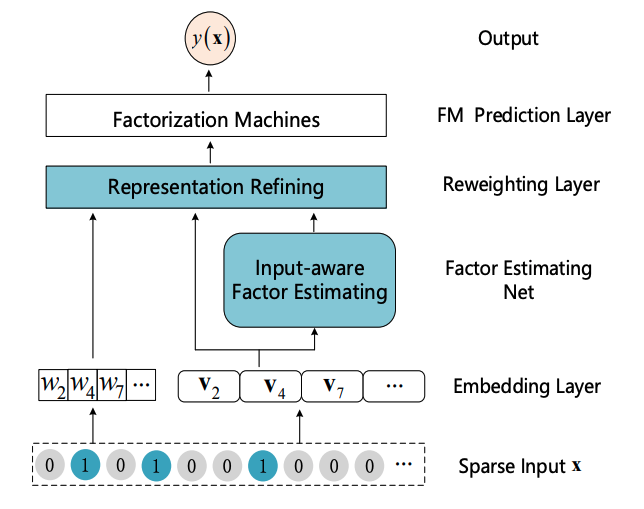
図中のInput-aware Factor Estimatingで入力$\boldsymbol{x}$をMLPに入れて最後Softmaxを通して出てきたベクトル$\boldsymbol{m}_{\boldsymbol{x}}$の各成分を、Representation Refiningで線形項の重み$w_i$とembedding $\boldsymbol{v}_i$に掛け算するという構成です。($i$は特徴量のindex)
w_{\boldsymbol{x},i} = m_{\boldsymbol{x},i}w_i \\
\boldsymbol{v}_{\boldsymbol{x},i} = m_{\boldsymbol{x},i}\boldsymbol{v}_i
最初、自分はこの論文を読んでいて、inputに応じて線形項の重み$w_i$とembedding $\boldsymbol{v}_i$を変えると聞いて、もっとガラッとembedding自体が変わるようなアーキテクチャなのかと思ったのですが、この通り定数倍するだけにとどめています。Input-aware Factor Estimatingの部分はAttention機構のようにも見えます。入力のうちどこに着目するかをinputによって計算している、といった解釈です。
DIFM [IJCAI 2020]
こちらのDIFM (Dual Input-aware Factorization Machines)はIFMの改良版です。
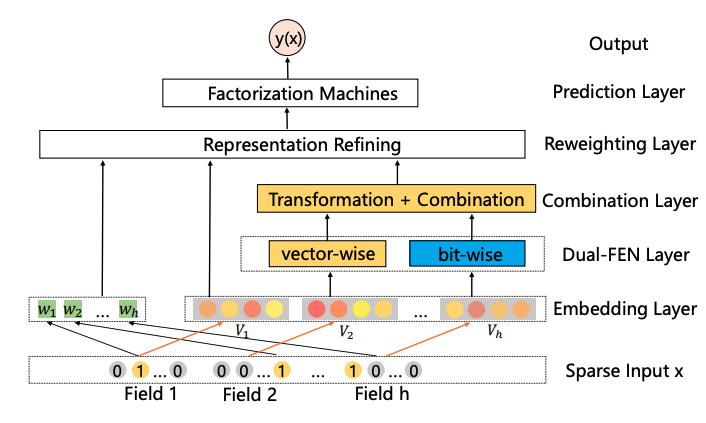
Dualという名称のとおり、IFMでMLPで計算していた、線形項の重みやembeddingに掛け算していた値の計算をbit-wiseとvector-wiseの二種類の方法を組み合わせて計算しようという研究です。
bit-wiseの方はIFMと同じくMLPに入力する方法で、vector-wiseはTransformerに影響を受けてMulti-head Self Attentionを使って計算します。
IFMの時にembedding自体がガラっと変わるわけではなく定数倍なのか...と思ったので、アップグレードされたこちらの研究は違うのかなと思って読み進めたのですが、こちらも最終的には特徴量ごとにスカラー値を計算し、embeddingや線形項の重みに掛け算していました。
その他モデルの解説リンク集
ここからはその他のモデルの解説記事のリンクをまとめています。
ポインタのように使用していただければと思います。
先ほども紹介したFactorization MachinesとDeep Learningを組み合わせた研究についての記事です。
DeepCTRに実装されているモデルのうち、以下のモデルが紹介されています。
- Factorization-supported Neural Network [ECIR 2016] Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction
- Product-based Neural Network [ICDM 2016] Product-based neural networks for user response prediction
- Deep & Cross Network [ADKDD 2017] Deep & Cross Network for Ad Click Predictions
- Wide & Deep [DLRS 2016] Wide & Deep Learning for Recommender Systems
- DeepFM [IJCAI 2017] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- xDeepFM [KDD 2018] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
手前味噌ですが、こちらはFieldという概念に着目してFactorization Machinesを改良する研究のまとめ記事です。
以下のモデルが対応しています。
- FwFM [WWW 2018] Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising
- Attentional Factorization Machine [IJCAI 2017] Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
上記の2本のまとめ記事で網羅しきれていないモデルについては、次の記事を参考にすると良いかと思います。
- 【論文紹介】Neural Factorization Machines for Sparse Predictive Analytics
- 【論文紹介】Deep Interest Network for Click-Through Rate Prediction - sola
- 【論文紹介】Deep Interest Evolution Network for Click-Through Rate Prediction (AAAI2019)
また、DeepCTRと直接関係はないものの、Factorization Machines関連で詳しくまとまった記事があるのでこちらも紹介しておきます。
おわりに
数年前からFactorization Machines関連の論文をよく調査していることもあり、それらの論文で提案されているモデルの実装がたくさんあるDeepCTRについて、対応するモデルの解説資料をまとめた決定版のような記事があったら便利かも、と思い本記事を執筆しました。
ここを見ればDeepCTRで実装されているモデルの解説はどれでもたどり着ける!的な立ち位置のものを目指して作ったので、学習のポインタとして使ったり、辞書的に使ったりといろいろ活用していただければと思います。
他にも関連する解説記事で抜け漏れがありましたらコメントいただけると嬉しいです。
長くなってしまいましたが、最後までお読みいただきありがとうございました!