はじめに
Pythonや機械学習の勉強を始めて3か月がたち、力試しではじめてKaggleのコンペティションに参加しました。機械学習に興味はあるけど何から始めればよいかわからない方、Kaggleにこれから挑戦しようと思っている方の参考になれば幸いです。
挑戦した課題
内容
アメリカの高等教育を受ける学生のコース、年齢、親の学歴などの特徴量から、その学生が最終的に卒業できるか否か(academic risk assessment)を判定する。
欠損値がなく、カテゴリの意味を説明したドキュメントが用意されているなど初心者向きであると思い挑戦。
実行環境
- プロセッサ:12th Gen Intel(R) Core(TM) i5-1240P
- 開発環境:Google Colaboratory
- 言語:Python
- 使用したライブラリ:Pandas, Numpy, Matplotlib, scikit-learn, PyCaret
分析するデータ
- データ数 : trainデータ → 76518, testデータ → 51012
- 特徴量の数 : 36 (カテゴリ変数 → 28 , 数値型変数 → 8 )
- 詳しくは特徴量に関するドキュメントを参照してください
- 欠損値:なし
分析のながれ
- データの確認
- データの前処理
- 特徴量エンジニアリング
- 使用するモデルの選定
- 予測
1. データの確認
実行したコード
kaggle_academic.ipynb
# 必要なモジュールのインストール
!pip install pycaret[full]
# 必要なモジュールのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from pycaret.classification import *
kaggle_academic.ipynb
# データの読み込み
train = pd.read_csv('/content/train.csv')
test = pd.read_csv('/content/test.csv')
# 学習データの最初の5行を表示
train.head(5)
# 学習データの最初の5行を表示
test.head(5)
- 出力の一部を表示
kaggle_academic.ipynb
# Id列削除前の型を確認
print("The train data size before dropping Id feature is : {} ".format(train.shape))
print("The test data size before dropping Id feature is : {} ".format(test.shape))
# Idだけ別に保持する
train_ID = train['id']
test_ID = test['id']
# 予測に不要なのでId列を削除する
train.drop("id", axis = 1, inplace = True)
test.drop("id", axis = 1, inplace = True)
# Id列削除後の型を確認
print("\nThe train data size after dropping Id feature is : {} ".format(train.shape))
print("The test data size after dropping Id feature is : {} ".format(test.shape))
- 学習に不要なId列が削除されていることを確認
2. データの前処理
実行したコード
kaggle_academic.ipynb
# 連結データを作成
ntrain = train.shape[0]
ntest = test.shape[0]
y_train = train.Target.values
all_data = pd.concat((train, test)).reset_index(drop=True)
print("all_data size is : {}".format(all_data.shape))
- 後で扱いやすくするためにtrainとtestを結合する
kaggle_academic.ipynb
# 欠損値の確認
missing_data = all_data.isnull().sum()
print(missing_data)
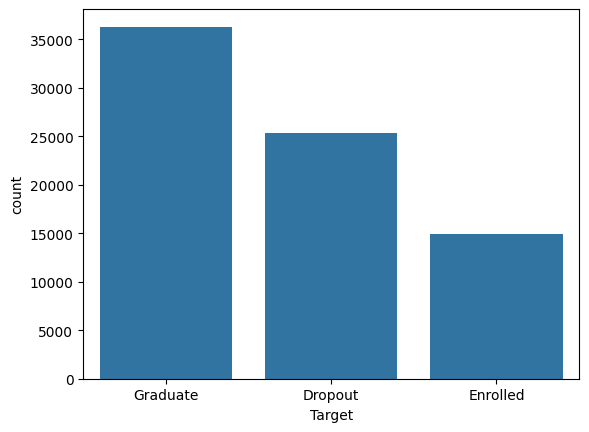
# ターゲット変数のばらつきをチェック
import matplotlib.pyplot as plt
sns.countplot(x='Target', data=train)
plt.show()
- 欠損値がtrain, testともにないことを確認
- 3つのターゲット変数で極端な偏りはない
kaggle_academic.ipynb
# 説明変数のチェックと前処理
## Application mode (データ数の少ないカテゴリをまとめる)
application_mode_values = [1, 7, 17, 18, 39, 43, 44]
all_data['Application mode'] = all_data['Application mode'].apply(lambda x: 0 if x not in application_mode_values else x)
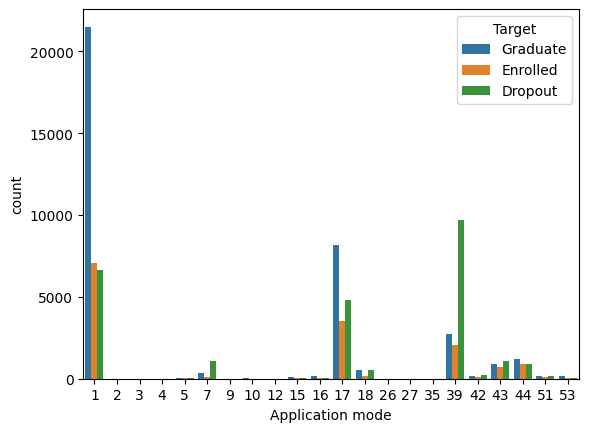
- データ数の少ないカテゴリはターゲット変数のばらつきもみながら1つにまとめる
kaggle_academic.ipynb
## Previous qualification (データ数の少ないカテゴリをまとめる)
all_data['Previous qualification'] = all_data['Previous qualification'].apply(lambda x: 0 if x not in [1, 39] else x)
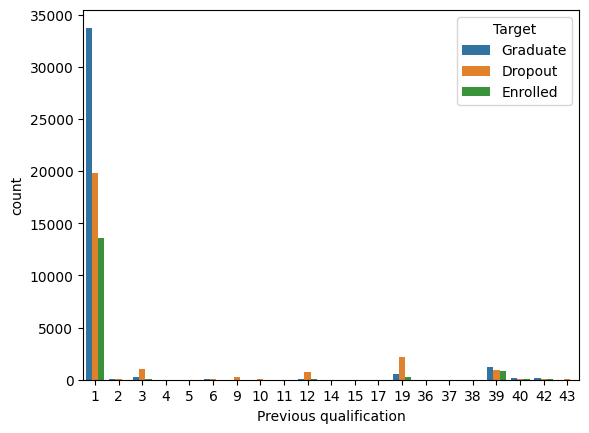
- 1, 39以外のカテゴリはDropoutが多いのでまとめる
kaggle_academic.ipynb
## Nacinality (ほとんどがカテゴリ1のため、1かそれ以外かで分類)
all_data['Nacionality'] = all_data['Nacionality'].apply(lambda x: 0 if x != 1 else x)
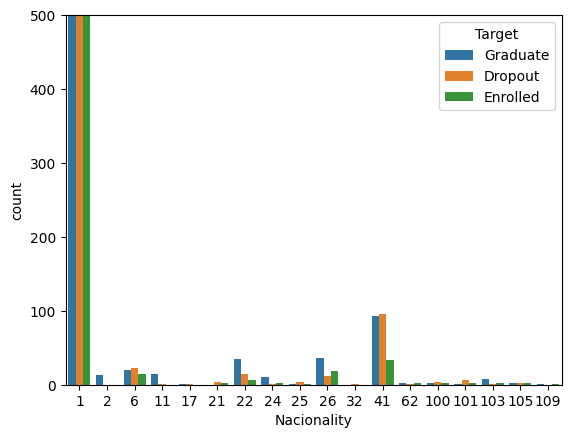
- カテゴリが1のものがとても多い、1かそれ以外かでまとめる
kaggle_academic.ipynb
## Mother's qualification (データ数の少ないカテゴリをまとめる)
## Father's qualificationも同様
valid_values = [1, 3, 19, 34, 37, 38]
all_data["Mother's qualification"] = all_data["Mother's qualification"].apply(lambda x: 0 if x not in valid_values else x)
all_data["Father's qualification"] = all_data["Father's qualification"].apply(lambda x: 0 if x not in valid_values else x)

- こちらも一部を除いてデータ数が非常に少ないのでそれらをまとめる
kaggle_academic.ipynb
## Mother's occupation (データ数の少ないカテゴリをまとめる)
## Father's occupationも同様
valid_values = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 90]
all_data["Mother's occupation"] = all_data["Mother's occupation"].apply(lambda x: 100 if x not in valid_values else x)
all_data["Father's occupation"] = all_data["Father's occupation"].apply(lambda x: 100 if x not in valid_values else x)
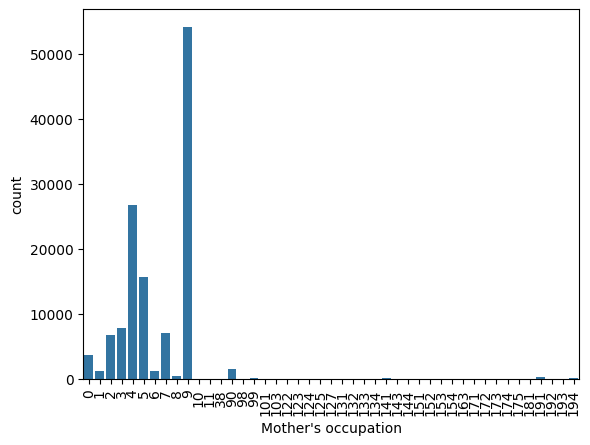
- 上記(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 90)以外はデータ数少、ターゲット変数のばらつきもみて1つにまとめる
kaggle_academic.ipynb
## Educational special needs (バイナリ, ほぼ0でターゲット変数の分布も0と1で大きく変わらない→削除)
all_data = all_data.drop('Educational special needs', axis=1)
## Curricular units 1st sem (credited) (ほとんどがカテゴリ0→削除)
all_data = all_data.drop('Curricular units 1st sem (credited)', axis=1)
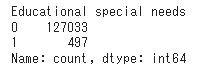
- 上記のように偏りがおおきいカテゴリのため削除
kaggle_academic.ipynb
## Curricular units 1st sem (enrolled) (データ数の少ないカテゴリをまとめる)
valid_values = [0, 5, 6, 7, 8]
all_data["Curricular units 1st sem (enrolled)"] = all_data["Curricular units 1st sem (enrolled)"].apply(lambda x: 100 if x not in valid_values else x)
## Curricular units 1st sem (evaluations) (データの分布を確認, 傾向から3つのカテゴリに分ける)
all_data["Curricular units 1st sem (evaluations)"] = all_data["Curricular units 1st sem (evaluations)"].apply(lambda x: 0 if x >= 0 and x <= 5 else (1 if x >= 6 and x <= 8 else 2))
## Curricular units 1st sem (approved) (データ数の少ないカテゴリをまとめる)
all_data["Curricular units 1st sem (approved)"] = all_data["Curricular units 1st sem (approved)"].apply(lambda x: 10 if x >= 9 else x)
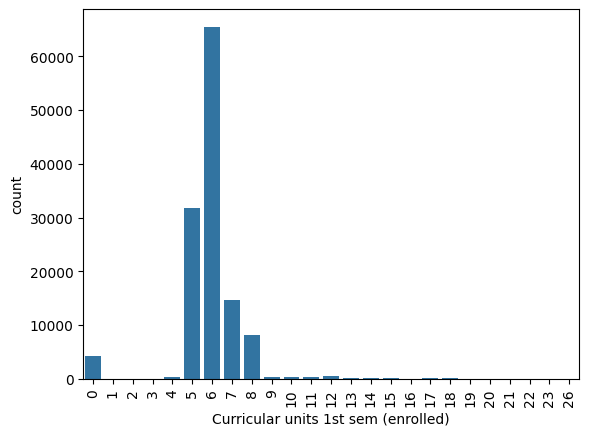
- 前出のカテゴリと同様にデータ数とターゲット変数のばらつきをみてまとめる
kaggle_academic.ipynb
## Curricular units 1st sem (without evaluations) (ほとんどがカテゴリ0→削除)
all_data = all_data.drop('Curricular units 1st sem (without evaluations)', axis=1)
- 2nd semに関する特徴量も同様に処理
kaggle_academic.ipynb
# データの再分割
train = all_data[:ntrain]
test = all_data[ntrain:]
- 前処理後のデータを再びtrain, testに分ける
3. 特徴量エンジニアリング
実行したコード
kaggle_academic.ipynb
# ターゲットエンコーディングを行う
# カテゴリ変数のリストを作成
clms = ["Marital status", "Application mode", "Application order", "Course", "Daytime/evening attendance",
"Previous qualification", "Nacionality", "Mother's qualification", "Father's qualification",
"Mother's occupation", "Father's occupation", "Displaced", "Debtor", "Tuition fees up to date",
"Gender", "Scholarship holder", "International", "Curricular units 1st sem (enrolled)",
"Curricular units 1st sem (evaluations)", "Curricular units 1st sem (approved)",
"Curricular units 2nd sem (enrolled)", "Curricular units 2nd sem (evaluations)",
"Curricular units 2nd sem (approved)"]
kaggle_academic.ipynb
# 目的変数のDropout, Enrolled, Graduateの3クラスを0, 1, 2とラベルを与えたTarget_labeledを作成する
train['Target_labeled'] = train["Target"].apply(lambda x: 0 if x == "Dropout" else (1 if x == "Enrolled" else 2))
# ホールドアウト検証用の5分割の準備(リークを防ぐために分割して実施)
skf = StratifiedKFold(n_splits=5)
- ターゲットエンコーディングを行う際、自分自身のターゲット変数をエンコーディングに含まない(リークをしない)ためにホールドアウトを行う。
- 今回は5分割のK-Foldを利用してリークを防止
kaggle_academic.ipynb
# ターゲットエンコーディング用の関数
def target_encode(train, test, target, col):
target_mean = train.groupby(col)[target].mean()
test[col + '_enc'] = test[col].map(target_mean)
return test
# 各Foldに対してターゲットエンコーディングを行う(学習データ)
encoded_train = train.copy()
for col in clms:
encoded_train[col + '_enc'] = np.nan
for train_index, val_index in skf.split(train, train['Target_labeled']):
train_fold, val_fold = train.iloc[train_index], train.iloc[val_index]
for col in clms:
val_fold = target_encode(train_fold, val_fold, 'Target_labeled', col)
encoded_train.iloc[val_index, encoded_train.columns.get_loc(col + '_enc')] = val_fold[col + '_enc'].values
kaggle_academic.ipynb
# テストデータに対してターゲットエンコーディング
encoded_test = test.copy()
for col in clms:
encoded_test = target_encode(encoded_train, test, 'Target_labeled', col)
# encoded_train = target_encode(encoded_train, encoded_train, 'Target_labeled', col)
- testデータに対してはtrainデータすべてを用いてターゲットエンコーディングを行う
kaggle_academic.ipynb
# 欠損値の補完(全体の平均値で補完)
for col in clms:
mean_enc = encoded_train[col + '_enc'].mean()
encoded_train[col + '_enc'].fillna(mean_enc, inplace=True)
encoded_test[col + '_enc'].fillna(mean_enc, inplace=True)
- testデータにのみ含まれるカテゴリがあり、欠損値になってしまうので全体の平均値で補完
kaggle_academic.ipynb
# ターゲットエンコーディングを行ったもとのカラムを削除
encoded_train = encoded_train.drop(columns=clms)
encoded_test = encoded_test.drop(columns=clms)
# 学習データ・テストデータを作成
X = encoded_train.drop(columns=["Target"])
X_test = encoded_test.drop(columns=["Target"])
4. 使用するモデルの選定
実行したコード
kaggle_academic.ipynb
# PyCaretのセットアップ
clf1 = setup(data = X, target = "Target_labeled", session_id=123, use_gpu=True)
# モデルの比較
best_model = compare_models()
- 学習データにX, ターゲット変数としてターゲットエンコーディングした値を使用
- GPUを使用して計算(use_gpu=True)
- compare_models()でスコアの高いモデルを探す
kaggle_academic.ipynb
# 精度(Accuracyスコアの良かったモデルを作成)
cat_boost = create_model('catboost') # CatBoost
lgbm = create_model('lightgbm') # LightGBM
xgboost_model = create_model('xgboost') # XGBoost
# モデルのチューニング
tuned_cat_boost = tune_model(cat_boost, fold=5)
tuned_lgbm = tune_model(lgbm, fold=5)
tuned_xgboost_model = tune_model(xgboost_model, fold=5)
- スコアの高かった3つのモデルを採用(cat_boost, LightGBM, xgboost)
- さらにこの3つのモデルのハイパーパラメータを最適化(tune_model)
kaggle_academic.ipynb
# モデルのブレンド(重みを手動で設定)
blended_model = blend_models(estimator_list=[cat_boost, lgbm, xgboost_model], weights=[0.15, 0.7, 0.15])
- 最適化した3つのモデルをブレンドして最終的なモデルとする(重みは手動で決定)
kaggle_academic.ipynb
# ブレンドモデルの評価
evaluate_model(blended_model)
# モデルの保存(必要あれば)
# save_model(blended_model, 'blended_model')
5. 予測
実行したコード
kaggle_academic.ipynb
# 数値になっていたターゲット変数のラベルをもとに戻すための関数
def data_labeling(predicted_test_target):
pred_test_target = []
for i in range(len(predicted_test_target)):
if predicted_test_target[i] == 0:
pred_test_target.append("Dropout")
elif predicted_test_target[i] == 1:
pred_test_target.append("Enrolled")
else:
pred_test_target.append("Graduate")
return pred_test_target
- ターゲットエンコーディングのために数値としていたターゲット変数をもとのDropout, Enrolled, Graduateに戻す
kaggle_academic.ipynb
# テストデータに対して予測
predictions= predict_model(blended_model, data=X_test)
# 予測されたカテゴリを格納(PyCaretの仕様で予測された値は"prediction_label"にはいる)
predicted_test_target = predictions["prediction_label"].tolist()
# 予測値をカテゴリに直す
pred_test = data_labeling(predicted_test_target)
- ブレンドしたモデルを用いてtestデータに対して予測を実施
kaggle_academic.ipynb
# 提出
submission = pd.DataFrame({'id': test_ID, 'Target': pred_test})
submission.to_csv('submission.csv', index = False )
- 指定された提出の形式に直してから予測値をcsvで出力
結果
- Private Score : 0.83457
- 順位 : 1242 / 2691 位
考察
- ターゲットエンコーディングを行った特徴量のうちどれの寄与度が高いかを調べると以下のようになる(feature importanceの見方はこちらを参照)
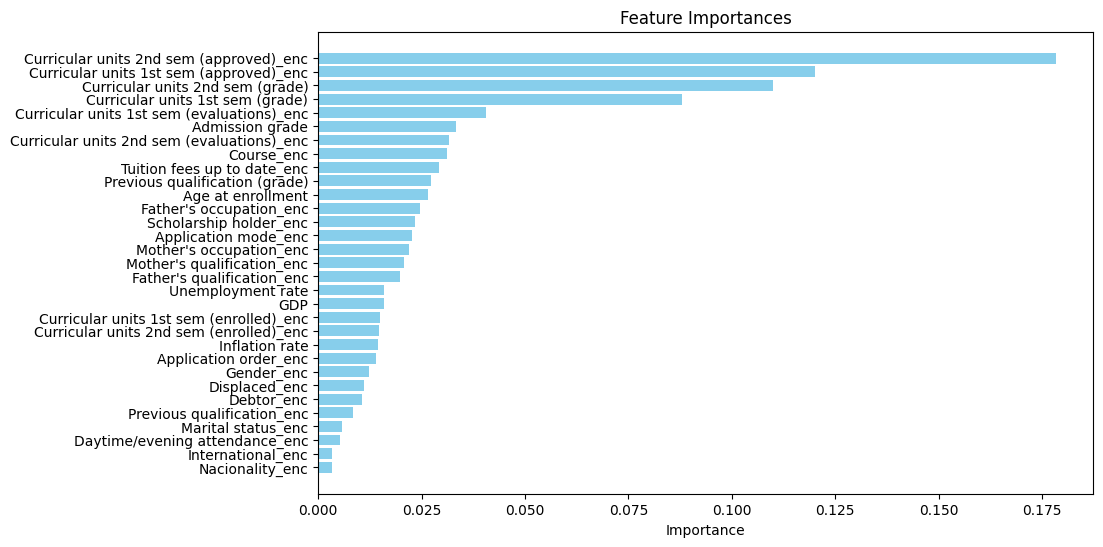
-
重要度の上位は「学生の成績平均点」や「学生の取得単位数」など卒業できるか否かに関係が深いと直感的にも思えるような特徴量となっていた
-
一方で親の職業や授業料支払いの有無など、家庭環境や経済面も卒業できるかどうかにかなり寄与していることが分かった
-
全体として本人の頑張り(成績)に加えて、いわゆる親ガチャのような要素も結果に影響しているという納得感のある関係を可視化できた、と感じた。
感想
はじめてコンペに参加し、なかなかスコアが上がらないもどかしさ、コンペ参加者のなかで頭一つ抜け出すことの難しさを感じました。特に王道の前処理を試してもスコアが必ず上がるわけではなく、むしろ下がったりするなど機械学習の難しさ、奥深さを感じられました。
しかし、この課題を通じて使ったことのなかったモデルや前処理の方法などたくさん試すことができ、よい経験になったと思います。これからもたくさん頭を悩ませながら頑張っていきたいと思いました。