はじめに
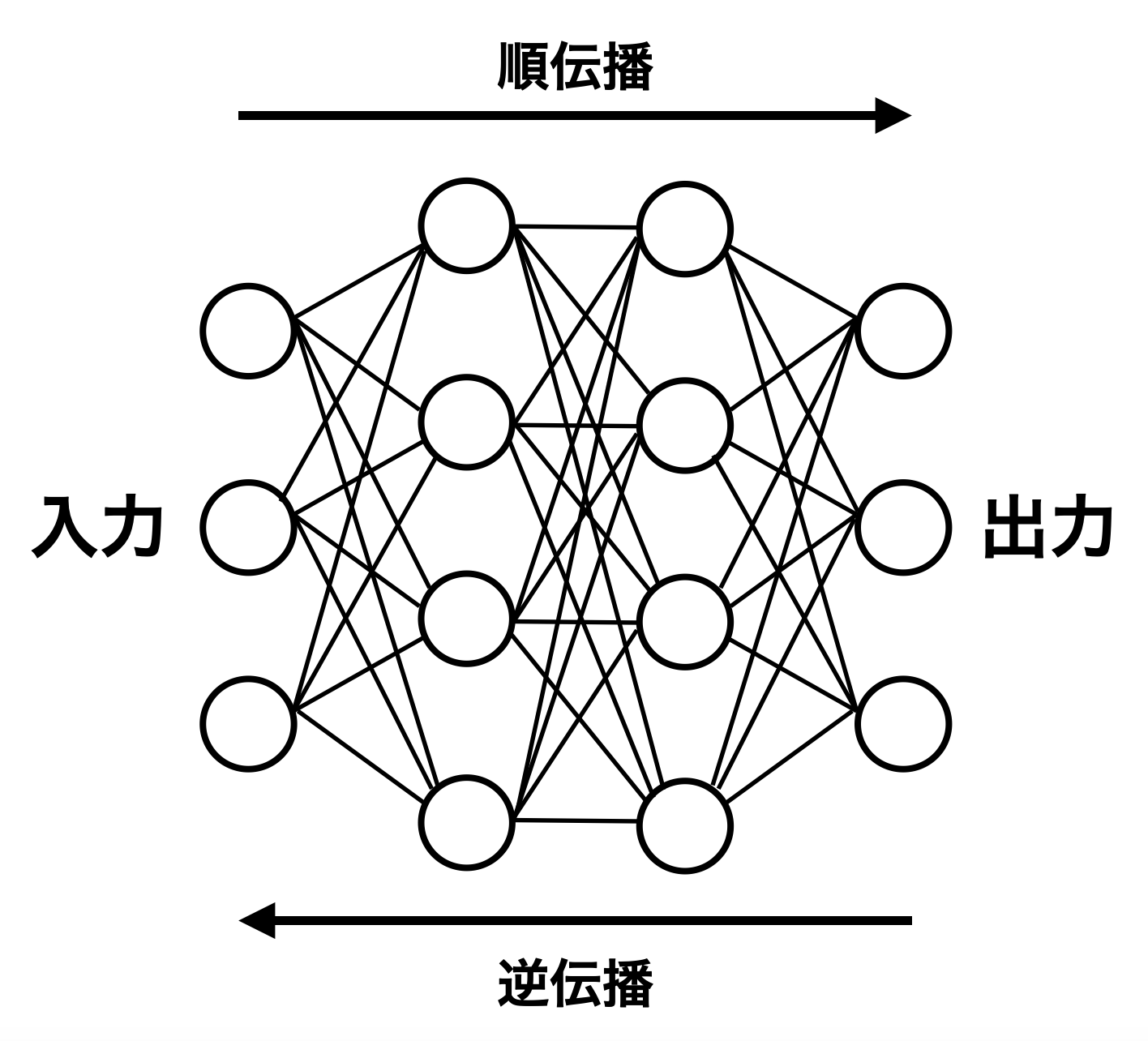
機械学習では入力を入れて出力を返す順伝播と、順伝播で得られた出力から算出された誤差情報をもとにモデルの重みの勾配情報を求める逆伝播という二つのデータの流れがある。ここではPyTorch等の機械学習ライブラリの実装に着目する。順伝播は比較的簡単に実装できそうである。一方逆伝播はどうだろうか?勾配はどうやって求めるのか?
この記事ではこうした問いについて考え、機械学習ライブラリを拡張する方法についても軽く紹介する。
先に要約
要約1/2. 勾配どうやって求める?
[予想]
- 予想1:数値的に以下のような式で近似的に求めるのだろうか?
{\rm lim_{h \rightarrow 0}}\frac{f(x+h) - f(x)}{h}
- 予想2:それとも、解析的に解かれた形を事前に用意してあるのだろうか?
[答え]
後者(予想2)。関数ごとに微分した形がセットで事前に用意してくれてある。
[例]
-
PyTorchの一例
https://github.com/pytorch/pytorch/blob/main/tools/autograd/derivatives.yaml より1516行目〜1518行目
- name: sin(Tensor self) -> Tensor
self: grad * self.cos().conj()
result: auto_element_wise
-
TensorFlowの一例
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/math_grad.py より1260行目〜1266行目
...
@ops.RegisterGradient("Sin")
def _SinGrad(op: ops.Operation, grad):
"""Returns grad * cos(x)."""
x = op.inputs[0]
with ops.control_dependencies([grad]):
x = math_ops.conj(x)
return grad * math_ops.cos(x)
これらはどちらもsin関数(順伝播)と、それを微分した形であるcos関数(逆伝播)が紐づいた形で保持されている。
要約2/2. 機能拡張って何ができる? どうやってやる?
新しい関数を作ったりできる。これはpythonで作って呼び出すこともできるし、C++で作って呼び出すこともできる。また、最近のライブラリでは関数や自動微分の実装を行うバックエンド部分をカスタマイズすることもできる。
[例]
以下はPyTorchでReLUをpythonを使って謎改造した新関数neo_reluを例として示す。
import torch
from torch.autograd import Function
class NeoReLU(Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
output = input.clone()
output[input <= 0] = -0.1
return output
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input > 0] = 1
grad_input[input <= 0] = 0
return grad_input
neo_relu = NeoReLU.apply
ここで注意すべきは、PyTorchのオリジナルで用意されている関数たちと同様に、関数を作るに際して事前にペアとなる勾配の式もちゃんと自分で用意しておかなければならないということである。
次に、以下はKerasという高レベルAPIのバックエンドとしてJaxというライブラリを使うようにカスタマイズした例。
import os
os.environ["KERAS_BACKEND"] = "jax"
import keras
print(f"backend : {keras.backend.backend()}")
解説
機械学習ライブラリの機能には、"低レベル部分"と"高レベル部分"がある。低レベル部分では、行列計算や自動微分をいかに高速、高効率に行うかに労力が割かれている。高レベル部分ではユーザにとっていかに簡単な学習、推論プロセスを提供するかに力点が置かれている。
多くの機械学習ライブラリ(PyTorchやTensorflow、ChainerやMXNet等々)は低レベル部分も高レベル部分も独自に実装を行なっている。しかし、KerasやHuggingface、ONNXRuntimeなどは高レベルAPIとして配布されており、"バックエンド"として低レベル処理を行う部分を他のAPIに依存している。そしてこの他のAPIはカスタム可能である。低レベル処理は、先に挙げた低レベル部分も実装しているライブラリ群(PyTorch等)や、高速な数値計算が可能なJax、scipy、Numpy、CuPyが挙げられる。
| ライブラリ | Keras | Huggingface | Scikit-learn | SciPy | ... |
|---|---|---|---|---|---|
| 低レベルAPI (よく使われているもの: 本来はカスタム可能) |
Tensorflow | PyTorch | Numpy | BLAS | ... |
低レベルパートのカスタマイズ
例えばKerasはTensorflowのある程度新しいバージョンでは、pip install tensorflowでインストールした時点でkerasも統合された形で含まれており、以下のように使うことが多い。
from tensorflow import keras
print(f"backend : {keras.backend.backend()}") # 当然Tensorflowと表示される
ここでこのバックエンドをいじろうと思うと、以下のような手順が必要になる。ここでは、高速な数値計算が可能なJaxをバックエンドとして使ってみようと思う。
まず、tensorflowとは別でkeras, jaxをpip等でインストール(この際バージョンの依存関係に注意)し、以下のように指定。
import os
os.environ["KERAS_BACKEND"] = "jax"
import keras
print(f"backend : {keras.backend.backend()}") # jaxと表示されたらカスタム成功
その後、以下のようにKerasのAPIを叩くことができる。
def build_cnn(activation='relu'):
return keras.Sequential([
keras.layers.Conv1D(64, 3, padding='same', activtion=activation),
keras.layers.BatchNormalization(),
...
])
これにより、Tensorflow backendよりも高速なKeras環境を構築することができる。このように、低レベルAPIはBlackbox化されがちだが本来はカスタマイズできるものである。以降、高レベルと低レベルのAPIについて解説していく。
高レベルAPIって?
先に、高レベルAPIから説明する方がわかりやすい気がするので、例を示す。例えばTensorflowだけ(Kerasモジュールは使わない)でMNISTの分類タスクの訓練・評価コードを書く場合、以下のようになる。
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import numpy as np
# データのロードと前処理
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train, x_test = x_train.reshape(-1, 28*28).astype('float32'), x_test.reshape(-1, 28*28).astype('float32')
y_train, y_test = tf.keras.utils.to_categorical(y_train, 10), tf.keras.utils.to_categorical(y_test, 10)
# モデルの定義
class SimpleModel:
def __init__(self):
self.W1 = tf.Variable(tf.random.normal([784, 128]), name="W1")
self.b1 = tf.Variable(tf.zeros([128]), name="b1")
self.W2 = tf.Variable(tf.random.normal([128, 10]), name="W2")
self.b2 = tf.Variable(tf.zeros([10]), name="b2")
def __call__(self, x):
hidden = tf.nn.relu(tf.matmul(x, self.W1) + self.b1)
output = tf.matmul(hidden, self.W2) + self.b2
return output
# モデルのインスタンス化
model = SimpleModel()
# 損失関数
def loss_fn(logits, labels):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
# オプティマイザ
optimizer = tf.optimizers.Adam()
# トレーニングステップ
@tf.function
def train_step(x, y):
with tf.GradientTape() as tape:
logits = model(x)
loss = loss_fn(logits, y)
grads = tape.gradient(loss, [model.W1, model.b1, model.W2, model.b2])
optimizer.apply_gradients(zip(grads, [model.W1, model.b1, model.W2, model.b2]))
return loss
# トレーニングループ
epochs = 5
batch_size = 32
for epoch in range(epochs):
for i in range(0, len(x_train), batch_size):
x_batch = x_train[i:i+batch_size]
y_batch = y_train[i:i+batch_size]
loss = train_step(x_batch, y_batch)
print(f"Epoch {epoch+1}, Loss: {loss.numpy()}")
# モデルの評価
logits = model(x_test)
predictions = tf.argmax(logits, axis=1)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predictions, tf.argmax(y_test, axis=1)), tf.float32))
print(f"Test Accuracy: {accuracy.numpy()}")
一方、これをKerasモジュールを使うことで、以下のように簡潔に記述できるようになる。
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# データのロードと前処理
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.reshape(-1, 28*28)
x_test = x_test.reshape(-1, 28*28)
# モデルの定義
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# モデルのトレーニング
model.fit(x_train, y_train, epochs=5, batch_size=32)
# モデルの評価
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f"Test Accuracy: {test_acc}")
この例のように高機能APIは、例えば全結合層というDenseレイヤー関数を用意してくれていたり、重みの初期化や訓練を簡潔に記述できるための機能である。
低レベルAPIは?
こっちはもっと機械学習の根幹をなす機能を実装してくれている部分である。例えば教師ありの機械学習モデルの学習では、必ず入力データがあり、それをもとに出力を返す。この出力が”正解”にどれだけ近いかを"損失"により評価し、損失がなるべく小さくなるようにモデルの重みを更新していく。
この過程では順伝播、逆伝播という二つのデータの流れが存在し、これらを繰り返して損失を小さくするために自動微分という仕組みを使って重みが更新されていく。順伝播とは入力から出力へと向かうデータの流れで予測値を吐き出してくれる。逆伝播は、順伝播で得られた予測値と正解の誤差の情報をもとに出力から入力へと向かうデータ流れで、モデルを構成する重みに対する損失の"勾配情報"を伝えてくれる。
このように低レベルAPIは、機械学習の基盤となる順伝播のデータの流れと逆伝播のデータの流れを正しく、そして効率良く実装することが求められる。
低レベルAPI実装に必要な要素は?
順伝播の実装は簡単な気がする。入力データを受け取って、必要な関数と途中段階での出力値を用意・保持できる仕組みさえあれば出力を得ることは可能である。一方で逆伝播はどうだろうか? パッと思いつく予想として、以下二つが考えられる。
- 予想1:数値的に以下のような式で近似的に求めるのだろうか?
{\rm lim_{h \rightarrow 0}}\frac{f(x+h) - f(x)}{h}
- 予想2:それとも、解析的に解かれた形を事前に用意してあるのだろうか?
予想1については、勾配を求める度に極限を求めるのではあまりに時間を要する上、計算機上で丸め誤差が生じてしまい、精度的にも問題である。先述の通り、低レベルAPIはいかに高速に高精度に演算を行うかに注力されているため機械学習ライブラリでは後者(予想2)で勾配は求められている。
逆伝播では、各層で入力・重みに対する損失関数の勾配情報を連鎖的に求めていく。この過程では以下4つの情報が必要となる。
- 順伝播時の各層の出力
- 活性化関数の微分の数式
- 損失関数の微分の数式
- 各層での入力に対する勾配の情報
例えばこの中でPyTorchの低レベルAPIの例として活性化関数に注目してみる。わかりやすい例としては、https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/Activation.cpp にて明示的に順伝播と逆伝播が実装されているものが挙げられる(以下)。
Tensor hardswish(const Tensor& self) {
#if defined(C10_MOBILE) && defined(USE_XNNPACK)
if (xnnpack::use_hardswish(self)) {
return xnnpack::hardswish(self);
}
#endif
Tensor result;
auto iter = TensorIterator::unary_op(result, self);
hardswish_stub(iter.device_type(), iter);
return iter.output();
}
...
Tensor hardswish_backward(const Tensor& grad_output, const Tensor& self) {
Tensor grad_input;
auto iter = TensorIterator::borrowing_binary_op(grad_input, grad_output, self);
hardswish_backward_stub(iter.device_type(), iter);
return iter.output();
}
この例では関数を順伝播と逆伝播それぞれ実装してあり、直感的にわかりやすい。しかし多くのもっと単純な関数に対しては、いちいちペアを定義せずとも使い回されている基本的な操作単位で、微分公式を自動で生成する仕組みが用いられている。これは https://github.com/pytorch/pytorch/blob/main/tools/autograd/gen_autograd_functions.py で生成されている。このコードは同じ階層にいる https://github.com/pytorch/pytorch/blob/main/tools/autograd/derivatives.yaml というyamlファイルを読み込むことで、操作と対応する勾配公式を取得することが可能になっている。このyamlファイルでは、例えば以下のように基本的な操作と、対応する勾配公式のセットが記述されている。
# 例:1516〜1518行目
- name: sin(Tensor self) -> Tensor
self: grad * self.cos().conj()
result: auto_element_wise
この例では、sin関数という操作を順伝播では行い、逆伝播では損失関数に対する勾配にsin関数を微分したcos関数を作用させている様子がわかる。このように基本的な操作ごとに順伝播(name:~)と逆伝播(self:~)が定義されており、自動微分の過程でこれらが適宜呼び出されている。
他にもPyTorchは使用している環境に応じて異なるバックエンドを呼び出す(例えばIntel製だったらMKL-DNNを使うとか..)等高速化のための様々な工夫を行なっているが、ここでは割愛させて頂く。
PyTorchでカスタム関数の追加(python)
以上のようにPyTorchの低レベルAPIでは事前に関数や操作ごとに対応する勾配の形を事前に定義しておき、それを適宜呼び出して順伝播と逆伝播を実装していた。ここではこのような関数もまたカスタム可能である点について確認しておく。
例えば、新しい活性化関数を作りたい場合、次のような手順で新しい関数neo_reluを使うことができる。なんの意味があるかは不明だが、ここではneo_reluはreluに以下の修正だけを加えて遊んでみる。
- 0以下の時に、値が0ではなく-0.1になるように修正
- 他は全て
reluと同じ
実装の方針は、PyTorchのtorch.autograd.Functionクラスを用いて、カスタムの自動微分関数を定義する。これまで見てきたように、新規の関数にも順伝播の処理と対応する逆伝播の処理を記述できていれば良い。また、ここではカスタム関数作成の際に用いられるctxオブジェクトを使用した。このオブジェクトの使用により、順伝播と逆伝播の間でデータの共有が可能になる。
import torch
from torch.autograd import Function
class NeoReLU(Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
output = input.clone()
output[input <= 0] = -0.1
return output
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input > 0] = 1
grad_input[input <= 0] = 0
return grad_input
neo_relu = NeoReLU.apply
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = neo_relu(self.fc1(x)) # NeoReLUを使用
x = self.fc2(x)
return x
model = SimpleNN()
しかしこの呼び出し方では速度が遅い。PyTorchでは基本的なテンソル演算の処理はATenライブラリでC++で記述されており、C++でカスタマイズした形も共有しておく。
PyTorchでカスタム関数の追加(C++)
C++でのカスタマイズは以下のようになる。
-
neo_reluをC++コードで記述(neo_relu.cpp) - ビルドして共有ライブラリファイル(
neo_relu_extension.so)を生成 - これをインポート
これまで同様、C++になったとしても、基本的には順伝播と逆伝播の処理を記述していれば良い。
#include <torch/extension.h>
#include <vector>
// 順伝播
torch::Tensor neo_relu_forward(torch::Tensor input) {
auto output = torch::clone(input);
output = torch::where(input > 0, input, torch::ones_like(input) * -0.1);
return output;
}
// 逆伝播
torch::Tensor neo_relu_backward(torch::Tensor grad_output, torch::Tensor input) {
auto grad_input = torch::clone(grad_output);
grad_input = torch::where(input > 0, grad_output, torch::zeros_like(input));
return grad_input;
}
// カスタム関数の定義
class NeoReLUFunction : public torch::autograd::Function<NeoReLUFunction> {
public:
static torch::Tensor forward(torch::autograd::AutogradContext *ctx, torch::Tensor input) {
ctx->save_for_backward({input});
return neo_relu_forward(input);
}
static torch::autograd::variable_list backward(torch::autograd::AutogradContext *ctx, torch::autograd::variable_list grad_output) {
auto saved = ctx->get_saved_variables();
auto input = saved[0];
auto grad_input = neo_relu_backward(grad_output[0], input);
return {grad_input};
}
};
// NeoReLUの呼び出し
torch::Tensor neo_relu(torch::Tensor input) {
return NeoReLUFunction::apply(input);
}
// PyTorchに登録
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("neo_relu", &neo_relu, "NeoReLU activation function");
}
setuptoolsとtorch.utils.cpp_extensionを使って、共有ライブラリファイルを生成するためのsetup.pyを以下のように記述
from setuptools import setup, Extension
from torch.utils.cpp_extension import BuildExtension, CppExtension
setup(
name='neo_relu_extension', # 生成する拡張モジュールの名前
ext_modules=[
CppExtension('neo_relu_extension', ['neo_relu.cpp']), # C++ソースファイルを指定
],
cmdclass={
'build_ext': BuildExtension # ビルドコマンドを拡張
})
その後、
python setup.py build_ext --inplace
コマンドで共有ライブラリファイル(今回はneo_relu_extension.so)が生成される。あとは以下のようにこれを呼び出して先ほどのコードに組み込む。
import neo_relu_extension
import torch.nn as nn
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = neo_relu_extension.neo_relu(self.fc1(x)) # NeoReLUを組み込み
x = self.fc2(x)
return x
最後に
機械学習ライブラリの低レベルAPI部分は、意外とカスタム可能である。今回はバックエンドのカスタマイズの仕方を示し、関数の追加の仕方をpythonとC++で例を示した。また低レベルAPIで順伝播と逆伝播で必要な処理をまとめ、実際にPyTorchを例に関数ごとにそれらを事前に用意してくれているということも確認した。
参考
・PyTorchのpythonを使った機能拡張
https://pytorch.org/docs/stable/notes/extending.html
・PyTorchのC++を使った機能拡張
https://pytorch.org/tutorials/advanced/cpp_extension.html