はじめに
本記事はAutoBERT-Zero1という論文の概要を紹介するものである。Neural Architecture Search(NAS)は深層学習アーキテクチャの最適化手法であり、こと自然言語処理を指向したものの多くはRNNベースのセル内活性化関数の組み合わせを最適化するものであったり、元々存在しているblock(self-attentionやresidual blockなど)をどう組み合わせるかを探索するケースが多く、全く新しいアーキテクチャが得られるかもしれないという驚き度合いに欠けるものが多い(計算リソース上仕方のない事ではある)。その点今回紹介するAutoBERT論文は探索対象となる候補アーキテクチャの集合が大きく、TransformerのattentionがQ,K,Vの3分岐を作る構造で組まれている所を疑ったり、局所的な処理を行うオペレータを導入したりと新規性が大きいところが魅力である。その対価として存在する計算コスト問題に打ち勝つため、様々な工夫がなされている。
Overview
AutoBERT-Zero1はAAAI2022にて発表されたTransformerの構造を最適化するためのNAS手法である。Transformer(のエンコーダ部分)を用いたアーキテクチャの中でも特に様々な下流タスクに事前学習済みモデルとして供与されるBERT2のバックボーン改良を指向したNASで精度の向上を確認した。より良いBERTを探せたという意味で、今回探索して得られたアーキテクチャはAutoBERT-Zeroと呼ばれる。
Query, Key, Valueの3つからなるattention構造は本当に最適なのか?内2つだけでは問題なのか?あるいはもっと増やしてはダメなのか?局所的な処理を行う演算である畳み込みも使うべきではないか?..等々既存の色々なTransformerに関する疑問や提案全てを探索空間に組み込み、進化アルゴリズムを用いて探索したのがAutoBERTである。AutoBERTの功績は以下の3つに集約される。
- 学習済み言語モデルのbackbone設計に資する、新しく広い探索空間を初めて設計した。
- 膨大な探索空間を効果的に探索可能な探索戦略(Operation Priority)を設計した。
- 高速な性能推定を可能にするためにBIWS (BI-branch Weight Sharing)を導入した。
What is BERT ?
BERT(Bidirectional Encoder Representations from Transformers)の新規性はアーキテクチャではなく、そのタスク(何を学習するか?)にある。BERTのアーキテクチャはTransformerのEncoder部分をそのまま用いている。BERTはMLM(Masked Language Modeling)とNSP(Next Sentence Prediction)という二つのタスクを同時に行っている。MLMは入力として与えたsentenceの一定割合のトークンをマスクし、そこにあった正解を予測する。NSPは二つの連続するsentenceの片方を50%の割合で関係無いsentenceに置き換え、二文が連続か否かを当てる学習をする。こうした学習はデータの用意が非常に簡単であり、特定の言語の文章をひたすら与えれば済むという特徴がある(入力と正解のセットを用意する必要はない)。またBERTはMLMとNSPの二つのタスクを学習するが、この時与えたトークンの未来の情報を参考にすることが許容されている(ここがBidirectionalと呼ばれる所以)。
このようにしてBERTで得られた学習済みモデルをEncoderの初期値とした様々な下流タスクで高い精度が確認され、個々のタスクで一からTransformerを学習させなくても良いという圧倒的な利点からBERTは”便利屋”として名声を広めた。本記事にて紹介する論文が提唱する新規NAS手法はこの下流タスクへの応用能力に長けた便利屋BERTを改良するもので、その需要の大きさは計り知れないだろう。
Issue
Transformerのアーキテクチャにはいくつかの疑義が存在する。この論文ではその方向性の具体例として、Dongら論文3やKitaevらの論文4、Jiangらの論文5が挙げられている。
Dongらは"Attention is not all you need〜"という文言を含むショッキングなタイトルの論文を発表し、ピュアなself-attentionの構造だけを積層すると(スキップ構造やLayerNormなどが無いと)アテンションマトリクスの表現力が指数関数的に減衰してしまうという課題を指摘し、Attentionだけが大事だという論調に疑義を唱えた。
KitaevらはReformerというモデルを開発し、TransformerのAttention matrixの類似度算出には冗長性があり、事前にある程度類似度が高いトークン間だけで類似度を算出する手法を開発した。Reformerでは、この類似度算出のためにLSH (Random Projection) というアイデアを採用し、類似度が高いトークンを一つの"バケット"としてまとめ、バケット内のトークンの類似度だけを算出することを考案した。この時Reformerはバケットを構成するトークンの内訳が異なってしまうことを防ぐためにQuery=Key (QueryとKeyを区別せずまとめてQueryとする)として、Query同士で類似度を算出した。ここで、QueryとKeyを区別しなくても区別した時と比べて精度が落ちないということが確認されており(下図)、既存のTransformerのattention設計に冗長性があることを結果から示している。

また、JiangらはConvBERTというモデルを開発し、局所的な特徴の集約を行う畳み込み処理を適切にattention構造内に挿入することで精度の向上を確認した。
以上をまとめると本研究AutoBERTは既存のTransformerのattentionの構造がベストではないことを課題として挙げ、
・attentionだけを積層させても精度は良くない。
・QueryとKeyには冗長性がある。
・局所的な特徴抽出も必要。
という3点を大きく取り上げ、これらを受けてBERTを改良するNASアルゴリズムを開発した。
What is NAS?
NASは深層学習のアーキテクチャ設計を自動化する手法で、Neural Architecture Searchの略である。大きく
・探索空間
・探索戦略
・性能推定
の3つの部分に分かれる。アーキテクチャ設計は骨の折れる作業なので自動化できると世界中の人々が喜ぶ。
探索空間
探索空間は候補アーキテクチャの集合のことである。しばしば候補アーキテクチャ生成のための制約と同義で使われるが、原義は候補アーキテクチャたちの集合全体を探索空間と呼ぶ。例えば
”層は全部で3層”
”オペレータはConv3x3かmax poolingかFully connected”
”直鎖状”
といった制約を候補アーキテクチャ生成時に課した場合、探索空間の中には、直鎖3層の各位置に3通りのオペレータが来て良いことになるので全部で$3^3=27$個の候補アーキテクチャが存在するという事になる。このとき探索空間の”サイズは27個からなる”というように表現できる。近年多くのNASは広大な探索空間内をいかに高速に探せるかに力点が置かれているものが多い。しかし、この探索空間の改良が果たすNAS界への貢献はより抜本的なものだと言える。今回扱うAutoBERT-Zeroの論文では、著者らは新規かつ広大な探索空間を設計している。
探索戦略
探索戦略は文字通り探索空間内を効率良く探索し、探索空間内でベストなパフォーマンスを発揮する1候補を決定するための戦略である。古典的にはランダムサンプリング、強化学習、進化アルゴリズムを用いたものが用いられ、今回は進化アルゴリズムを用いている。
性能推定
性能推定はサンプリングされた候補アーキテクチャの性能を推定する手法である。高速化の観点から候補を逐一学習させて正確な精度を算出する必要はなく、あくまで候補アーキテクチャ間の相対的な序列を大まかに付けられれば十分であると考えられる場合が多い。例えばエポック数を固定の値に定め、そのエポック数時点までのAccuracyの推移から最終的に落ち着く精度を外挿する手法や、一から候補アーキテクチャを学習させるのではなく、一つ前のラウンドでサンプリングされた際の重みをそのまま使い回すWeight Sharingなどの方法がある。
Method
著者らはBERTのバックボーンTransformerの構造改良を指向した新規NASアルゴリズムOP-NASを考案し、OP-NASを通じて得られたAutoBERT-Zeroというアーキテクチャが既存のBERTやその他の言語モデルより高い性能を示すことを確認した。OP-NASにはNASを構成する探索空間・探索戦略・性能推定のそれぞれの観点で新しさがあるため、この3つに分けて説明をする。
探索空間
intra-layer(層内レベル) levelとintra-layer level(層間レベル)という二つの階層で同時に探索を行う。OP-NASでは、畳み込みとself-attentionを混ぜたような構造を探索する。
intra-layer level:
各層にはself-attentionか畳み込みかのいずれかが選択され(詳細はinter-layer levelにて説明)、層内レベルでは、self-attentionとしてより新しい構造を探索するか、畳み込みのカーネルサイズを最適化するかの2種類の探索しか行われない。
1.self-attentionの構造を決定するための探索
この研究で一番大事なところ。AutoBERTは探索対象とするself-attentionはQ, K, V, Pという4種類の"入力ノード"から2〜4つを選択することを許容する(Transformerのself-attentionがQuery、Key、Valueの計3ノードなので恐らく1つずつ増やし・減らしてみたということだろう)。入力ノードが決まったらそこにノードを追加していく。各ノードには何がしかのオペレータが割り当てられ、その候補は以下の図のとおりである。

この表より、割り当て可能なオペレータは1入力1出力である"unary"6種類と2入力1出力であるオ"binary"4種類があることが分かる。evolutional searchでどうやって候補のアーキテクチャをgenotypeに変換しているかは明記されていないが、およそ以下のようなことが行われていると考えられる。
- self-attentionアーキテクチャのgenotypeへの変換について(個人的な推測):
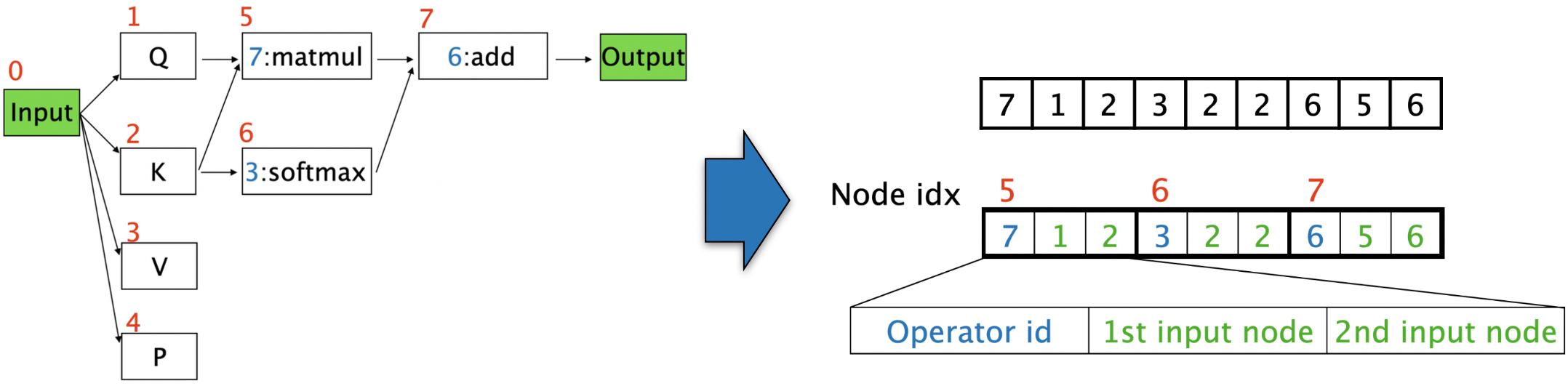
Q,K,V,Pに追加するノードに関する情報は"どこから入力を受けるか"、そして"オペレータは何か"という2種類である。この情報を3文字の数字列に変換することができる(下図)。仮にオペレータがunaryだった場合、1st inputと2nd inputは同じにすれば良い。下の図の例では、左側に示した候補アーキテクチャの各ノードにNode idx(赤字)が振られており、このNode idxの小さい順に3文字ずつを使って(どこからエッジを受けるか、どのオペレータを使うか)を決めている。エッジは自分自身より小さいNode idxのノードからしか受けられないと言った制約や、突然変異時にunaryの1st input 2nd inputが違うノードにならないようにすると言った制約など恐らく色々な細かいルールがあるものと推測される。(ここのくだりはあくまで個人的な推測に過ぎない)
2.畳み込みのカーネルサイズを決定するための探索
畳み込みは様々な受容野を探索できるように3x1, 5x1, 7x1, 9x1, 15x1, 31x1, 65x1のカーネルが用意されており、この中から最適な一つのカーネルを選ぶ。
inter-layer level:
層の数はBERTの条件と揃え12層として実験は行っている。各層にはself-attentionを入れるかConvolutionを入れるかを選択 (下図緑はself-attention, 青はcnvolution)。

探索戦略
概要を以下の図に示す。

OP-NASでは、進化アルゴリズムをベースにしたOperation Priorityという戦略を用いている。
進化アルゴリズムではまず探索空間内からM個の候補アーキテクチャを初期個体としてランダムにサンプリングする(上図1行目)。次にこれらの性能評価を行い(上図2行目)、性能の高いTop K個をサンプリングする(上図4行目)。これらを親個体として、各親からInterLayer level での突然変異とIntraLayer levelでの突然変異を行い(上図6,7行目)、複数の子個体を生成する。生成した子個体について性能推定を行い(上図8,9行目)、これをもとに初期個体群Mをアップデートする(上図11行目)。
ここまではただの突然変異を行う進化アルゴリズム探索に見えるが、OP-NASの新規性は以下の二つである。
- 突然変異を起こす際に効率の観点から、完全にランダムな変異を起こすのではなくUCB-scoreをもとに効果的な位置で変異を起こすように促進する点
- 子個体の性能推定速度を高速化するための戦略としてBIWSという重み共有法を用いている点("性能推定"にて後述)
が挙げられる。それぞれについて簡単に説明する。
UCB (Upper Confidence Bound) Scoreというスコアは、膨大な探索空間内を効率良く探索するために、それまでに探索済みの個体の中から有望なものを積極的に選ぶ活用と未探索の領域を積極的に選ぶ探索の二つの条件のバランスを取ったスコアリング手法である。強化学習の文脈でもよく登場する。
UCBスコアは突然変異の際に、あるオペレータをどの位置に(変異先として)用いるのが一番効果的かという情報を算出する。ある位置iで特定のオペレータに変異させる時のUCB score $u_i$ は以下のように求められる。
u_i = \mu_i + \alpha \sqrt{\frac{2\log N}{N_i}}
$\mu_i$はその探索時点までに登場している同オペレータを同位置(入力ノードからのホップ数)で用いた候補アーキテクチャの性能の平均である(=活用を保証)。
また、ルートの中身については分母の$N_i$はそのオペレータがその位置でこれまでの探索で登場した回数を、分子の$N$はこれまでの全てのオペレータがサンプリングされた総数を意味しており、右辺第二項を通じてよりサンプリングされた回数が少ない場合に高いスコアが付与されるように設計されている(=探索を保証)。$\alpha$は活用と探索のバランスを取るためのハイパーパラメータである。
最終的にどの位置であるオペレータに変異させるかは、全ての候補位置についてUCB scoreでソフトマックスを取り、最も確率が高い位置を採択する。
p_1, ..., p_n = {\rm softmax} (u_1, ..., u_n)
性能推定
子個体の性能推定時に、それぞれの個体(=候補アーキテクチャ)を一から学習させて精度を取っていたのではコストが膨らんでしまう。そこで、OP-NASはBIWS (BIbranch Weight Sharing) という重み共有手法を用いている。BIWSはself-attentionとconvolutionそれぞれで行われ、候補を全て包含する最大のアーキテクチャ(self-attentionではQ,K,V,Pの4つの重み、convolutionでは65x1カーネルの重み)から各候補をサンプリングする際に重みをそのまま引き継いで初期値とする手法である。Q,K,V,P以外のオペレータは重みを持たない原始的な演算なので、self-attentionの重み共有に関してはこの4つだけを考えていれば良い。
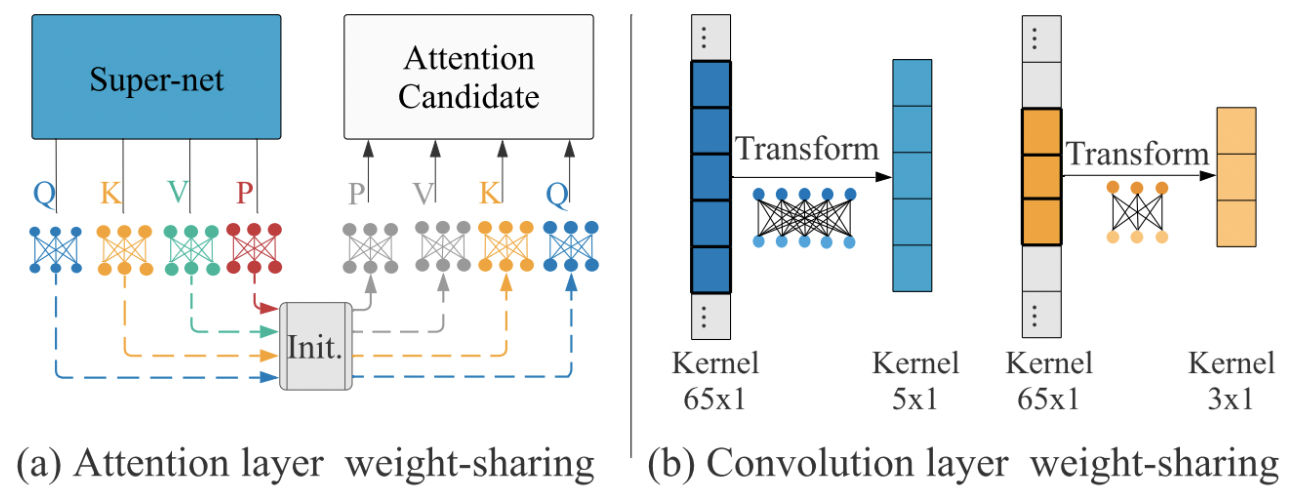
この図左側は、ある候補についてQ,K,V,PのうちQ,Kだけが選ばれているが、その重みの初期値は、その前までに学習済みの重みをそのまま引き継いでいる。また右側についても同様に、65x1カーネルのうちの採択されたカーネルサイズ部分だけが選ばれているが、その重みの初期値は前までに学習済みの重みがそのまま採用されている(何故上手くいくのだ?)。
Experiment
BERTと条件を揃え、NAS phase と Fully-Train phase に分かれる。
NAS
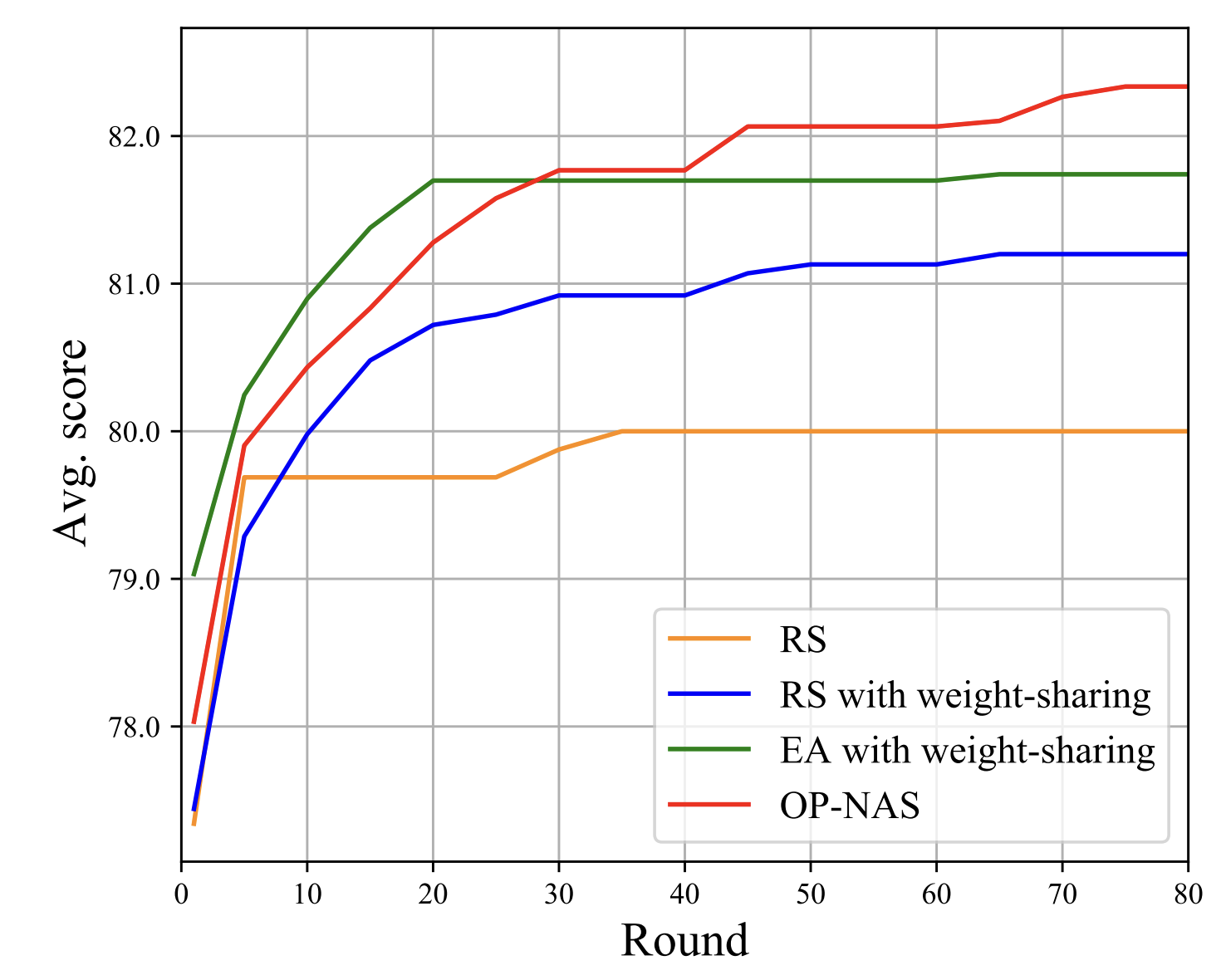
BERTの事前学習と条件は揃え、BookCorpusとEnglish Wikipediaデータセットを用いている。他の探索手法と比較し、以下のように本NAS手法OP-NASが高い精度を見つけられていることを確認している。この探索には24K GPU hoursがNvidia V100で必要で、BIWSを用いない場合にはそれが182K GPU hoursである旨が示されている。
また、探索して得られたアーキテクチャは以下の図のようであり、これをAutoBERT-Zeroと呼ぶ。

論文中ではこのアーキテクチャについて
- Self-attentionは浅い層ではQ,K,V,Pのうち二つだけあれば十分だが、出力層側ではQ,K,Vの形になっている.
- Convolutionは浅い層から深い層へカーネルサイズが降順(wide to narrow)になっている.
という2点について簡単に考察されていた。
また、BIWSの妥当性に関しては、以下のようなプロットを6点でとり、相関が確認できていることからディフェンスをしていた。この8つの図はGLUEデータセットの異なるタスクを示している。各プロットは候補アーキテクチャを示しており、横軸は探索中にBIWSによって付与されたスコアを、縦軸は同じアーキテクチャを該当タスクで一から学習させた時の精度を示している(プロットの横軸成分の値は8つの図全てで同じになっている点に注意)。

Fully-Train
GLUEとSQuADという二つのデータセットについて検証を行った。GLUEについては以下の通りで、いずれも先行研究より省パラメータかつ高精度を実現している。

SQuADについても以下の通りBERTより高い精度となっている。

Impression
- 探索空間がユニークで興味深い。(個人的にはgenotypeでattentionの構造をどう表現していたかとか細かい所が気になる)
- BIWSの妥当性について6プロットは少ないのでは?(都合の良いところだけ取ってくることもできてしまいそう)
- (割と前から思っていたことだが..)この手のWeight Sharingは小さい部分構造だけ異常に学習が進んでしまったりしないのだろうか?(今回の畳み込みで言えば3x1の部分とかは実質的に毎回採択されているに等しいから途中から学習が進行していなかったりしないのだろうか?)
Reference
-
URL : https://doi.org/10.1609/aaai.v36i10.21311
J Gao, H Xu, H Shi, X Ren et al. In Proceedings of AAAI Conference on Artificial Intelligence, pp.10663-10671, 2022. ↩ ↩2 -
URL : https://aclanthology.org/N19-1423.pdf
J Devlin, M.W Chang, K Lee, K Toutanova. In Proceedings of NAACL-HLT, pp.4171-4186, 2019. ↩ -
URL : https://proceedings.mlr.press/v139/dong21a.html
Y Dong, J.B Cordonnier, A Loukas. In Proceedings of International Conference on Machine Learning, PMLR, pp.2793-2803, 2021. ↩ -
URL : https://arxiv.org/abs/2001.04451
N Kitaev, L Kaiser, A Levskaya. arXiv preprint arXiv:2001.04451, 2020. ↩ -
URL : https://proceedings.neurips.cc/paper/2020/file/96da2f590cd7246bbde0051047b0d6f7-Paper.pdf
Z Jiang, W Yu, D Zhou, Y Chen et al. In Proceedings of NeurIPS, pp.12837-12848, 2020. ↩