はじめに
前回は、ロジスティック回帰を使ってアヤメの分類を行いました。今回はニューラルネットワークとMNISTを使って、手書き数字認識を行います。データローダーを使ったミニバッチ学習や、Transforms(transformer, attentionじゃない…念のため…)を使った前処理、GPUの利用なども実装したいと思います。
やったこと
- データセット: MNIST
- 問題: 多クラス分類
- 機械学習モデル: ニューラルネットワーク(隠れ層2つ)
- 活性化関数: ReLU
- 最適化手法: SGD
- 前処理: テンソル化、正規化(-1から1)、平滑化
- データローダーによるミニバッチ学習
- Transformsによる前処理
- GPU利用
ライブラリ
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from IPython.display import display
from tqdm.notebook import tqdm
# torch関連ライブラリのインポート
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchinfo import summary
from torchviz import make_dot
# warning表示off
import warnings
warnings.simplefilter('ignore')
# デフォルトフォントサイズ変更
plt.rcParams['font.size'] = 14
# デフォルトグラフサイズ変更
plt.rcParams['figure.figsize'] = (6,6)
# デフォルトで方眼表示ON
plt.rcParams['axes.grid'] = True
# numpyの表示桁数設定
np.set_printoptions(suppress=True, precision=5)
GPUの利用
ニューラルネットワークとなると、いよいよ計算量も増えてくるので、GPUが使える環境なら使いたくなってきます。
# デバイスの割り当て
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
GPUが使える環境なら"cuda:0"、そうでないなら"cpu"と返ってきます。cudaの環境構築については割愛。
データ準備
MNISTデータを取得します。
# ダウンロード先ディレクトリ名
data_root = './ignore_dir/data'
train_set0 = datasets.MNIST(
# 元データダウンロー先の指定
root = data_root,
# 訓練データか検証データか
train = True,
# 元データがない場合にダウンロードするか
download = True
)
データ件数は6万件、入力データの型はPIL、正解データの型はintです。
# データ件数の確認
print('データ件数: ', len(train_set0))
# 最初の要素の取得
image, label = train_set0[0]
# データ型の確認
print('入力データの型: ', type(image))
print('正解データの型: ', type(label))
画像を確認しておきます。
# 正解データ付きで、最初の20個のイメージ表示
plt.figure(figsize=(10, 3))
for i in range(20):
ax = plt.subplot(2, 10, i + 1)
# imageとlabelの取得
image, label = train_set0[i]
# イメージ表示
plt.imshow(image, cmap='gray_r')
ax.set_title(f'{label}')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
前処理(Transforms)
- Imageをテンソル化
- [0, 1]の範囲の値を[-1, 1]の範囲にする
- データのshapeを[1, 28, 28]から[784]に変換
# データ変換用関数 Transforms
transform = transforms.Compose([
# (1) データのテンソル化
transforms.ToTensor(),
# (2) データの正規化
transforms.Normalize((0.5,), (0.5,)),
# (3) 1階テンソルに変換
transforms.Lambda(lambda x: x.view(-1)),
])
訓練用データと検証用データに前処理を施します。後者はtrain引数をFalseにします。
# 訓練データセットの定義
train_set = datasets.MNIST(
root=data_root, train=True, download=True, transform=transform
)
# 検証データセットの定義
test_set = datasets.MNIST(
root=data_root, train=False, download=True, transform=transform
)
変換結果を確認します。
# 変換変換結果の確認
image, label = train_set[0]
print('shape: ', image.shape)
print('最小値: ', image.data.min())
print('最大値: ', image.data.max())
shape: torch.Size([784])
最小値: tensor(-1.)
最大値: tensor(1.)
データローダーによるミニバッチ用データ生成
# ミニバッチのサイズ指定
batch_size = 500
# 訓練用データローダー
# 訓練用なので、シャッフルをかける
train_loader = DataLoader(
train_set, batch_size=batch_size, shuffle=True
)
# 検証用データローダー
# 検証時にシャッフルは不要
test_loader = DataLoader(
test_set, batch_size=batch_size, shuffle=False
)
# 何組のデータが取得できるか
print(len(train_loader))
# データローダーから最初の1セットを取得する
for images, labels in train_loader:
break
print(images.shape)
print(labels.shape)
モデル定義
- 入力層:784, 隠れ層1:128, 隠れ層2:128, 出力層:10
# 入力次元数
n_input = image.shape[0]
# 出力次元数
# 分類先クラス数 今回は10
n_output = 10
# 隠れ層のノード数
n_hidden = 128
# 結果確認
print(f"n_input: {n_input} n_hidden: {n_hidden} n_output: {n_output}")
ポイント
- 線形層(nn.Linear)が増えた
- 2層目(出力層)の線形関数の出力に対して活性化関数がない(前回と同じ)
- 損失関数側にsoftmax関数も含める予定だから
- 以前は重みの初期値を1.0にしていたが、今回は乱数を使った最適な初期値にしている
- パラメータ数が増えると、うまく学習できなくなるから
# モデルの定義
# 784入力, 10出力, 2隠れ層のニューラルネットワークモデル
class Net2(nn.Module):
def __init__(self, n_input, n_output, n_hidden):
super().__init__()
# 隠れ層1の定義 (隠れ層のノード数: n_hidden)
self.l1 = nn.Linear(n_input, n_hidden)
# 隠れ層2の定義 (隠れ層のノード数: n_hidden)
self.l2 = nn.Linear(n_hidden, n_hidden)
# 出力層の定義
self.l3 = nn.Linear(n_hidden, n_output)
# ReLU関数の定義
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.l1(x)
x2 = self.relu(x1)
x3 = self.l2(x2)
x4 = self.relu(x3)
x5 = self.l3(x4)
return x5
再現性を担保するため、乱数を固定化しておきます。インスタンスを生成し、GPUに転送します。
# 乱数の固定化
torch.manual_seed(123)
torch.cuda.manual_seed(123)
# モデル変数の生成
net = Net2(n_input, n_output, n_hidden)
# モデルをGPUに送る
net = net.to(device)
学習率や損失関数(交差エントロピー関数)、最適化手法(SGD)を定義します。
# 学習率
lr = 0.01
# アルゴリズム: 勾配降下法
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
# 損失関数: 交差エントロピー関数
criterion = nn.CrossEntropyLoss()
モデル内のパラメータを確認します。
# モデル内のパラメータの確認
# l1.weight, l1.bias, l2.weight, l2.biasがあることがわかる
for parameter in net.named_parameters():
print(parameter)
('l1.weight', Parameter containing:
tensor([[-0.0146, 0.0012, -0.0177, ..., 0.0277, 0.0200, 0.0315],
[ 0.0184, -0.0322, 0.0175, ..., 0.0089, -0.0028, -0.0033],
[ 0.0092, 0.0261, 0.0075, ..., 0.0061, 0.0267, -0.0258],
...,
[ 0.0235, -0.0026, -0.0129, ..., 0.0322, -0.0059, -0.0169],
[-0.0328, -0.0258, 0.0124, ..., -0.0049, 0.0006, 0.0334],
[ 0.0187, -0.0076, -0.0202, ..., 0.0325, -0.0159, -0.0240]],
requires_grad=True))
('l1.bias', Parameter containing:
tensor([ 0.0325, -0.0298, 0.0013, 0.0199, 0.0268, -0.0248, -0.0172, -0.0355,
0.0122, -0.0048, 0.0214, 0.0202, -0.0243, 0.0015, -0.0276, 0.0296,
0.0341, -0.0228, 0.0230, 0.0347, -0.0091, -0.0346, 0.0206, -0.0060,
0.0329, 0.0047, 0.0180, 0.0101, 0.0177, -0.0309, 0.0228, -0.0224,
0.0321, 0.0179, 0.0321, 0.0184, 0.0219, -0.0089, 0.0310, -0.0039,
-0.0074, -0.0317, 0.0192, -0.0021, 0.0190, 0.0038, 0.0334, -0.0027,
-0.0127, 0.0229, -0.0265, 0.0023, -0.0162, -0.0134, -0.0027, 0.0212,
-0.0205, -0.0144, 0.0121, 0.0001, 0.0086, 0.0033, 0.0123, 0.0213,
-0.0177, 0.0247, -0.0109, -0.0222, 0.0228, -0.0110, -0.0074, -0.0089,
-0.0205, 0.0323, -0.0207, -0.0205, -0.0028, -0.0341, -0.0304, 0.0144,
0.0072, 0.0326, -0.0342, -0.0329, -0.0032, -0.0200, -0.0029, -0.0098,
0.0220, -0.0160, 0.0099, 0.0033, -0.0289, 0.0110, 0.0199, 0.0131,
-0.0279, 0.0122, 0.0237, 0.0126, -0.0055, -0.0088, -0.0057, -0.0048,
0.0007, -0.0017, -0.0324, 0.0048, -0.0134, 0.0334, 0.0298, -0.0060,
0.0263, 0.0113, -0.0113, 0.0150, 0.0091, -0.0311, -0.0079, 0.0002,
-0.0282, -0.0016, 0.0304, -0.0237, -0.0157, -0.0255, 0.0006, 0.0100],
requires_grad=True))
('l2.weight', Parameter containing:
tensor([[ 1.0686e-02, 7.1428e-02, 1.5281e-02, ..., 7.0354e-02,
5.0548e-02, -3.8243e-02],
[-6.6035e-03, 3.4752e-02, 1.4309e-02, ..., -3.8919e-03,
-1.4064e-02, 1.3045e-02],
[-2.5098e-02, -6.5415e-02, 5.6672e-02, ..., -4.3480e-02,
1.5353e-02, 2.5580e-02],
...,
[-5.8016e-02, -2.9347e-03, -6.0429e-02, ..., 3.4195e-02,
5.1813e-02, -7.9175e-02],
[-7.6413e-02, -6.8121e-02, 1.7248e-05, ..., -1.7737e-02,
-5.1962e-02, -1.8203e-02],
[ 1.6337e-02, -6.6871e-02, -3.7982e-02, ..., -3.9229e-02,
6.6033e-02, 7.4760e-02]], requires_grad=True))
('l2.bias', Parameter containing:
tensor([-0.0259, 0.0621, 0.0616, -0.0599, 0.0395, -0.0687, -0.0756, -0.0144,
0.0041, -0.0375, -0.0776, 0.0086, -0.0511, 0.0809, 0.0300, 0.0507,
0.0349, -0.0345, 0.0084, -0.0685, -0.0777, 0.0253, -0.0634, -0.0293,
0.0847, -0.0502, 0.0248, 0.0137, -0.0442, -0.0068, 0.0689, -0.0553,
0.0582, -0.0150, 0.0216, 0.0352, -0.0229, 0.0177, -0.0773, -0.0359,
-0.0773, 0.0509, 0.0032, -0.0706, -0.0192, 0.0691, -0.0436, -0.0168,
0.0086, -0.0130, -0.0337, -0.0831, -0.0629, -0.0638, -0.0534, 0.0146,
0.0504, -0.0062, 0.0578, 0.0247, -0.0652, -0.0041, 0.0612, -0.0598,
-0.0551, -0.0288, 0.0157, 0.0268, 0.0800, -0.0606, -0.0274, -0.0418,
-0.0417, -0.0295, -0.0628, -0.0879, -0.0355, -0.0823, 0.0112, 0.0322,
-0.0523, 0.0575, 0.0691, -0.0472, 0.0239, 0.0549, 0.0465, 0.0574,
0.0423, 0.0347, -0.0255, 0.0329, -0.0464, 0.0302, -0.0087, 0.0501,
0.0615, 0.0288, 0.0841, -0.0142, -0.0133, -0.0647, 0.0335, -0.0500,
0.0204, -0.0064, 0.0881, 0.0469, -0.0385, 0.0063, -0.0096, 0.0175,
0.0090, 0.0665, 0.0503, -0.0687, 0.0612, 0.0516, -0.0166, 0.0331,
-0.0818, -0.0690, 0.0495, 0.0323, -0.0774, -0.0219, -0.0164, -0.0393],
requires_grad=True))
('l3.weight', Parameter containing:
tensor([[ 0.0649, 0.0309, -0.0747, ..., 0.0200, -0.0384, -0.0639],
[-0.0175, 0.0138, -0.0867, ..., -0.0819, -0.0826, -0.0119],
[ 0.0701, -0.0171, 0.0172, ..., 0.0163, 0.0719, -0.0816],
...,
[ 0.0730, -0.0627, 0.0085, ..., 0.0734, -0.0004, -0.0043],
[ 0.0641, 0.0212, 0.0335, ..., 0.0734, -0.0223, -0.0630],
[-0.0299, -0.0452, -0.0311, ..., -0.0414, -0.0062, -0.0405]],
requires_grad=True))
('l3.bias', Parameter containing:
tensor([ 0.0165, 0.0498, 0.0479, 0.0135, 0.0408, 0.0769, 0.0824, 0.0692,
-0.0026, 0.0409], requires_grad=True))
メインループ
エポック数の設定と、評価結果記録用の配列を用意します。
# 繰り返し回数
num_epochs = 200
# 評価結果記録用
history = np.zeros((0, 5))
ようやく訓練開始!
# 繰り返し計算のメインループ
for epoch in range(num_epochs):
# 1エポック当たりの正解数(精度計算用)
n_train_acc, n_val_acc = 0, 0
# 1エポックあたりの類型損失(平均化前)
train_loss, val_loss = 0, 0
# 1エポックあたりのデータ累積件数
n_train, n_test = 0, 0
# 訓練フェーズ
for inputs, labels in tqdm(train_loader):
# 1バッチあたりのデータ件数
train_batch_size = len(labels)
# 1エポックあたりのデータ累積件数
n_train += train_batch_size
# GPUへ転送
inputs = inputs.to(device)
labels = labels.to(device)
# 勾配の初期化
optimizer.zero_grad()
# 予測計算
outputs = net(inputs)
# 損失計算
loss = criterion(outputs, labels)
# 勾配計算
loss.backward()
# パラメータ更新
optimizer.step()
# 予測ラベル導出
predicted = torch.max(outputs, 1)[1]
# 平均前の損失と正解数の計算
# lossは平均計算が行われているので平均前の損失に戻して加算
train_loss += loss.item() * train_batch_size
n_train_acc += (predicted == labels).sum().item()
# 予測フェーズ
for inputs_test, labels_test in test_loader:
# 1バッチあたりのデータ件数
test_batch_size = len(labels_test)
# 1エポックあたりのデータ累積件数
n_test += test_batch_size
inputs_test = inputs_test.to(device)
labels_test = labels_test.to(device)
# 予測計算
outputs_test = net(inputs_test)
# 損失計算
loss_test = criterion(outputs_test, labels_test)
# 予測ラベル導出
predicted_test = torch.max(outputs_test, 1)[1]
# 平均前の損失と正解数の計算
# lossは平均計算が行われているので平均前の損失に戻して加算
val_loss += loss_test.item() * test_batch_size
n_val_acc += (predicted_test == labels_test).sum().item()
# 精度計算
train_acc = n_train_acc / n_train
val_acc = n_val_acc / n_test
# 損失計算
ave_train_loss = train_loss / n_train
ave_val_loss = val_loss / n_test
# 結果表示
print(f'Epoch [{epoch+1}/{num_epochs}], loss: {ave_train_loss:.5f}, acc: {train_acc:.5f}, val_loss: {ave_val_loss:.5f}, Val_acc: {val_acc:.5f}')
# 記録
item = np.array([epoch+1, ave_train_loss, train_acc, ave_val_loss, val_acc])
history = np.vstack((history, item))
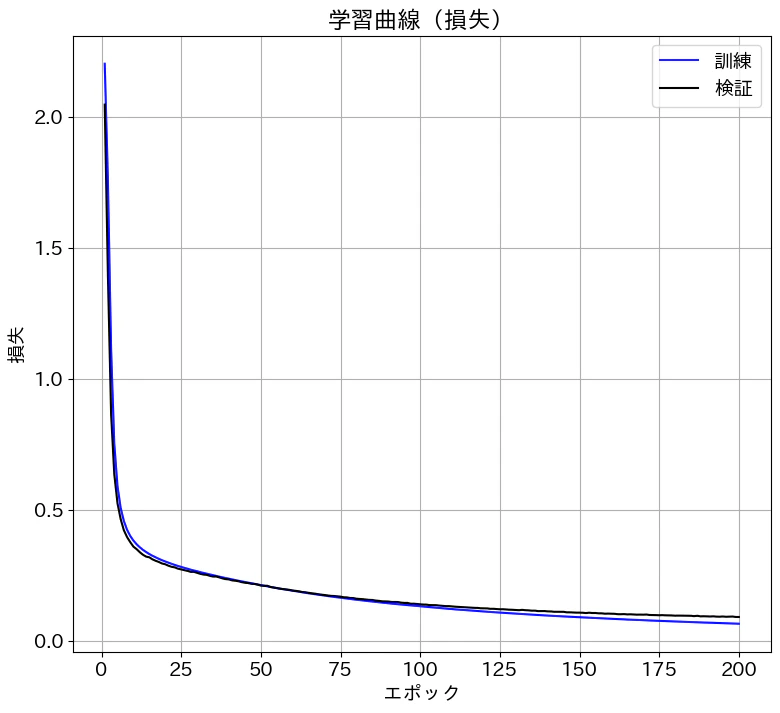
結果確認
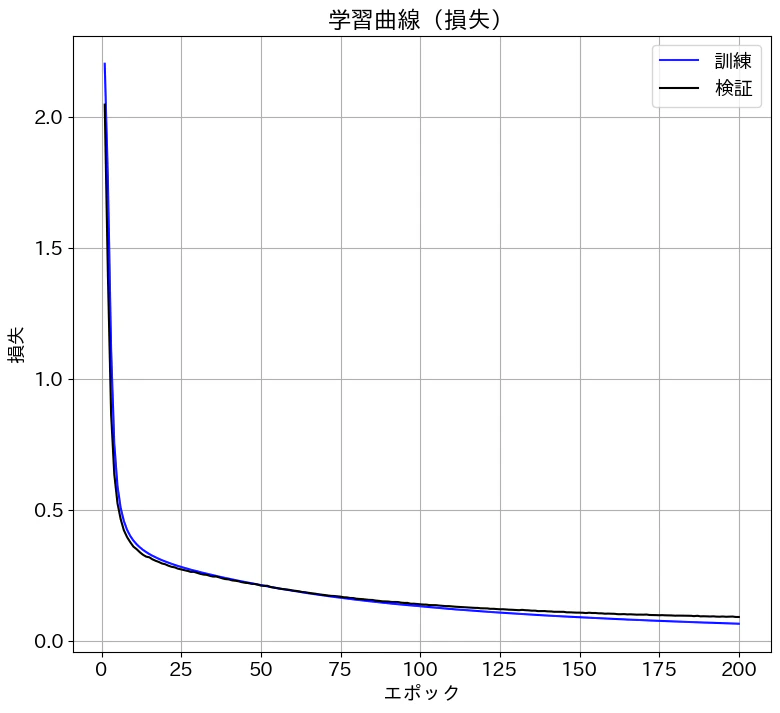
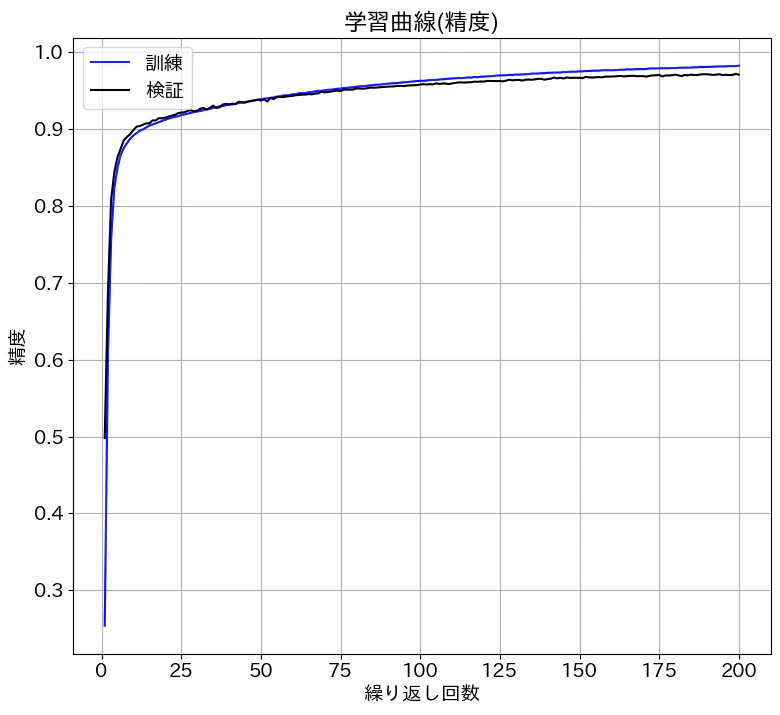
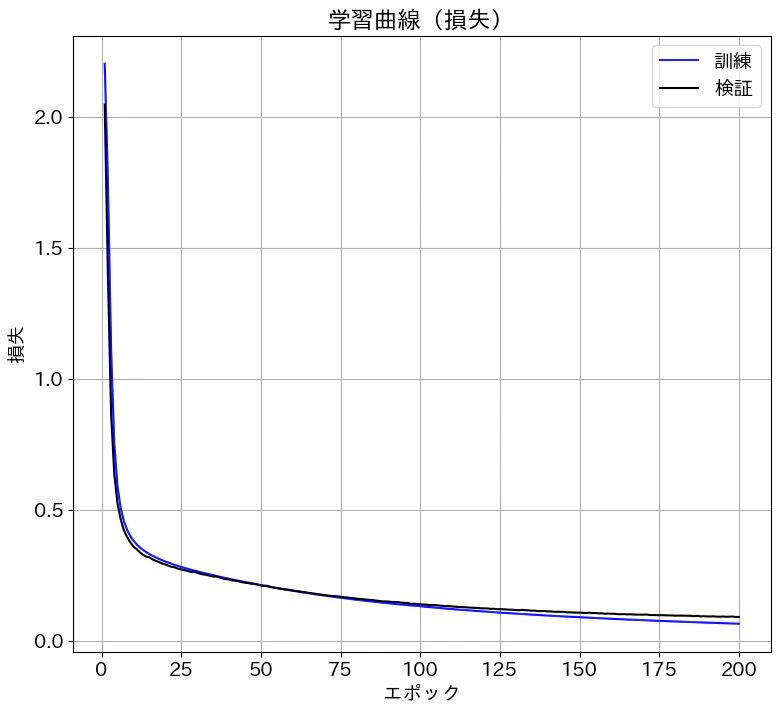
損失は0.09くらいまで減少し、精度は97%程度に到達しました。記事にはしていませんが、隠れ層が1層の場合は精度が95%くらいだったので、2層にすることで精度が向上しました。
# 損失と精度の確認
print(f'初期状態: 損失: {history[0,3]:.5f} 精度: {history[0,4]:.5f}' )
print(f'最終状態: 損失: {history[-1,3]:.5f} 精度: {history[-1,4]:.5f}' )
初期状態: 損失: 2.04576 精度: 0.49800
最終状態: 損失: 0.09027 精度: 0.97090
学習曲線も描画しておきます。
# 学習曲線の表示(損失)
plt.rcParams['figure.figsize'] = (9,8)
plt.plot(history[:,0], history[:,1], 'b', label='訓練')
plt.plot(history[:,0], history[:,3], 'k', label='検証')
plt.xlabel('エポック')
plt.ylabel('損失')
plt.title('学習曲線(損失)')
plt.legend()
plt.show()
# 学習曲線の表示 (精度)
plt.rcParams['figure.figsize'] = (9,8)
plt.plot(history[:,0], history[:,2], 'b', label='訓練')
plt.plot(history[:,0], history[:,4], 'k', label='検証')
plt.xlabel('繰り返し回数')
plt.ylabel('精度')
plt.title('学習曲線(精度)')
plt.legend()
plt.show()
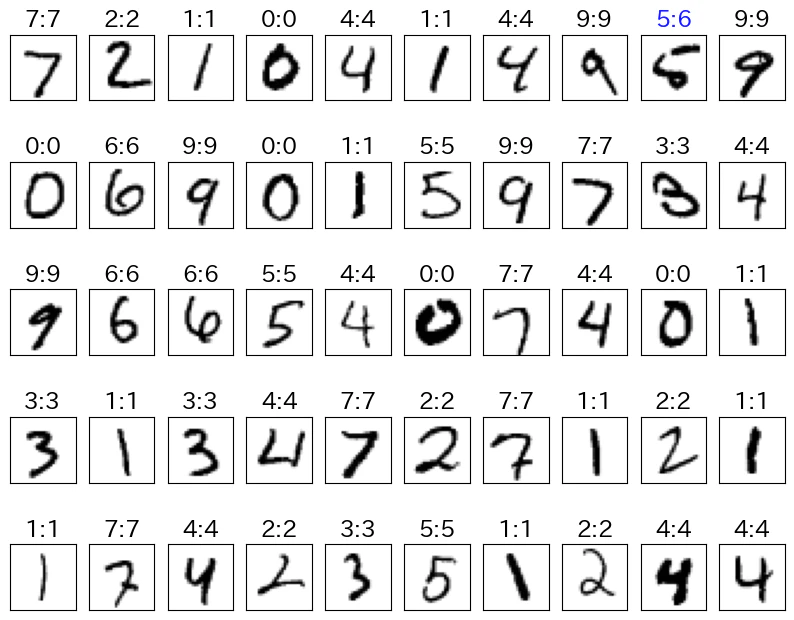
イメージ表示で確認
数字やグラフだけだと味気ないので、実際の画像を確認したいと思います。実際問題、現物を確認するとわかることもあるので、このプロセスはやっておいた方がよいと思います。
# DataLoaderから最初の1セットを取得する
for images, labels in test_loader:
break
# 予測結果の取得
inputs = images.to(device)
labels = labels.to(device)
outputs = net(inputs)
predicted = torch.max(outputs, 1)[1]
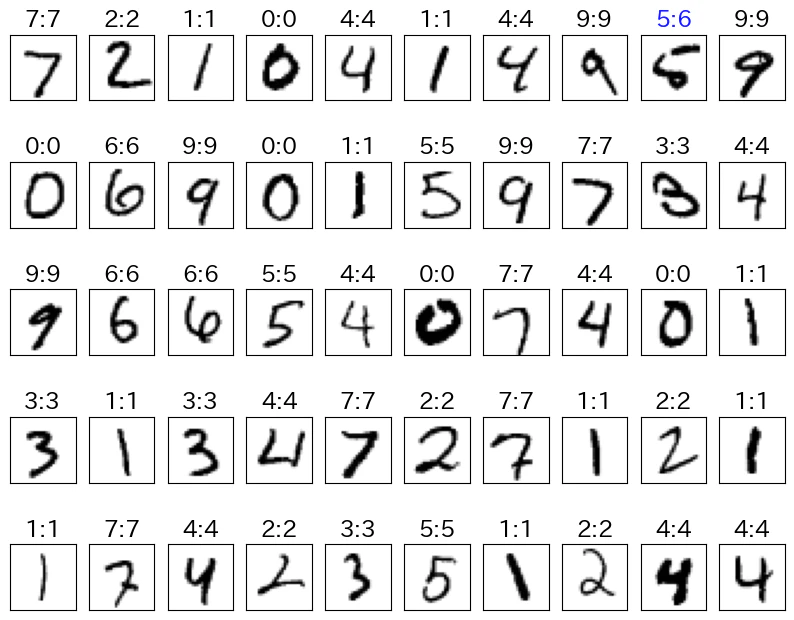
# 最初の50件でイメージを「正解値:予測値」と表示
plt.figure(figsize=(10, 8))
for i in range(50):
ax = plt.subplot(5, 10, i + 1)
# numpyに変換
image = images[i]
label = labels[i]
pred = predicted[i]
if (pred == label):
c = 'k'
else:
c = 'b'
# imgの範囲を[0, 1]に戻す
image2 = (image + 1)/ 2
# イメージ表示
plt.imshow(image2.reshape(28, 28),cmap='gray_r')
ax.set_title(f'{label}:{pred}', c=c)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
終わりに
- MNISTを対象に、2つの隠れ層を持ったニューラルネットワークを用いた多クラス分類モデルを実装しました。
- 精度は97%でした。
- 予測を間違えた画像を確認すると、ひとの目で見ても判断に迷うような文字でした。
- データローダーを使ったミニバッチ学習や、Transformsを使った前処理、tqdmを使ったプログレスバーの表示などの実践的なテクニックも実装できました。
出典