Goでリバースプロキシを作ったものの、そもそもリバースプロキシが何なのか、何で必要なのか分からなかったのでまとめてみた。
主に
[24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)
を勉強して、理解に必要そうなところだけ抽出した。
冗長化の必要性
冗長化とは、障害が発生しても予備の機材でシステムの機能を継続できるようにすること。
Webサービスでいえば、webサーバが1つ死んだり障害が発生したりしても、サービスには支障を出さずに運用を続行出来るようにすること。
システムを冗長化するとは、
- 障害を想定する
- 障害に備えて予備の機材を準備する
- 障害発生時に予備の機材に切り換えられる運用体勢を敷く
ことをいう。
予備機材を導入して障害に備える
先の冗長化の方法にあるように、予備機材を導入する。
これでwebサーバやルータに障害が発生しても、予備に切り換えることで運用を続行出来る。
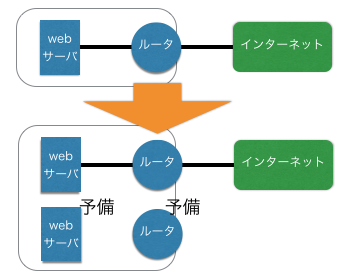
予備機材のスタンバイ方法は大きく2つある。
コールドスタンバイ
予備機材は普段電源を切って使わずにおいて、障害が発生した時に電源を入れて利用する方法。
予備機材は現用機材と同じ設定でないといけないため、頻繁に情報が更新されるwebサーバにはコールドスタンバイは向かない。
一方で、設定の変更が少ないルータにおいてはコールドスタンバイは実用的である。
ホットスタンバイ
予備の機材に常時電源を入れておいて、現用機材に更新が掛かると予備機材にも更新がかかるようにしておく方法。情報の更新が頻繁なwebサーバに有用。
これによって、現用機材と予備機材が常に同じ状態に保たれる。
待機させておくだと予備機材がもったいない!!
システムを冗長化できるのは良いけど、2倍の機材を使って1台分の能力を発揮させないのはもったいない。両方活用すれば処理能力も2倍になるはず。
そこで登場するのが負荷分散という考え方。
負荷分散
負荷分散とは、複数のサーバに処理を分散させて、全体としてのスケーラビリティを向上させること。
サーバを負荷分散構成にしておけば、後々処理が追いつかなくなっても、サーバを追加すればよくなる。
webサーバの冗長化
DNSロビン
DNSを使って複数のサーバに処理を分散させる手法。
複数の人がDNSにIPアドレスの問い合わせをした場合、DNSサーバはそれぞれに異なったIPアドレスを返すことで処理を分散する。
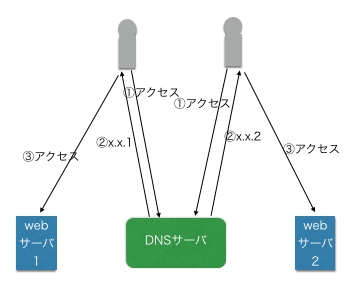
これは同じ名前に複数のレコードを登録すると、問い合わせの度に異なるIPアドレスを返す仕組みを利用している。
それゆえ複雑な実装をせずに簡単に負荷分散が出来る。
問題点
・サーバの数=グローバルアドレスの数
IPアドレスでサーバを区別しているので、用意したサーバの数だけグローバルアドレスが必要になる
・分散が偏る可能性がある
プロキシサーバ経由でDNSサーバにアクセスがあった場合、しばらくの間最初に返したIPアドレスをキャッシュにもつため、一つのIPアドレスに集中的に負荷が掛かる可能性がある。
・webサーバが落ちていてもアクセスが行く
DNSサーバはwebサーバの状態を踏まえてアクセスをコントロール出来ない。
元々障害対策がスタートだったのに本末転倒になる。
ロードバランサ
ロードバランサと呼ばれる負荷分散機を利用して、複数のサーバに処理を振り分ける方法。
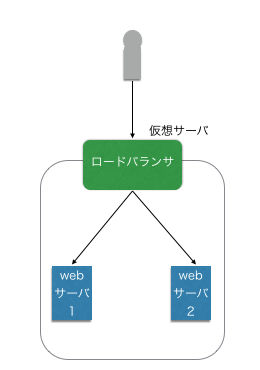
ロードバランサはグローバルアドレスをもった仮想サーバとして機能する。クライアントからのリクエストを本物のwebサーバに中継することで、あたかもロードバランサがwebサーバのように振る舞う。
メリット
・グローバルアドレスが節約出来る。
DNSラウンドロビンのようにグローバルアドレスをwebサーバごとに割り振る必要がなくなる。
・生きているwebサーバだけにアクセスがいく
ロードバランサは必ずヘルスチェック(webサーバが生きているか確認)してからwebサーバを選択するので、1台でも生きているwebサーバがある限り稼働する。
デメリット
・ロードバランサが高い。
・DNSラウンドロビンに比べ複雑なため、運用への不安から敬遠されがち。
ルータの冗長化
webサーバを冗長化しても、アクセスを振り分けるDNSサーバやロードバランサが死んだらサービスが機能しなくなってしまう。
そのためルータにも冗長化が必要で、そのための冗長化プロトコルがVRRP(Virtual Router Redundancy Protocol)である。
VRRPが作られたことで、ベンダに依存せずにルータの冗長化が行える。
気になる人は調べてみるといい。
リバースプロキシでさらに柔軟な負荷分散
DNSラウンドロビンやロードバランサでは、アクセスはルータが振り分けるものの、webサーバがリクエストに直接応答していた。
そこで、クライアントとwebサーバの間に立って要求を代理で処理するのがリバースプロキシである。
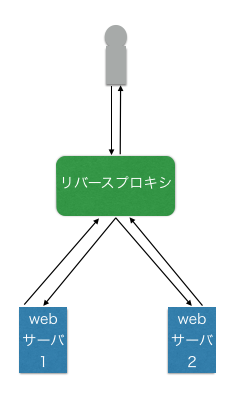
ロードバランサとの一番の違いは、webサーバはクライアントにではなくリバースプロキシに応答を返すこと。
リバースプロキシがクライアントに応答を返す。
何が嬉しいの?
リバースプロキシが間に挟まることで、様々な前後処理を施すことが出来る。
HTTPリクエストの内容に応じた制御が出来る
IPアドレスでフィルタリング出来る
特定のIPアドレスのみアクセスを許可したり、逆に悪意のあるホストからのアクセスを遮断することが出来る。
URLの書き換え
内部処理の問題で、URLの中に"?user=growsic&tag=cpan〜"のように情報が含まれ、URLが長くなってしまうことがある。
これを奇麗に見せたい場合、簡潔なURLをリバースプロキシでURLを分解してから、上記のようなURLに変換してwebサーバに転送する。
メモリ使用率の向上
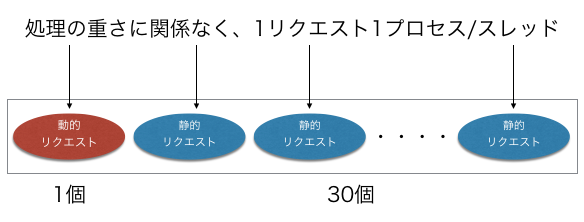
動的なwebページにアクセスすることを考えてみる。
最初の1リクエストで動的なコンテンツを要求する。(動的リクエスト)
そのページに画像が30枚入っていた場合、30リクエストが行われる(静的リクエスト)
すなわち、動的リクエスト1+静的リクエスト30が行われる。
この一連のwebページのリクエストを
全てAP(アプリケーション)サーバで対応する場合。
一般に動的リクエストの方が静的リクエストよりメモリを消費する。
しかし、処理の軽い静的リクエストにおいても1リクエスト1プロセス消費する。
APサーバで全て対応する場合、1つの動的リクエストを処理するためだけに31スレッド消費することになる。
APサーバだけ負荷が高くなり、全体としてのメモリ使用効率が下がる。
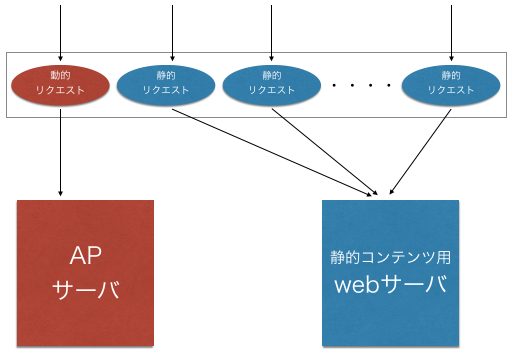
サーバを切り分ける
ここでリバースプロキシの出番。
URLを見て、
・静的コンテンツのパス以下に配置されていたらwebサーバに
・それ以外の場合は動的コンテンツの要求なのでAPサーバに
と振り分けることが出来る。
これによって、
・多数の静的コンテンツの要求はメモリ消費量の少ないWebサーバが応答して
・APサーバは動的コンテンツのみ応答する
と割り振ることが出来て、全体としてメモリ使用効率が上がり同時に処理出来るリクエストも増える。
キャッシュサーバの導入
HTTPはキャッシュしやすい
HTTPはステートレスなプロトコルで、ドキュメントは状態を持たないのでキャッシュしやすい。
HTTPにはプロトコルレベルでキャッシュの機能が組み込まれている。
多くのブラウザでは一度リクエストしたものはキャッシュし、2度目のアクセスではキャッシュを利用している。
更新されたか否かはHTTPヘッダーで更新日時を取得することで確認している。
もちろんリバースプロキシでも使える
ブラウザの例ではクライアントとサーバの間でのHTTPのキャッシュだったが、もちろんサーバとサーバの間でもHTTPのキャッシュが使える。
HTTP,HTTPS,FTPなどで利用されるオープンソースのキャッシュサーバとして、Squidがある。
SquidをHTTPで通信する2点の間に配置するとそのやり取りをキャッシュしてくれる。
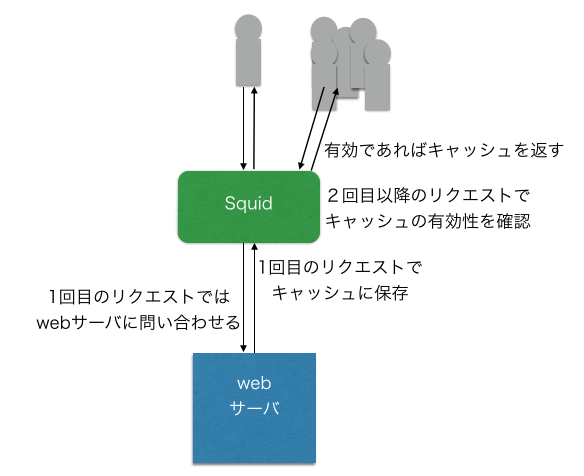
Squidをリバースプロキシで使う
リバースプロキシにキャッシュを用いた場合、キャッシュにはwebサーバからの応答を格納する。
2回目以降のアクセスがあった場合、HTTPヘッダからキャッシュの有効性を確認して、有効であればキャッシュを返す。
終わりに
具体的な実装や詳しい説明は、
[24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)
をおすすめします。