目次
1. はじめに
2. ファインチューニング手法概説
3. 各種ファインチューニング記事
4. おわりに
1. はじめに
Stable Diffusionとは、ダウンサンプリングファクター8のオートエンコーダーとパラメーター数 860M の U-Net および CLIP ViT-L/14 テキストエンコーダを Diffusion Models に用いたアーキテクチャを指します。
Stable Diffusion は、オンライン上の研究コミュニティである CompVisとLAION、そしてロンドンをベースとする AI 企業の Stability AIの合作として開発されました。オープンソースとして 2022 年 8 月に Hugging Faceで公開されています。
テキストから画像を簡単に生成できると話題になりました。

本記事では、Stable Diffusionに新しいデータを追加するファインチューニングの各種手法について概説をまとめ、それぞれを実行するために参考となる記事を集めました。筆者もStable Diffusion web UIといらすとやの画像でファインチューニングを試してみました。
2. ファインチューニング手法概説
Textual Inversion
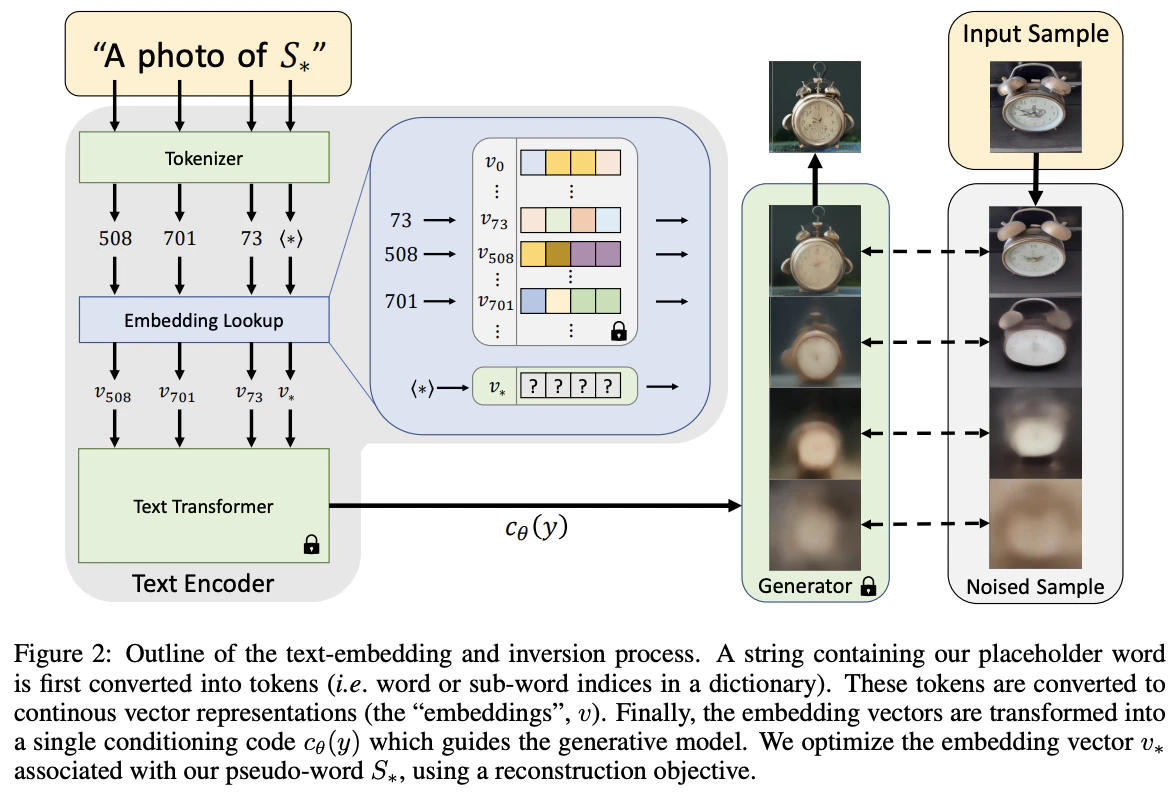
Textual Inversion1では、Text Encoder の埋め込み空間において、新しい「単語」を学習します。
図のテキストプロンプトの単語$S_*$が新しい単語です。この単語はトークナイザーに該当する単語がないため、埋め込み表現$v_*$もありません。
そこで、$v_*$を学習します。Textual Inversionでは新しい単語(≒テキストプロンプト)とその単語に対応する画像(=Input Sample)を入力します。Input Sampleを入力し、ノイズをかけてNoised Sampleにします。$S_*$を含むテキストプロンプトをText Transformerで特徴量$c_\theta(y)$に変換します。その際、$v_*$は適切に初期化しておきます。Noised Sampleを特徴量$c_\theta(y)$で条件づけて、Generatorで画像を生成し、これがInput Sampleに一致するようにバックプロパゲーションして$v_*$を学習します。
様々なプロンプトと画像のバリエーションで何度も(通常数千回)処理を行った後、学習された埋め込みは新しい概念の本質をとらえることができるはずです。
論文中では画像は5枚でうまくいくと記載されています。Textual Inversionの学習後に生成されるweightファイルサイズは100KB程度です。
Hypernetworks
Hypernetworks2はNovelAI3がStable Diffusion4の改造に使用した手法です。NovelAIの開発チームがブログ2で解説しています。
ネットワークの改造部分に言及している箇所は以下です。
After many iterations testing many different architectures, Aero was able to come up with one that is both performant and achieves high accuracy with varied dataset sizes. The hypernets are applied to the k and v vectors of CrossAttention layers in StableDiffusion, while not touching any other parts of the U-net. We found that the shallow attention layers overfit quickly with this approach, so we penalize those layers during training. This mostly mitigated the overfitting issue and results in better generalization at the end of training.
引用元: NovelAI Improvements on Stable Diffusion
Stable Diffusion(=Latent Diffusion Models)のU-netにはCross Attentionが含まれています。このCross AttentionのkeyベクトルとvalueベクトルにHypernetworkModuleと呼ばれる層を追加しています(Stable Diffusion web UI5の実装6から確認しました)。
つまり、Hypernetworksでは、元のStable Diffusionのweightをそのままに、新しく追加した層を学習することでファインチューニングを行っています。

Hypernetworksのレイヤー構造についてはこの記事が参考になります。
学習にはプロンプトテキストと画像を使用します。プロンプトテキストは画像を表す単語やタグから作成します。画像は数十枚でうまくいく場合もあるようです。Hypernetworksの学習後に生成されるweightファイルサイズは80MB程度です。
Dreambooth
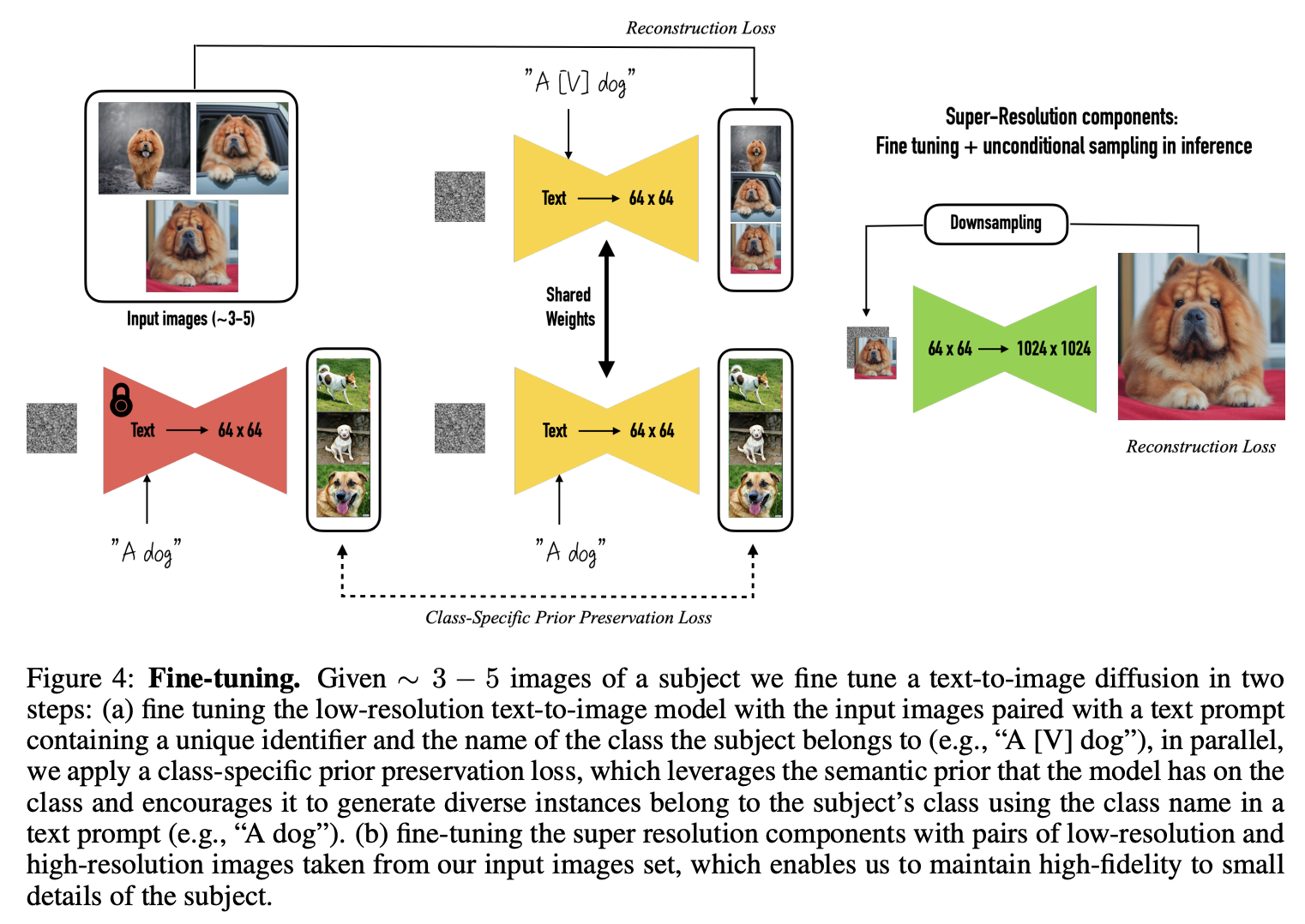
Dreambooth7はGoogleが発表したStable Diffusionのファインチューニング手法です。
(a) 入力画像と、一意な識別子(例:A)と被写体が属するクラス名(例:dog)を含むテキストプロンプト(例:A [V] dog)のペアで低解像度text-to-imageモデルをファインチューニングします。
この時、Loss関数にクラス固有のPrior-Preservation Lossを追加することで、オーバーフィットとlanguage driftに対処します。事前にクラスのテキストプロンプト(例:A dog)を入力して生成された画像を用意し、新しいテキストプロンプト(例:A [V] dog)で新しい画像が、事前のクラスのテキストプロンプト(例:A dog)で事前に生成した画像がそれぞれ生成されるようなLossを構成します。

(b) 入力画像から低解像度画像と高解像度画像のペアを用意し、超解像コンポーネントをファインチューニングします。これにより被写体の細かいディテールに忠実な画像生成を可能にします。
純粋なファインチューニング
Stabel DiffusionのネットワークのU-Netの部分のみファインチューニングします。
画像(数百枚以上)とキャプション(さらにはタグ)のペアを用意して学習を行います。
その他
いっぱいあって追いつけません。
3. 各種ファインチューニング記事
Stable Diffusion web UIを使用する方法
Textual inversion、Hypernetworks、DreamBoothはStable Diffusion web UIを使用して実行することができます。こちらのwikiが詳しいです。
上記の記事をgoogle colabで実行する際の注意点が記載されています。
上記の記事で、学習済みの.ptファイルの配置について記載がないので下記で補足。
Hypernetworksの設定チューニングの参考。
今回は以上記事を参考に、いらすとやでファインチューニングを試しました。Stable Diffusionはsd-v1-4.ckptを使用しました。いらすとやの画像は一人の人が写っている画像を25種類用意し、長辺が512pxになるようにリサイズ、短辺が512pxになるように白でパディングを実施しました。透過成分が不要なのでjpeg形式で保存しました。画像のタグはDanbooruタグを使用しています。環境はGoogle colab Proを使用しています。学習には両方とも7時間程度かかりました。
Textual inversionで生成した"Boy in space suit riding a horse"

Hypernetworksで生成した"Boy in space suit riding a horse"

Hypernetworksのほうが追加のネットワークがある分、良い感じです。
スクリプトやnotebookで実行する方法
Textual inversionの本家実装を使用した記事。
DreamBoothをgoogle colabで行う記事。
Diffusion Modelの純粋なファインチューニングをColabで実行できるプログラム。
以上記事は動作確認できていません。
4. おわりに
本記事ではStable Diffusion のファインチューニングの記事をまとめました。Stable Diffusion web UIを使用すれば非常に簡単にファインチューニング出来たので、みなさんも試してみてください。
その他参考にした記事
Textual Inversionの解説
Waifu Diffusionの訓練方法
壮大なまとめ記事
-
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or, "An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion", https://arxiv.org/abs/2208.01618 ↩
-
"NovelAI Improvements on Stable Diffusion", https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac ↩ ↩2
-
"NovelAI - The AI Storyteller", https://novelai.net/ ↩
-
"CompVis/stable-diffusion · Hugging Face", https://huggingface.co/CompVis/stable-diffusion ↩
-
"Stable Diffusion web UI", https://github.com/AUTOMATIC1111/stable-diffusion-webui ↩
-
https://github.com/AUTOMATIC1111/stable-diffusion-webui/blob/master/modules/hypernetworks/hypernetwork.py,
attention_CrossAttention_forward↩ -
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman, "DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation", https://arxiv.org/abs/2208.12242 ↩