はじめに
物体検出とは、画像内の物体を特定し、それを囲む矩形の位置を見つける技術です。物体検出における一般的なアプローチには、"one-stage"と"two-stage"の2つの主要な種類があります。Faster R-CNNのような「二段階物体検出器」では、まず物体があるかもしれない場所をざっくりと見つけて、その後でそれぞれの場所を詳しく分析します。「一段階物体検出器」では、画像のすべての場所を同時に分析します。この方法は速くてシンプルですが、2017年当時は、二段階のアプローチの精度は超えられていませんでした。
- One-Stage (一段階) 物体検出器
- 直接的: 画像を入力として受け取り、物体のクラスと位置を同時に予測します。
- 高速: シンプルなアーキテクチャのため、リアルタイムや近いパフォーマンスが必要な場面でよく使用されます。
- 例: YOLO (You Only Look Once)、SSD (Single Shot Multibox Detector) 等。
- 制約: 一般的には、精度の面でtwo-stageの検出器に劣ることが多い。
- Two-Stage (二段階) 物体検出器
- ステップ1 (領域提案): 画像の中から物体が存在する可能性のある領域(Region Proposals)を識別します。
- ステップ2 (クラス分類と境界ボックス調整): 第一段階で提案された領域を対象として、具体的な物体のクラスを特定し、境界ボックスの位置をさらに精緻化します。
- 高精度: 緻密なステップを踏むため、一般的に高い検出精度を持っています。
- 例: R-CNN、Fast R-CNN、Faster R-CNN など。
- 制約: 複雑なアーキテクチャのため、処理速度が一段階の検出器よりも遅いことが多い。
これらの検出器はそれぞれの利点と制約があり、使用シナリオや要件に応じて選択されます。

図引用元:https://arxiv.org/abs/1905.05055
RetinaNetは、2017年にT.-Y. Linらによって提案された物体検出モデルです。一段階物体検出器は、その高速性と簡便性にもかかわらず、長年二段階物体検出器の精度を下回っていました。T.-Y. Linらはこの問題の背後にある理由を探求しました。
彼らが発見したのは、密な検出器のトレーニング中に遭遇する前景-背景のクラスの極端な不均衡が主な原因であるということでした。これを解決するため、標準的なクロスエントロピー損失を見直し、トレーニング中に困難な、誤分類された例に焦点を当てるようにする新しい損失関数、「Focal Loss」をRetinaNetに導入しました。Focal Lossのおかげで、一段階物体検出器は非常に高い検出速度を保ちつつ、二段階物体検出器と同等の精度を達成することができました。
RetinaNetの主要な特徴は以下です。
- 一段階の物体検出アプローチ
- Feature Pyramid Network
- 単一の解像度の入力画像から効率的にリッチで多スケールの特徴ピラミッドを構築。
- Focal Loss
- 極端な前景・背景のクラスの不均衡への対策として「Focal Loss」を導入。
RetinaNetのアーキテクチャ
まず、RetinaNetのネットワークアーキテクチャを下図に示します。
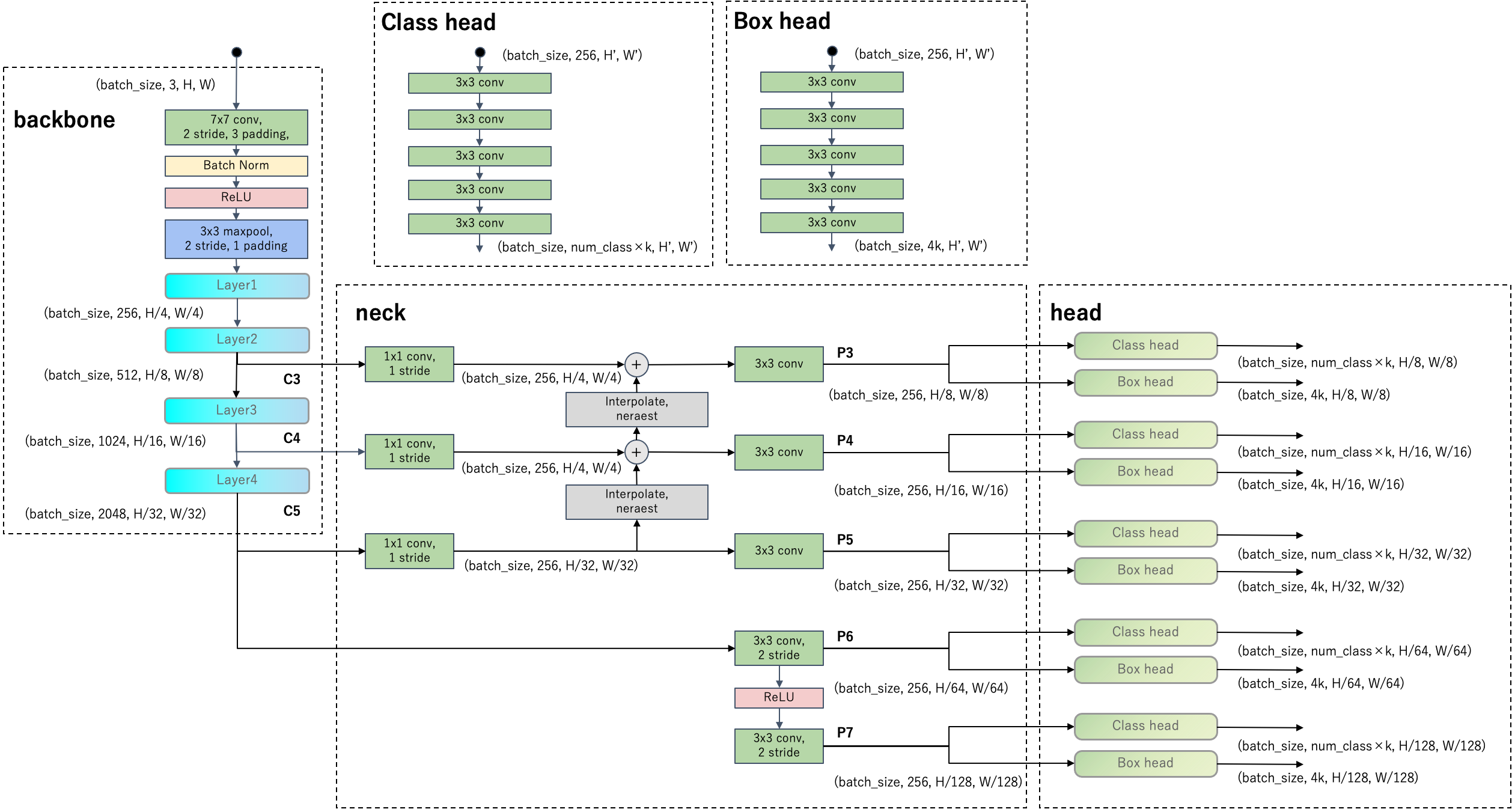
RetinaNetのネットワークはbackbone、neck、headで構成されています。headの点線部のClass headとBox headは全て重み共有しています。backboneはResNet-50を想定しています。
以下ではRetinaNetの主要な特徴に注目してRetinaNetの構造に迫ります。二段階物体検出器であるFaster R-CNNと比較して見ていきますので、前回記事も参考にしてください。
一段階の物体検出アプローチ
RetinaNetは一段階物体検出器です。Faster R-CNNと比較すると、RetinaNetはRegion Proposal Network(RPN)を強化して、後段を排除したという見方が出来ると思います。
RetinaNetのネットワークアーキテクチャ図を見ると複雑ですが、予測自体はFaster R-CNNのRPNと同じです。まず、図のレベルP5の部分のみ注目します。レベルP5から伸びるheadにはクラス分類とバウンディングボックスのオフセット回帰モジュールがあります。レベルP5の解像度は$(H/32, W/32)$であり、これをグリッドとみなしてアンカーを用意します。アンカーはRPNと同様に1グリッドにつきk=(スケール×アスペクト比)のアンカーがあります。正解バウンディングボックスと照らし合わせてアンカーをラベルします。
- 各アンカーと各バウンディングボックスのIoUを計算します。
- それぞれのアンカーに対して次の操作をします。IoUが0より大きい正解バウンディングボックスが1つ以上存在する場合、IoUが最も大きい正解バウンディングボックスを1つ選択し、次のパターンに応じてアンカーをラベル付けします。
- 正解バウンディングボックスとIoUが0.5以上のものを前景アンカーとしてラベルします。
- 正解バウンディングボックスとIoUが0.4未満のものを背景アンカーとしてラベルします。
- IoUが0.4以上0.5未満のものは前景とも背景ともいえないので、無視アンカーとしてラベルします。
- IoUが0より大きい正解バウンディングボックスが存在しない場合は、背景アンカーとしてラベルします。
- 以上の操作で前景アンカーとしてラベルしたアンカーに対しては、対応する正解バウンディングボックスを紐づけておきます。背景アンカー、無視アンカーとしてラベルされたアンカーに対しては、正解バウンディングボックスはありませんが、実装上は後続の処理と統一的に処理したいため、ダミーのバウンディングボックスを作成して紐づけておきます。
- torchvisionの実装では、正解バウンディングボックスのうち、アンカーに紐づいていないものは、まだ紐づきがないアンカーのうちIoUが最も大きくなるものに紐づけ、前景アンカーとしてラベルします(
set_low_quality_matches_)。つまり、正解バウンディングボックスは必ず1つのアンカーと紐づきます。
RPNと異なるのは、RPNの分類モジュールが物体かどうかの二値分類をしていたのに対し、RetinaNetのクラス分類モジュールでは、予測バウンディングボックスの物体が各クラスに所属するかどうかの、各クラスに対する二値分類(多ラベル分類)になっていることです。アンカーのサンプリングをせず、前景アンカーと背景アンカー(から予測する予測バウンディングボックス)を全て学習に使用するので、クラス分類は前景と背景が著しく不均衡になります。
回帰モジュールではFaster R-CNNと同様、アンカーからのオフセットを予測します。損失関数にはSmooth L1 Lossを使用します。前景アンカー(から予測する予測バウンディングボックス)のみ損失計算に使用します。
Feature Pyramid Network
backboneの異なる解像度の特徴マップを取り出すことで、単一の解像度の入力画像から多スケールの特徴マップを抽出しています。
注目すべき点は、深い層の特徴を浅い層の特徴に加えて、大きな解像度の特徴マップを強化している点です。アーキテクチャ図を見ると、特徴マップC5をアップサンプリングしてレベルP4、P3を出力していることが分かります。このようにすることで、深い層で得た詳細な特徴を解像度の大きい特徴マップにも反映させ、リッチな特徴を生成しています。
Feature Pyramid NetworkからはレベルP3〜P7の5つの特徴マップを抽出し、上記で説明したように各特徴マップに対しアンカーを生成してクラス分類とアンカーからのオフセットを予測します。headはピラミッドのレベルで共有して使いまわします。
Focal Loss
T.-Y. Linらは、クラス分類に対して"Focal Loss"という名前の新しい損失関数を提案しています。
\text{Focal Loss} = - (1 - p_t)^\gamma \log(p_t)
ここで、$p_t$はそのクラスに予測された確率であり、$\gamma$は新しく導入された調整可能なパラメータです。$\gamma=0$でクロスエントロピーに一致します。下図は横軸に$p_t$、縦軸にlossの値をとったグラフです。
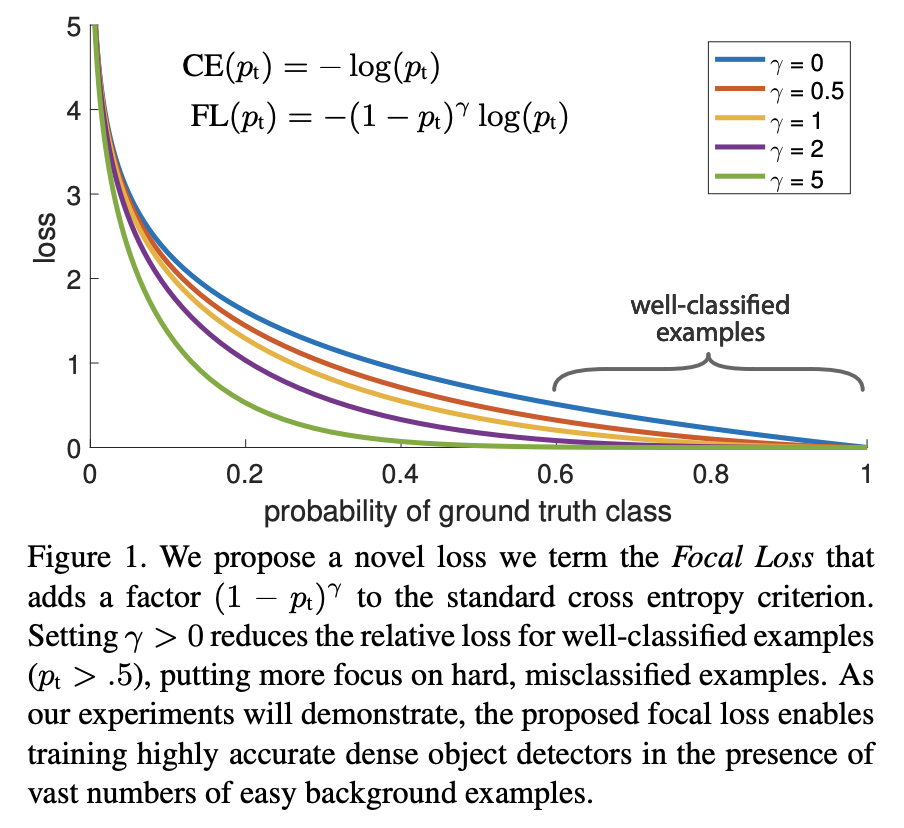
$\gamma > 0$の場合、$p_t > 0.5$の領域で、クロスエントロピーよりも値が小さいことが分かります。つまり、Focal Lossを使用することで、簡単に$p_t > 0.5$に予測されるようなサンプルはlossへの影響が小さくなり、誤分類される難しいサンプルがlossを支配するようになります。
この新しい損失関数の導入により、多数の簡単な背景の例の中で、高精度な密1な物体検出器を訓練することができます。要するに、Focal Lossは、物体検出の訓練中に多数存在する簡単な背景サンプルによってモデルが圧倒されるのを防ぎながら、難しいサンプルに焦点を当てるための新しい損失関数になっています。
実装例
"""
Licensed under the Apache License, Version 2.0 (the "License")
https://github.com/keras-team/keras-io/blob/master/LICENSE
Copyright (c) Soumith Chintala 2016,
All rights reserved.
https://github.com/pytorch/vision/blob/main/LICENSE
Copyright (c) ground0state 2023
"""
import json
import math
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
from torchvision.models import resnet50
from torchvision.ops import boxes as box_ops
from torchvision.ops import nms
from torchvision.transforms.functional import to_tensor
def convert_to_corners(boxes):
"""Changes the box format to corner coordinates
Arguments:
boxes: A tensor of rank 2 or higher with a shape of `(..., num_boxes, 4)`
representing bounding boxes where each box is of the format
`[x, y, width, height]`.
Returns:
converted boxes with shape same as that of boxes.
"""
return torch.cat(
[boxes[..., :2] - boxes[..., 2:] / 2.0,
boxes[..., :2] + boxes[..., 2:] / 2.0],
dim=-1,
)
def compute_iou(boxes1, boxes2):
"""Computes pairwise IOU matrix for given two sets of boxes
Arguments:
boxes1: A tensor with shape `(N, 4)` representing bounding boxes
where each box is of the format `[x, y, width, height]`.
boxes2: A tensor with shape `(M, 4)` representing bounding boxes
where each box is of the format `[x, y, width, height]`.
Returns:
pairwise IOU matrix with shape `(N, M)`, where the value at ith row
jth column holds the IOU between ith box and jth box from
boxes1 and boxes2 respectively.
"""
boxes1_corners = convert_to_corners(boxes1)
boxes2_corners = convert_to_corners(boxes2)
lu = torch.max(boxes1_corners[:, None, :2], boxes2_corners[:, :2])
rd = torch.min(boxes1_corners[:, None, 2:], boxes2_corners[:, 2:])
intersection = torch.clamp(rd - lu, min=0.0)
intersection_area = intersection[:, :, 0] * intersection[:, :, 1]
boxes1_area = boxes1[:, 2] * boxes1[:, 3]
boxes2_area = boxes2[:, 2] * boxes2[:, 3]
union_area = torch.clamp(
boxes1_area[:, None] + boxes2_area - intersection_area, min=1e-8
)
return torch.clamp(intersection_area / union_area, 0.0, 1.0)
def visualize_detections(
image, boxes, classes, scores, figsize=(7, 7), linewidth=1, color=[0, 0, 1]
):
"""Visualize Detections"""
image = np.array(image, dtype=np.uint8)
plt.figure(figsize=figsize)
plt.axis("off")
plt.imshow(image)
ax = plt.gca()
for box, _cls, score in zip(boxes, classes, scores):
text = "{}: {:.2f}".format(_cls, score)
x1, y1, x2, y2 = box
w, h = x2 - x1, y2 - y1
patch = plt.Rectangle(
[x1, y1], w, h, fill=False, edgecolor=color, linewidth=linewidth
)
ax.add_patch(patch)
ax.text(
x1,
y1,
text,
bbox={"facecolor": color, "alpha": 0.4},
clip_box=ax.clipbox,
clip_on=True,
)
plt.show()
return ax
class AnchorBox:
"""Generates anchor boxes.
This class has operations to generate anchor boxes for feature maps at
strides `[8, 16, 32, 64, 128]`. Where each anchor each box is of the
format `[x, y, width, height]`.
Attributes:
aspect_ratios: A list of float values representing the aspect ratios of
the anchor boxes at each location on the feature map
scales: A list of float values representing the scale of the anchor boxes
at each location on the feature map.
num_anchors: The number of anchor boxes at each location on feature map
areas: A list of float values representing the areas of the anchor
boxes for each feature map in the feature pyramid.
strides: A list of float value representing the strides for each feature
map in the feature pyramid.
"""
def __init__(self):
self.aspect_ratios = [0.5, 1.0, 2.0]
self.scales = [2 ** x for x in [0, 1 / 3, 2 / 3]]
self._num_anchors = len(self.aspect_ratios) * len(self.scales)
# 各ストライドは、該当するピラミッドレベルの特徴マップの1ピクセルが、
# 元の画像において何ピクセル分に相当するかを示しています。
# [8, 16, 32, 64, 128]
self._strides = [2 ** i for i in range(3, 8)]
# これはフィーチャーピラミッドの各レベルでのアンカーボックスの基本面積を示しています。
self._areas = [x ** 2 for x in [32.0, 64.0, 128.0, 256.0, 512.0]]
# フィーチャーピラミッドの各レベルでのアンカーボックスの寸法(幅と高さ)のリストを含んでいます。
self._anchor_dims = self._compute_dims()
def _compute_dims(self):
"""Computes anchor box dimensions for all ratios and scales at all levels
of the feature pyramid.
"""
anchor_dims_all = []
for area in self._areas:
anchor_dims = []
for ratio in self.aspect_ratios:
anchor_height = torch.sqrt(torch.tensor(area / ratio))
anchor_width = area / anchor_height
dims = torch.reshape(
torch.stack([anchor_width, anchor_height],
dim=-1), [1, 1, 2]
)
for scale in self.scales:
anchor_dims.append(scale * dims)
anchor_dims_all.append(torch.stack(anchor_dims, dim=-2))
return anchor_dims_all
def _get_anchors(self, feature_height, feature_width, level):
"""Generates anchor boxes for a given feature map size and level
Arguments:
feature_height: An integer representing the height of the feature map.
feature_width: An integer representing the width of the feature map.
level: An integer representing the level of the feature map in the
feature pyramid.
Returns:
anchor boxes with the shape
`(feature_height * feature_width * num_anchors, 4)`
"""
rx = torch.arange(feature_width, dtype=torch.float32) + 0.5
ry = torch.arange(feature_height, dtype=torch.float32) + 0.5
centers = torch.stack(torch.meshgrid(
ry, rx), dim=-1) * self._strides[level - 3]
centers = centers.unsqueeze(-2)
centers = torch.tile(centers, dims=(1, 1, int(self._num_anchors), 1))
dims = torch.tile(
self._anchor_dims[level - 3],
dims=(int(feature_height), int(feature_width), 1, 1))
anchors = torch.cat([centers, dims], dim=-1)
return anchors.view(feature_height * feature_width * self._num_anchors, 4)
def get_anchors(self, image_height, image_width):
"""Generates anchor boxes for all the feature maps of the feature pyramid.
Arguments:
image_height: Height of the input image.
image_width: Width of the input image.
Returns:
anchor boxes for all the feature maps, stacked as a single tensor
with shape `(total_anchors, 4)`
"""
anchors = [
self._get_anchors(
math.ceil(image_height / 2 ** i),
math.ceil(image_width / 2 ** i),
i,
)
for i in range(3, 8)
]
return torch.cat(anchors, dim=0)
def get_backbone():
"""Builds ResNet50 with pre-trained imagenet weights in PyTorch"""
original_backbone = resnet50(pretrained=True)
# Remove the average pooling and fully connected layers
# (the equivalent of "include_top=False" in Keras)
backbone = nn.Sequential(*list(original_backbone.children())[:-2])
# Extract specific layers' outputs (feature maps)
def forward(x):
x = original_backbone.conv1(x)
x = original_backbone.bn1(x)
x = original_backbone.relu(x)
x = original_backbone.maxpool(x)
x1 = original_backbone.layer1(x)
x2 = original_backbone.layer2(x1)
x3 = original_backbone.layer3(x2)
x4 = original_backbone.layer4(x3)
# Here, we return the outputs from the 3rd, 4th, and 5th layers
# of the ResNet just like in the Keras version
return x2, x3, x4
backbone.forward = forward
return backbone
class FeaturePyramid(nn.Module):
"""Builds the Feature Pyramid with the feature maps from the backbone.
Attributes:
backbone: The backbone to build the feature pyramid from.
Currently supports ResNet50 only.
"""
def __init__(self, backbone=None):
super(FeaturePyramid, self).__init__()
self.backbone = backbone if backbone else get_backbone()
self.conv_c3_1x1 = nn.Conv2d(
512, 256, kernel_size=1, stride=1, padding=0)
self.conv_c4_1x1 = nn.Conv2d(
1024, 256, kernel_size=1, stride=1, padding=0)
self.conv_c5_1x1 = nn.Conv2d(
2048, 256, kernel_size=1, stride=1, padding=0)
self.conv_c3_3x3 = nn.Conv2d(
256, 256, kernel_size=3, stride=1, padding=1)
self.conv_c4_3x3 = nn.Conv2d(
256, 256, kernel_size=3, stride=1, padding=1)
self.conv_c5_3x3 = nn.Conv2d(
256, 256, kernel_size=3, stride=1, padding=1)
self.conv_c6_3x3 = nn.Conv2d(
2048, 256, kernel_size=3, stride=2, padding=1)
self.conv_c7_3x3 = nn.Conv2d(
256, 256, kernel_size=3, stride=2, padding=1)
def forward(self, x):
c3_output, c4_output, c5_output = self.backbone(x)
p3_output = self.conv_c3_1x1(c3_output)
p4_output = self.conv_c4_1x1(c4_output)
p5_output = self.conv_c5_1x1(c5_output)
p4_output = p4_output + \
F.interpolate(p5_output, scale_factor=2, mode="nearest")
p3_output = p3_output + \
F.interpolate(p4_output, scale_factor=2, mode="nearest")
p3_output = self.conv_c3_3x3(p3_output)
p4_output = self.conv_c4_3x3(p4_output)
p5_output = self.conv_c5_3x3(p5_output)
p6_output = self.conv_c6_3x3(c5_output)
p7_output = self.conv_c7_3x3(F.relu(p6_output))
return p3_output, p4_output, p5_output, p6_output, p7_output
class Head(nn.Module):
"""
Constructs the class/box predictions head.
This head consists of 4 repeated layers each with 256 filters followed by a ReLU activation.
The final layer has a specified number of output filters.
Attributes:
- output_filters (int): Number of convolution filters in the final layer.
- bias_init (float): Initializer for the bias of the final convolution layer.
Usage:
model = Head(output_filters=9, bias_init=-4.6)
output = model(input_tensor)
"""
def __init__(self, out_channels, bias_init):
super(Head, self).__init__()
# kernel_init is equivalent to tf.initializers.RandomNormal(0.0, 0.01)
kernel_init = nn.init.normal_
# Define the four repeated layers
self.convs = nn.ModuleList()
for _ in range(4):
conv = nn.Conv2d(256, 256, 3, padding=1)
# Apply the kernel initializer
kernel_init(conv.weight, mean=0.0, std=0.01)
self.convs.append(conv)
# Define the final layer
self.final_conv = nn.Conv2d(256, out_channels, 3, padding=1)
# Apply the kernel initializer
kernel_init(self.final_conv.weight, mean=0.0, std=0.01)
# Apply the bias initializer
nn.init.constant_(self.final_conv.bias, bias_init)
def forward(self, x):
for conv in self.convs:
x = F.relu(conv(x))
x = self.final_conv(x)
return x
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
"""
input (Tensor) - Tensor of arbitrary shape as unnormalized scores (often referred to as logits).
target (Tensor) - Tensor of the same shape as input with values between 0 and 1
"""
BCE_loss = F.binary_cross_entropy_with_logits(
inputs, targets, reduction='none')
pt = torch.exp(-BCE_loss) # pt = p if y=1, pt = 1-p if y=0
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduction == 'mean':
return torch.mean(F_loss)
elif self.reduction == 'sum':
return torch.sum(F_loss)
else:
return F_loss
class RetinaNet(nn.Module):
def __init__(
self,
num_classes,
backbone=None,
score_thresh=0.0,
nms_thresh=0.5,
max_detections_per_class=100,
max_detections=100,
box_variance=[0.1, 0.1, 0.2, 0.2],
):
super().__init__()
self.fpn = FeaturePyramid(backbone)
self.num_classes = num_classes
self.score_thresh = score_thresh
self.nms_thresh = nms_thresh
self.max_detections_per_class = max_detections_per_class
self.max_detections = max_detections
self._box_variance = torch.tensor(
box_variance, dtype=torch.float32
)
self._anchor_box = AnchorBox()
self._num_anchors = self._anchor_box._num_anchors
self.cls_head = Head(self._num_anchors *
num_classes, -4.5951)
self.box_head = Head(self._num_anchors * 4, 0)
self._clf_loss = FocalLoss()
self._box_loss = nn.SmoothL1Loss()
self.label_encoder = LabelEncoder()
def forward(self, images, targets=None):
# get the original image sizes
original_image_sizes = []
for img in images:
val = img.shape[-2:]
torch._assert(
len(val) == 2,
f"expecting the last two dimensions of the Tensor to be H and W instead got {img.shape[-2:]}",
)
original_image_sizes.append((val[0], val[1]))
images = self.transform_batch_images(images)
features = self.fpn(images)
N = images.size()[0]
cls_outputs = []
box_outputs = []
for feature in features:
box_outputs.append(self.box_head(feature).view(N, -1, 4))
cls_outputs.append(
self.cls_head(feature).view(N, -1, self.num_classes))
cls_outputs = torch.cat(cls_outputs, dim=1)
box_outputs = torch.cat(box_outputs, dim=1)
head_outputs = {"cls_logits": cls_outputs,
"bbox_regression": box_outputs}
if self.training:
gt_boxes = targets["gt_boxes"]
cls_ids = targets["cls_ids"]
batch_images, labels = self.label_encoder.encode_batch(
images, gt_boxes, cls_ids)
loss = self.compute_loss(labels, head_outputs)
return loss
else:
detections = self.postprocess_detections(
images, head_outputs
)
detections = self.postprocess(
detections, original_image_sizes)
return detections
def transform_batch_images(self, images, size_divisible: int = 128):
"""
images: List[Tensor]
"""
def max_by_axis(the_list):
maxes = the_list[0]
for sublist in the_list[1:]:
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
return maxes
max_size = max_by_axis([list(img.shape) for img in images])
stride = float(size_divisible)
max_size = list(max_size)
max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride)
max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride)
batch_shape = [len(images)] + max_size
batched_imgs = images[0].new_full(batch_shape, 0)
for i in range(batched_imgs.shape[0]):
img = images[i]
batched_imgs[i, : img.shape[0],
: img.shape[1], : img.shape[2]].copy_(img)
return batched_imgs
def clip_boxes_to_image(self, boxes, original_image_size):
"""
Adjust bounding boxes to ensure they are within the boundaries of the original image.
Args:
- boxes (torch.Tensor): A tensor of shape (N, 4) representing N bounding boxes.
Each box is represented by (x_min, y_min, x_max, y_max).
- original_image_size (tuple): A tuple (height, width) representing the original image size.
Returns:
- torch.Tensor: A tensor of shape (N, 4) representing the adjusted bounding boxes.
"""
# Extract height and width from original_image_size
height, width = original_image_size
# Clip box coordinates to image boundaries
boxes[:, 0].clamp_(min=0, max=width)
boxes[:, 1].clamp_(min=0, max=height)
boxes[:, 2].clamp_(min=0, max=width)
boxes[:, 3].clamp_(min=0, max=height)
return boxes
def postprocess(self, detections, original_image_sizes):
for i, (pred, o_im_s) in enumerate(zip(detections, original_image_sizes)):
boxes = pred["boxes"]
boxes = self.clip_boxes_to_image(boxes, o_im_s)
detections[i]["boxes"] = boxes
return detections
def compute_loss(self, labels, head_outputs):
total_loss = 0
cls_logits = head_outputs["cls_logits"]
bbox_regression = head_outputs["bbox_regression"]
for i, label in enumerate(labels):
cls_logits_per_image = cls_logits[i]
bbox_regression_per_image = bbox_regression[i]
positive_mask = (label[:, 4] > -1.0).tolist()
valid_mask = (label[:, 4] != -2.0).tolist()
cls_label = torch.zeros(
(label[:, 4].shape[0], self.num_classes),
dtype=torch.float32)
cls_label[positive_mask] = F.one_hot(
label[positive_mask, 4].long(),
num_classes=self.num_classes
).float()
box_label = label[:, :4].to(dtype=torch.float32)
_cls_loss = self._clf_loss(
cls_logits_per_image[valid_mask],
cls_label[valid_mask])
_box_loss = self._box_loss(
bbox_regression_per_image[positive_mask],
box_label[positive_mask])
total_loss += _cls_loss + _box_loss
return total_loss
def _decode_box_predictions(self, anchor_boxes, box_predictions):
boxes = box_predictions * self._box_variance[None, None, :]
boxes = torch.cat(
[
boxes[..., :2] * anchor_boxes[..., 2:] + anchor_boxes[..., :2],
torch.exp(boxes[..., 2:]) * anchor_boxes[..., 2:],
],
dim=-1,
)
boxes_transformed = box_ops.box_convert(
boxes, in_fmt="cxcywh", out_fmt="xyxy")
return boxes_transformed
def postprocess_detections(self, images, head_outputs):
image_shape = torch.tensor(images.shape[-2:], dtype=torch.float32)
anchor_boxes = self._anchor_box.get_anchors(
image_shape[0], image_shape[1])
box_predictions = head_outputs["bbox_regression"]
cls_predictions = torch.sigmoid(head_outputs["cls_logits"])
boxes = self._decode_box_predictions(
anchor_boxes[None, ...], box_predictions)
detections = []
for boxes_per_image, scores_per_image in zip(boxes, cls_predictions):
# Flatten predictions for NMS
boxes_per_image = boxes_per_image.view(-1, 4)
scores_per_image = scores_per_image.view(-1, self.num_classes)
out = {
"boxes": [],
"labels": [],
"scores": []
}
# For each class, keep only the detections above the confidence threshold and apply NMS
for class_idx in range(self.num_classes):
class_scores = scores_per_image[:, class_idx]
# Filter based on confidence threshold
mask = class_scores > self.score_thresh
class_boxes = boxes_per_image[mask]
class_scores = class_scores[mask]
# Skip the class if no boxes meet the confidence threshold
if class_boxes.shape[0] == 0:
continue
# Apply NMS
keep = nms(class_boxes, class_scores, self.nms_thresh)
# Sort the detections by score and keep the top self.max_detections_per_class
_, sorted_indices = class_scores[keep].sort(descending=True)
top_indices = sorted_indices[:self.max_detections_per_class]
keep = keep[top_indices]
out["boxes"].append(class_boxes[keep])
out["labels"].append(torch.full(
(len(keep),), class_idx, dtype=torch.int64))
out["scores"].append(class_scores[keep])
# After processing all classes, keep only the top scoring boxes across all classes
all_scores = torch.cat(out["scores"])
_, sorted_idx = all_scores.sort(descending=True)
sorted_idx = sorted_idx[:self.max_detections]
# Correct indexing for tensors
out["boxes"] = torch.cat(out["boxes"])[sorted_idx]
out["labels"] = torch.cat(out["labels"])[sorted_idx]
out["scores"] = all_scores[sorted_idx]
detections.append(out)
return detections
def random_flip_horizontal(image, boxes):
"""Flips image and boxes horizontally with 50% chance
Arguments:
image: A 3-D numpy array of shape `(height, width, channels)` representing an
image.
boxes: A numpy array with shape `(num_boxes, 4)` representing bounding boxes,
with coordinates in pixel values (x_min, y_min, x_max, y_max).
Returns:
Randomly flipped image and boxes
"""
if np.random.rand() < 0.5:
# Flip image
image = image[:, ::-1, :]
# Flip x-coordinates of boxes based on the image width
width = image.shape[1]
boxes[:, [0, 2]] = width - boxes[:, [2, 0]]
return image, boxes
def resize_and_pad_image(
image, min_side=800.0, max_side=1333.0, jitter=[640, 1024], stride=128.0
):
image_shape = np.array(image.shape[:2], dtype=np.float32)
if jitter:
min_side = np.random.uniform(jitter[0], jitter[1])
ratio = min_side / np.min(image_shape)
if ratio * np.max(image_shape) > max_side:
ratio = max_side / np.max(image_shape)
image_shape = (image_shape * ratio).astype(np.int32)
image = np.array(cv2.resize(image, (image_shape[1], image_shape[0])))
padded_image_shape = (
(np.ceil(image_shape / stride) * stride).astype(np.int32))
padded_image = np.zeros(
(padded_image_shape[0], padded_image_shape[1], 3), dtype=np.float32)
padded_image[:image_shape[0], :image_shape[1]] = image
return padded_image, image_shape, ratio
def preprocess_data(image, boxes, cls_ids):
def xyxy_to_cxcywh(boxes):
"""
Convert bounding boxes from (x_min, y_min, x_max, y_max) format
to (x_center, y_center, width, height) format.
Args:
- boxes: A numpy array with shape `(num_boxes, 4)` representing bounding boxes
with coordinates in (x_min, y_min, x_max, y_max) format.
Returns:
- A numpy array with boxes in (x_center, y_center, width, height) format.
"""
# Compute the center of the boxes (x_center, y_center)
x_center = (boxes[:, 0] + boxes[:, 2]) / 2
y_center = (boxes[:, 1] + boxes[:, 3]) / 2
# Compute the dimensions (width, height) of the boxes
width = boxes[:, 2] - boxes[:, 0]
height = boxes[:, 3] - boxes[:, 1]
# Concatenate results to get the final output in (x_center, y_center, width, height) format
return np.stack([x_center, y_center, width, height], axis=-1)
def cxcywh_to_xyxy(boxes):
"""
Convert boxes from (x_center, y_center, width, height) format
to (x_min, y_min, x_max, y_max) format.
Args:
- boxes: A numpy array with shape `(num_boxes, 4)` representing bounding boxes
with coordinates in (x_center, y_center, width, height) format.
Returns:
- A numpy array with boxes in (x_min, y_min, x_max, y_max) format.
"""
x_center, y_center = boxes[:, 0], boxes[:, 1]
width, height = boxes[:, 2], boxes[:, 3]
x_min = x_center - width / 2
y_min = y_center - height / 2
x_max = x_center + width / 2
y_max = y_center + height / 2
return np.stack([x_min, y_min, x_max, y_max], axis=-1)
boxes = cxcywh_to_xyxy(boxes)
image, boxes = random_flip_horizontal(image, boxes)
image, image_shape, _ = resize_and_pad_image(image)
boxes = np.stack(
[
boxes[:, 0] * image_shape[1],
boxes[:, 1] * image_shape[0],
boxes[:, 2] * image_shape[1],
boxes[:, 3] * image_shape[0],
],
axis=-1,
)
boxes = xyxy_to_cxcywh(boxes)
return image, boxes, cls_ids
class COCODataset(Dataset):
def __init__(self, annotation_file, image_dir):
with open(annotation_file, 'r') as f:
self.coco_annotations = json.load(f)
self.image_dir = image_dir
self.image_ids = [item["id"]
for item in self.coco_annotations["images"]]
def __len__(self):
return len(self.image_ids)
def __getitem__(self, idx):
image_info = [image for image in self.coco_annotations["images"]
if image["id"] == self.image_ids[idx]][0]
annotations = [ann for ann in self.coco_annotations["annotations"]
if ann["image_id"] == self.image_ids[idx]]
image = cv2.imread(os.path.join(
self.image_dir, image_info["file_name"]))
# xywh
boxes = np.array([ann["bbox"]
for ann in annotations], dtype=np.float32)
cls_ids = np.array([ann["category_id"]
for ann in annotations], dtype=np.int32)
image, boxes, cls_ids = preprocess_data(image, boxes, cls_ids)
image = to_tensor(image)
boxes = torch.from_numpy(boxes)
cls_ids = torch.from_numpy(cls_ids)
target = {
"boxes": boxes,
"cls_ids": cls_ids
}
return image, target
class LabelEncoder:
def __init__(self):
self._anchor_box = AnchorBox()
self._box_variance = torch.tensor([0.1, 0.1, 0.2, 0.2])
def _match_anchor_boxes(self, anchor_boxes, gt_boxes, match_iou=0.5, ignore_iou=0.4):
iou_matrix = compute_iou(anchor_boxes, gt_boxes)
max_iou, matched_gt_idx = iou_matrix.max(1)
positive_mask = max_iou >= match_iou
negative_mask = max_iou < ignore_iou
ignore_mask = ~(positive_mask | negative_mask)
return matched_gt_idx, positive_mask.float(), ignore_mask.float()
def _compute_box_target(self, anchor_boxes, matched_gt_boxes):
box_target = torch.cat(
[
(matched_gt_boxes[:, :2] -
anchor_boxes[:, :2]) / anchor_boxes[:, 2:],
torch.log(matched_gt_boxes[:, 2:] / anchor_boxes[:, 2:])
], dim=-1
)
box_target = box_target / self._box_variance
return box_target
def _encode_sample(self, image_shape, gt_boxes, cls_ids):
anchor_boxes = self._anchor_box.get_anchors(
image_shape[1], image_shape[2])
cls_ids = cls_ids.float()
matched_gt_idx, positive_mask, ignore_mask = self._match_anchor_boxes(
anchor_boxes, gt_boxes)
matched_gt_boxes = gt_boxes[matched_gt_idx]
box_target = self._compute_box_target(anchor_boxes, matched_gt_boxes)
matched_gt_cls_ids = cls_ids[matched_gt_idx]
cls_target = torch.where(positive_mask != 1.0,
torch.tensor(-1.0), matched_gt_cls_ids)
cls_target = torch.where(
ignore_mask == 1.0, torch.tensor(-2.0), cls_target)
cls_target = cls_target.unsqueeze(-1)
label = torch.cat([box_target, cls_target], dim=-1)
return label
def encode_batch(self, batch_images, gt_boxes, cls_ids):
batch_size = len(batch_images)
labels = []
for i in range(batch_size):
label = self._encode_sample(
batch_images[i].shape, gt_boxes[i], cls_ids[i])
labels.append(label)
return batch_images, labels
def collate_fn(batch):
return tuple(zip(*batch))
train_dataset = COCODataset(annotation_file="balloon/train/train_annotations.json",
image_dir="balloon/train/")
train_loader = DataLoader(train_dataset, batch_size=2,
shuffle=True, collate_fn=collate_fn)
net = RetinaNet(num_classes=1)
for batch_images, targets in train_loader:
gt_boxes = [item["boxes"] for item in targets]
cls_ids = [item["cls_ids"] for item in targets]
targets = {
"gt_boxes": gt_boxes,
"cls_ids": cls_ids
}
out = net(batch_images, targets)
# 以下略
break
参考文献
-
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár, "ocal Loss for Dense Object Detection," https://arxiv.org/abs/1708.02002
-
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie, "Feature Pyramid Networks for Object Detection
," https://arxiv.org/abs/1612.03144 -
Zhengxia Zou, Keyan Chen, Zhenwei Shi, Yuhong Guo, Jieping Ye, "Object Detection in 20 Years: A Survey," https://arxiv.org/abs/1905.05055
-
Srihari Humbarwadi, "Object Detection with RetinaNet," https://keras.io/examples/vision/retinanet/
-
二段階物体検出器では、一段目で物体候補のアンカーを1〜2k個に絞り込み、さらに学習時には背景のサンプルの大部分をフィルタリングアウトします。対照的に、一段階物体検出器は、画像全体の空間的位置、スケール、アスペクト比を密に網羅する、約100kという大量の物体候補を列挙することが多いです。 ↩