Info
- タイトル:Conditional Convolutions for Instance Segmentation
- カンファ:ECCV2020
- 著者:Zhi Tian, Chunhua Shen, Hao Chen
- 論文:https://arxiv.org/abs/2003.05664
- プロジェクトページ:https://github.com/aim-uofa/AdelaiDet
概要
- Mask R-CNN ではROIを計算した後、すべてのROIは同一のネットワークを通してセグメンテーションされていた。本手法では検出したインスタンスに応じてネットワークを動的に切り替えることによって、ネットワークからROIを取り除く。
- 本手法では、
- インスタンス分割は完全な畳み込みネットワークによって解決されるため、ROIの切り出しが不要になる。特徴マップをリサイズする必要がないため、より正確なエッジを持つ高解像度のインスタンスマスクが得られる。
- 動的に生成される条件付き畳み込みの容量が大幅に改善されたため、マスクヘッドを非常にコンパクトにすることができ、推論を大幅に高速化する。
特徴マップをリサイズする必要がないため、より正確なエッジを持つ高解像度のインスタンスマスクが得られ
背景
- Mask R-CNN には欠点がある。
- boxがx軸とy軸に沿った長方形のため、不規則な形状の物体では検出したい物体以外の物体もboxに入り込む可能性がある。
- セグメンテーションを行うヘッドに比較的大きな受容野が必要になり、weightのパラメータが多くなるため検出したインスタンスが多いと推論時間が長くなる。
- バッチ計算でテンソルのサイズを合わせるために、ROI Alignで高さと幅を同じ大きさにPoolingする(28×28)が、インスタンスのサイズが大きい場合、セグメンテーションの解像度が下がることになる。
- インスタンスセグメンテーションは、精度を出しているほとんどの手法がインスタンスの区別にROIを使用している。本論文では、instance-sensitive convolution filters と特徴量マップに付加される相対座標を用いて、位置情報を利用し、ROIを使用しない手法を提案する。ROIを使わないことによって、セグメンテーションで強力な手法であるFCNを採用できる。
- 本手法はdynamic filtering networksとCondConv にインスパイアされている。
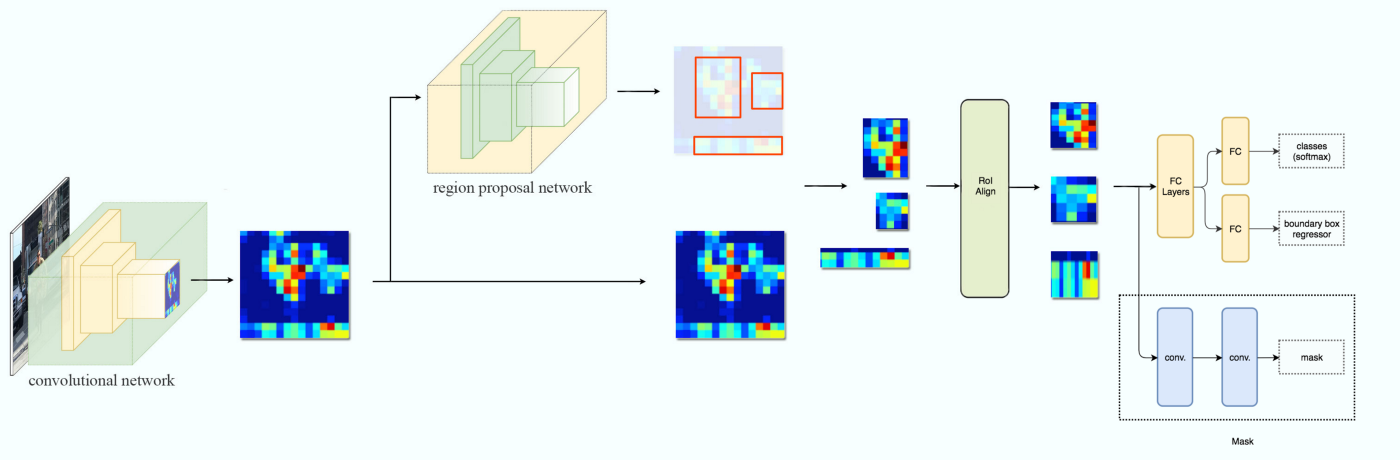 ↑Mask-RCNNのネットワーク。下記リンクから引用。
↑Mask-RCNNのネットワーク。下記リンクから引用。

↑FCOSのネットワーク。下記リンクから引用。

↑FCOSで使われているFPNのネットワーク。下記リンクから引用。
手法

gound truth は集合 $\{ (M_i, c_i) \}$ で、$M_i\in\{0,1\}^{H\times W}$は$i$番目のインスタンスに対するマスク、$c_i$は$i$番目のインスタンスのクラスである。クラスは$C$個で、COCOの場合は80個である。
画像はbackbornに入力され、各レイヤーの特徴マップ$(C3,C4,C5)$が得られる。これらの特徴マップに対しラテラル接続を用いて特徴マップ$(P3,P4,P5,P6,P7)$をつくる。$P_i$時点のダウンサンプリングレイショは(8, 16, 32, 64 ,128)である。
これらの各特徴マップ$(P3,P4,P5,P6,P7)$をhead(解像度を変えないConv)に通し、
- ピクセル単位のクラス分類確率 $\boldsymbol{p}_{x,y} \in H^{(P_i)}\times W^{(P_i)} \times [0,1]^{C}$
- ピクセル単位のフィルターパラメーター(コントローラーの出力) $\boldsymbol{\theta}_{x,y} \in H^{(P_i)}\times W^{(P_i)} \times [0,1]^{N}$
- ピクセル単位のbox回帰 $\boldsymbol t_{x,y}=(l,t,r,b)_{x,y} \in H^{(P_i)}\times W^{(P_i)} \times \mathbb{R}^4$
- ピクセル単位の中心度$\sqrt{\frac{\mathrm{min}(l,r)}{\mathrm{max}(l,r)}\times \frac{\mathrm{min}(t,b)}{\mathrm{max}(t,b)}}\Big|_{x,y}\in H^{(P_i)}\times W^{(P_i)} $
を計算する。ここで、$H^{(P_i)},W^{(P_i)}$は各特徴マップ$P_i$の高さと幅である。$N$はMask FCN headのConv層のパラメータ数であり、Mask FCN headのConv層はoutputチャンネル数が8(最後は1)でカーネルが$1\times 1$のConvが3層なので、後に説明するセグメンテーションマスクのチャンネル数$(C_{\mathrm{mask}}+2)$を用いると、
- weight: $(C_{\mathrm{mask}}+2)\times 8 +8\times 8 + 8\times 1$
- bias: $8 + 8 + 1$
- weight + bias: $8\times C_{\mathrm{mask}} + 105 = N$
となる。
一方で、$P3$からセグメンテーションのマスク$F_{\mathrm{mask}} \in H_{\mathrm{mask}} \times W_{\mathrm{mask}}\times C_{\mathrm{mask}}$を計算する。このマスクに、各ピクセルが元の画像のどの位置$(x,y)$に対応するかを表す相対座標$O_{x,y} \in H^{(P_3)}\times W^{(P_3)} \times 2$をチャンネル方向に結合して、マスク$\tilde F_{\mathrm{mask}} \in H_{\mathrm{mask}} \times W_{\mathrm{mask}}\times (C_{\mathrm{mask}}+2)$を計算する。$\tilde F_{\mathrm{mask}}$はMask FCN headに入力され、コントローラーの出力をカーネルパラメータに持つConvで畳み込まれる。
ネットワークのforward全体の流れをまとめる。
- 画像をFPN(backbornを含む)に入力して各層で特徴量$P_i$を抽出する。
- $P_i$を畳み込み、特徴量マップのピクセル単位で(クラス分類確率, フィルターバラメーター, box回帰, 中心度)を出力する。
- クラス分類確率が大きいピクセルが物体の検出候補になるが、素のままだと候補が大量に検出されてしまう。クラス分類確率に中心度をかけて補正されたクラス分類確率が大きいものを閾値で残し、物体の中心に近い検出候補のみを残す。
- それぞれの候補位置に対応するフィルターバラメーターを、フィルターバラメーターに持つMask FCN head(Conv層)を候補位置の数だけ用意する。
- $P3$に対して$128\times3\times3$のConvを4つ畳み込み、$F_{\mathrm{mask}}$を出力する。
- $F_{\mathrm{mask}}$の各ピクセルが元の画像のどの位置$(x,y)$に対応するかを表す相対座標$O_{x,y} \in H'\times W' \times 2$をチャンネル方向に結合して、マスク$\tilde F_{\mathrm{mask}} \in H_{\mathrm{mask}} \times W_{\mathrm{mask}}\times (C_{\mathrm{mask}}+2)$を計算する。
- $\tilde F_{\mathrm{mask}}$を手順4で用意したConvで畳み込み、検出候補数分のマスクを出力する。これがインスタンスセグメンテーションに対応する。
- Mask FCN headの出力は入力画像の半分のサイズになっているため、ground truthを1/2にしてサイズを合わせて損失を計算する。
このモデルはコンセプトとしてはbox headを不要とすることができるが、boxを活用したNMSを行うと推論が高速化されるので、NMSを使用するためだけにboxの情報を活用する。手順3で、さらにboxを用いたNMSを行って候補を絞る。
損失関数は次の式で与えられる。
\begin{align}
L &= L_{\mathrm{fcos}} + L_{\mathrm{mask}} \\
L_{\mathrm{fcos}}(\{\boldsymbol p_{x,y}, \boldsymbol t_{x,y}\})
&= \frac{1}{N_{\mathrm{pos}}}\sum_{x,y} L_{\mathrm{cls}}(\boldsymbol p_{x,y}, c^{\mathrm{gt}}_{x,y})
+ \frac{1}{N_{\mathrm{pos}}}\sum_{x,y} \mathbb{1}_{\{c_{x,y}>0\}} L_{\mathrm{reg}}(\boldsymbol t_{x,y},\boldsymbol t^{\mathrm{gt}}_{x,y}) \\
L_{\mathrm{mask}}(\{ \boldsymbol \theta_{x,y} \}) &= \frac{1}{N_{\mathrm{pos}}}\sum_{x,y} \mathbb{1}_{\{c_{x,y}>0\}} L_{\mathrm{dice}}(\mathrm{MaskHead}(\tilde F_{\mathrm{mask}};\boldsymbol \theta_{x,y}), M^{\mathrm{gt}}_{x,y})
\end{align}
$N_{\mathrm{pos}}$は画像内で検出された候補の数。$L_{\mathrm{cls}}$はfocal loss。$L_{\mathrm{reg}}$はIoUの負の対数。$M^{\mathrm{gt}}_{x,y} \in \{0,1\}^{H\times W\times C}$は高さ・幅・クラスの各ピクセルのマスクのground truth。
評価

Mask-RCNNを超える性能を記録。

他の手法と比較して細部まできれいなマスクを作成できている。
まとめと感想
- アンカー不要の物体検出を活用してとROI Align不要のインスタンスセグメンテーションを実現。FCNとFPNで様々なスケールにも対応できるようにし、ROI Alignを使わず情報量を落とさないことでセグメンテーションの精度を上げている。
- セグメンテーションはいかにFCNを使えるようにするかが肝になりそう。
- 検出候補で条件づけてモデルを動的に変化させる手法は他にも応用が広そう。