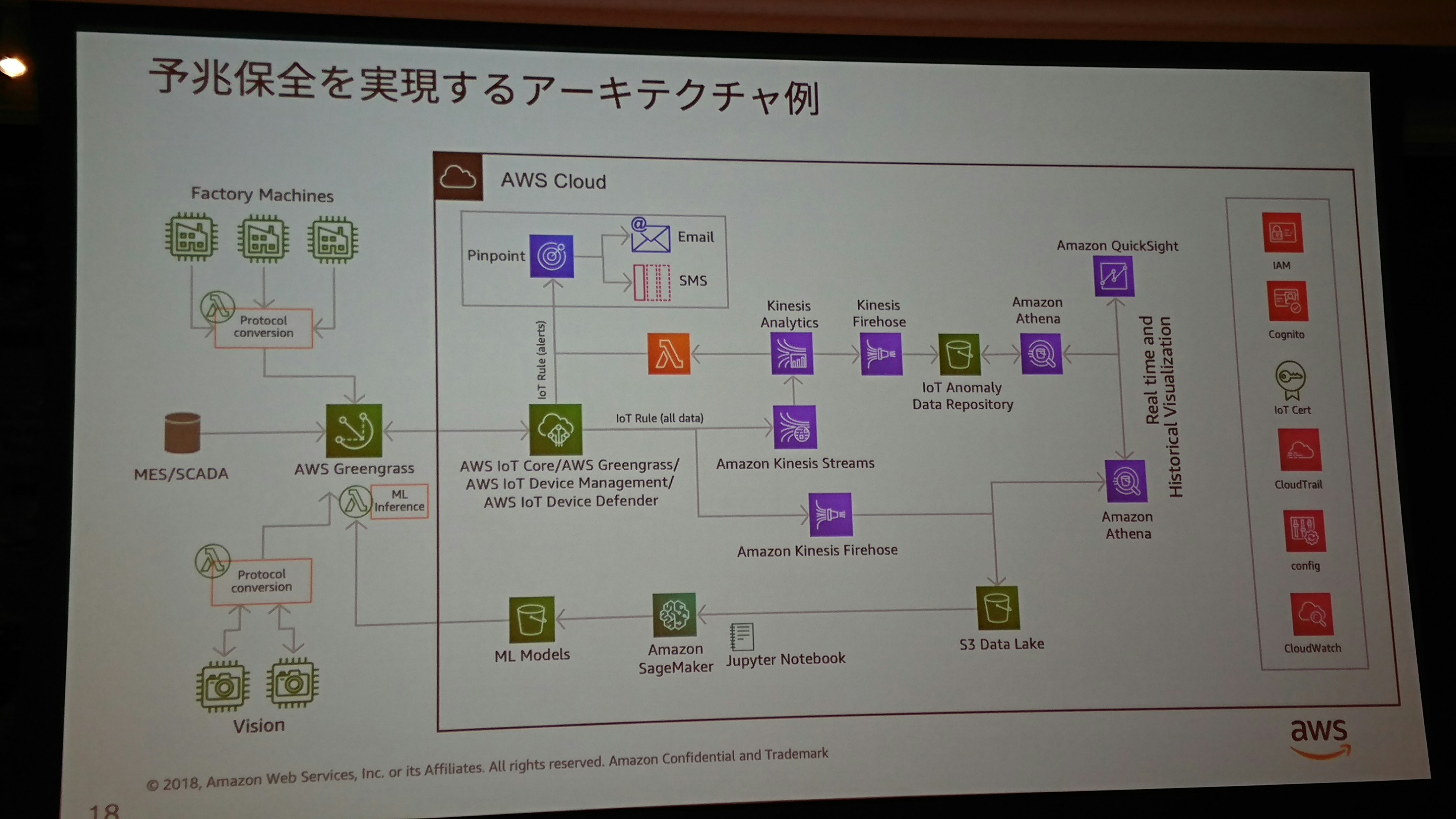
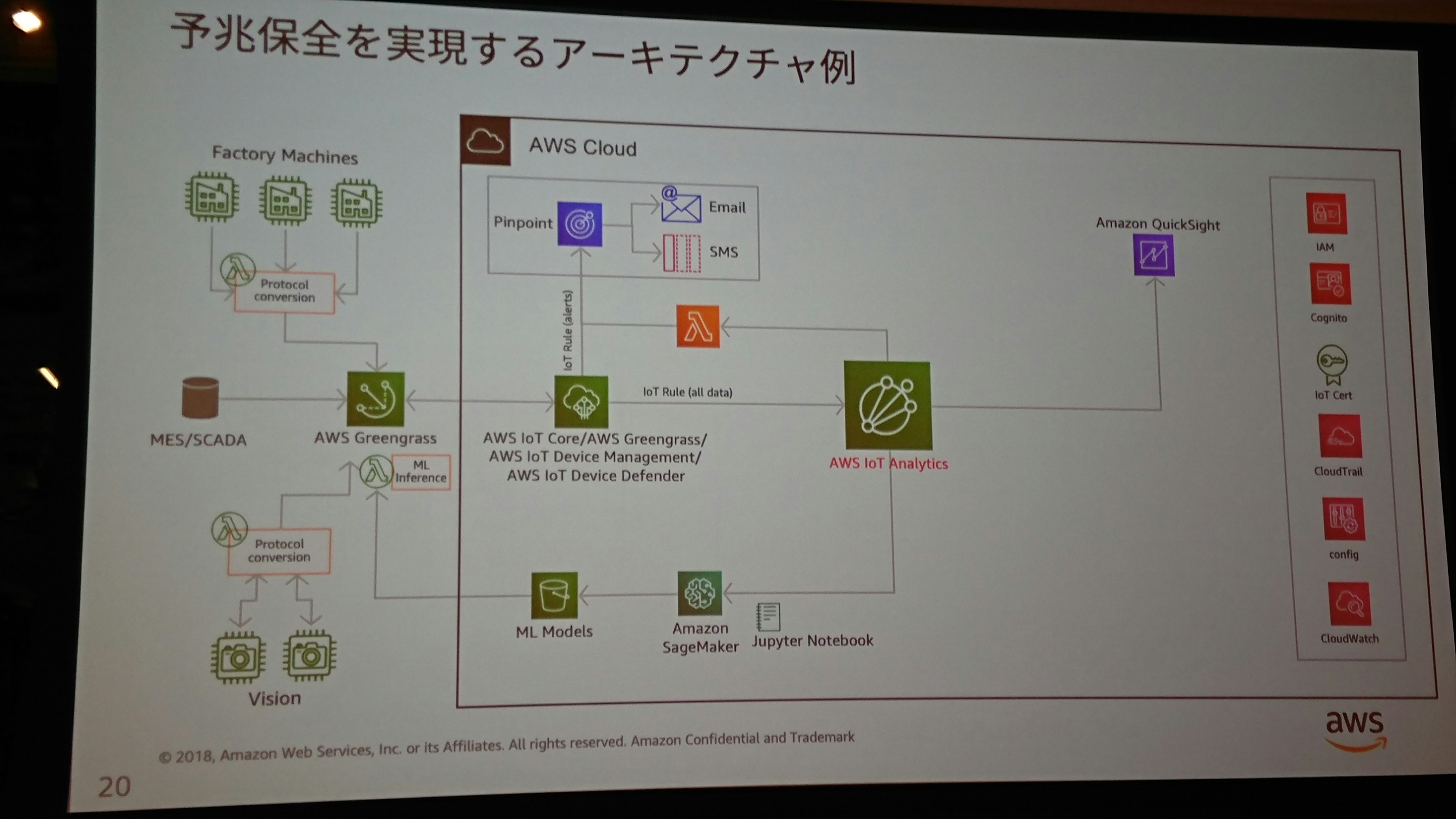
はじめに
10/2 (水) 18:30-21:00 IoT@Loft ハンズオン - スマートファクトリー IoT基盤構築プロトタイピングに参加しましたので、質問等をメモしました。
ハンズオン
ハンズオンは手順書を配布して各自自習、AWSの方が質問等を受け付けるという形式でした。
やったことは下の写真の通りです。
- 本物のセンサの代わりにCloud9を擬似センサとして、greengrassをインストール、Lambdaをエッジにデプロイしてデータの送信を行います。
- IoT CoreをGWにして、Kinesis経由でElasticsearchにデータを格納、kibanaでリアルタイム可視化します。
- AWS IoT Analisysでデータセットを用意し、QuickSightでBI(ハンズオン外)可視化をします。
- SageMakerで機械学習モデルを作成し、エッジにデプロイします。
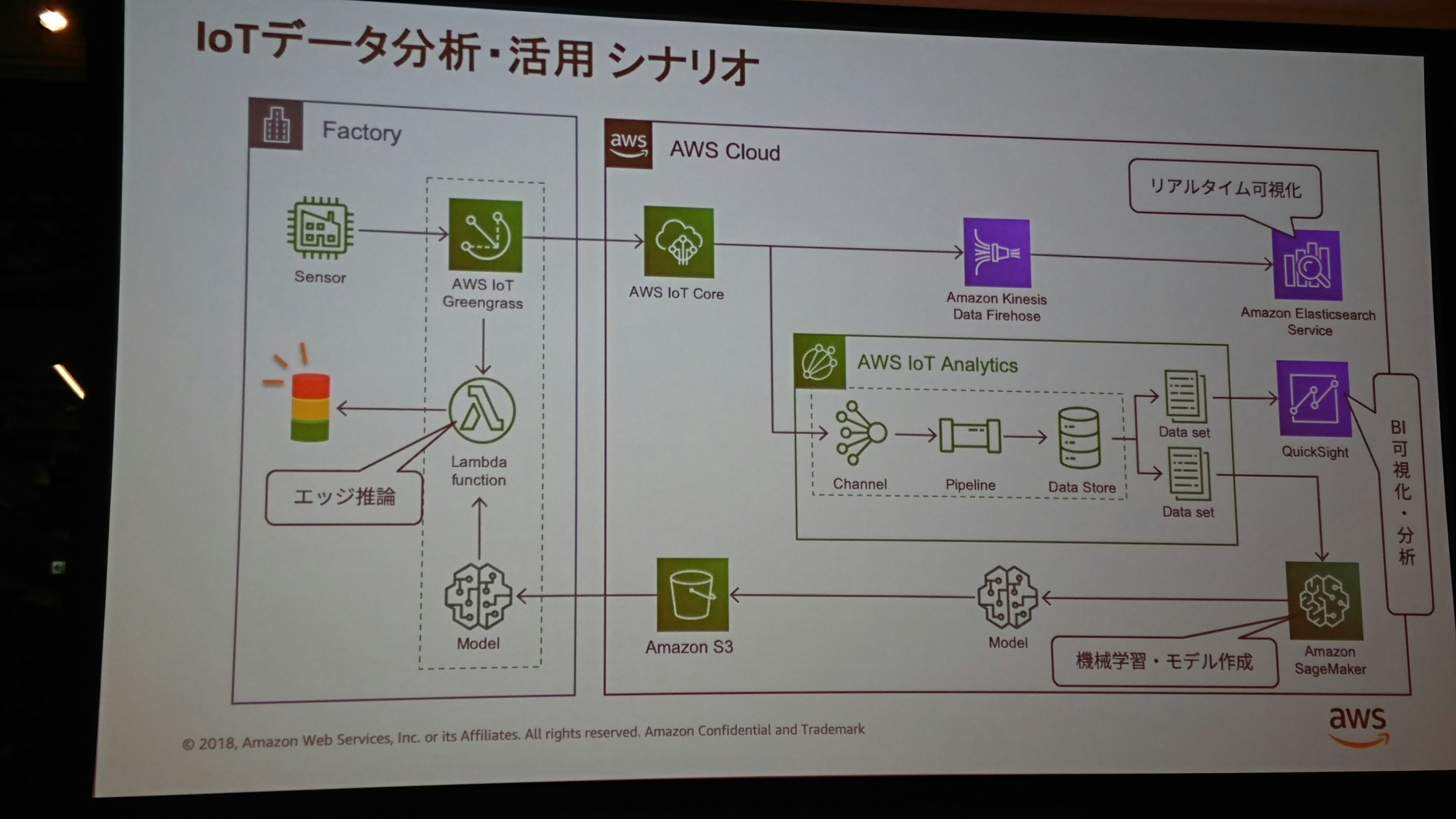
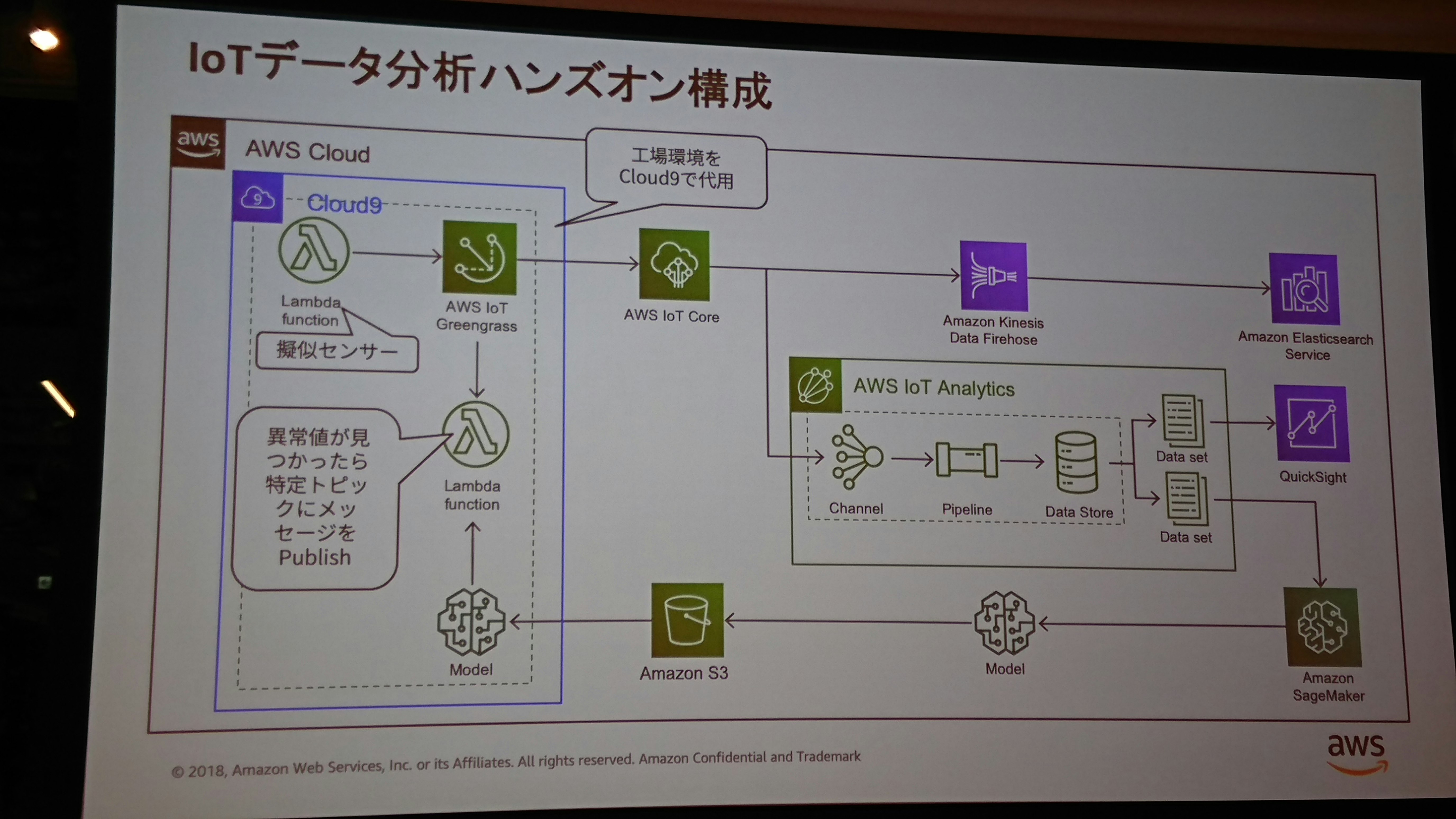

下記は自分がした質問です。
GREENGRASS グループのリソースはただのファイル送信機能?
モデルのファイルを送信する機能。他のファイルも送信できるかもしれないが、デバイスのファイル置き換えなどはシャドウを使用したほうが良い。
DynamoDB は Kinesis Data Firehose が使えない?
現時点では未対応。
DynamoDBはスケールするので Kinesis Data Firehose を使用しなくてもある程度問題ない。
データが大量になってきたらロストの可能性があるので Kinesis Data Streams でバルク処理したデータを Lambda で分割する処理をする。
topicを分けるベストプラクティスは?複数センサにどう対応する?
センサごとに分けても良い。topicの名前空間は7階層まで付けられるので、ある程度の区分分けができる。
特にデータ送信と操作系では分けた方が良い。
DynamoDBで複数のキーを使用した検索をするにはどうすればいい?
基本的にはセンサIDをキーにし、検索キーをソートキーに指定するといった使い方をする。
または、ソートキーは前方一致検索が出来るので、検索の値をつないで"val1_val2_val3_val4"とすれば検索に使用できる。
または、1ドキュメントにデータをまとめるのではなく、"type"という項目をつくり、センサ1の"location"、"kind"のように情報を分散して格納することもできる。
Amazon API Gateway と AWS Lambda でAPIを作る際、AWS Lambdaはリソース単位でつくるか、メソッド単位まで分割するか?
メソッド単位まで分割する事が多い。数が多い場合はサーバレスフレームワークをうまく利用する。リソース単位でまとめるのも有り。
ルールクエリステートメントで「すべてのトピック」からサブスクライブするには?
ルールクエリステートメントを下記のようにする。
SELECT * FROM "#"
おわりに
データ収集から可視化、機械学習に、エッジでの推論まで盛りだくさんなハンズオンでした。
それぞれのサービスの使い方が分かったので、分析基盤を作っていけそうです。