はじめに
2020年8月〜11月に開催された海岸線の抽出コンペに参加しました。結果自体は48位と振るわなかったのですが、色々な手法を試して、自分にとってはとても勉強になったので、こちらで共有したいと思います。
参考
情報公開ポリシー
この記事はSignateの情報公開ポリシーに従って公開しています。

コンペ概要
本コンペの目的は「SAR データを用いた海岸線の抽出」です。海岸線を含む画像に対し、陸地と海の境界となる線を引くことを目的とします。
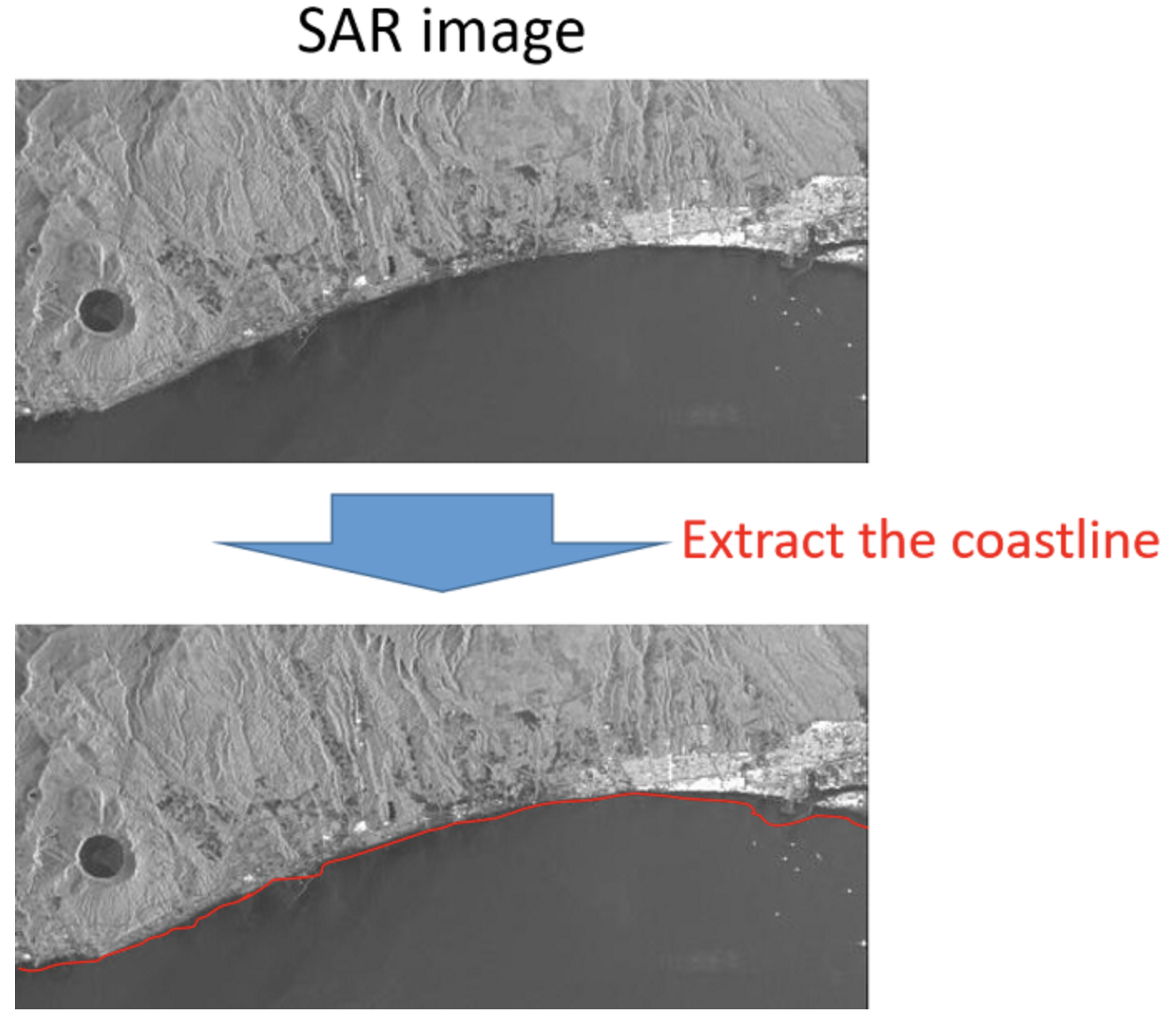
コンペの意義についてはコンペのサイトに詳しく記載されていますので、そちらを参照してください。
データ
- L バンド SAR 画像
衛星:ALOS2(JAXA)
大きさ:600×600~10000×10000(画像により異なる)
解像度:3m × 3m
HH偏波, 波長:約24cm
海岸数:17
画像数:55枚(学習用)25枚、(評価用)30枚
※偏波とは電波の性質を表す一つの指標で、電界の振動方向の向きを表します。HH は水平偏波を送信し水平偏波で受信します。
- アノテーション(学習用データに対する海岸線の座標情報) 形式:JSON
試したこと
本コンペでは、まず海と陸を分けるセグメンテーションとして、大津の二値化による海と陸の分離を試してみました。その途中でKSVDによるノイズ除去を試してみたり、グラフカットを試してみましたが、いくつかの理由により断念しました。
次に、海岸線そのものを予測するセグメンテーションを試してみました。こちらもあまりうまくいきませんでしたが、大まかには捉えており、意外な結果となりました。
画像処理による手法 ー海のセグメンテーションー
海のセグメンテーション(二値化)
ある画像の海と陸の画素分布を確認したところ、海と陸が割とはっきりと分離していることが分かりました。
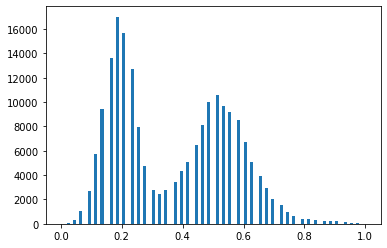
そこで、大津の二値化で海と陸が分類できるのではないかと考えました。大津の二値化は、クラス内分散を最小化し、クラス間分散を最大化するような二値分類をする方法です。
th, ret = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU)
大津の二値化を実施すると海と陸をある程度分離できるものの、まだら模様になってしまいます。

ノイズ除去
ノイズを除去するためにフィルタ処理をかけます。中央値フィルタをかけると綺麗になるものの、画像のサイズが画像ごとに異なるため、ノイズの大きさもばらばらで、画像のサイズに依存してフィルターの大きさを決める必要があり、全画像共通のパラメータでフィルタをかけるのは難しいです。
img = cv2.medianBlur(img, 31)

ここで、二値化処理の前にモルフォロジー変換と非局所平均フィルターをかけておくと、画像がなめらかになり、二値化によるノイズが小さくなる傾向があることがわかりました。モルフォロジー変換では膨張処理と収縮処理を行いノイズ除去に有効です。非局所平均フィルターはある画素に対して周囲に小さな小領域を定義し、画像中から似ているパッチを見つけ、似ているパッチの平均値を出力画像の対応する画素の画素値にする手法です。
def morphology_trans(img, trans_num=2, element=None):
"""モルフォロジー変換.
Parameters
----------
img : np.ndarray
画像.
trans_num : int, default 2
変換回数.
element : np.ndarray
近傍を指定するエレメント.
Returns
-------
img_ : np.ndarray
変換後の画像.
"""
if element is None:
element = np.ones((3, 3), np.uint8)
img_ = np.copy(img)
for _ in range(trans_num):
img_ = cv2.morphologyEx(img_, cv2.MORPH_OPEN, element)
for _ in range(trans_num):
img_ = cv2.morphologyEx(img_, cv2.MORPH_CLOSE, element)
return img_
def non_local_means_filter(img):
"""非局所平均フィルター.
Parameters
----------
img : np.ndarray
画像.
Returns
-------
img_ : np.ndarray
フィルタ処理後の画像.
"""
img_ = cv2.fastNlMeansDenoising(img, None, 7, 21, 10)
return img_
他にも、画像のノイズを低減できないか、Morphological Component Analysis (MCA) 1も試してみました。大域的 MCA では画像を分離するためにフィルターが必要になりますが、DCT の構成法は見つけられましたものの、curvelet のフィルターの構成法がわからず、大域的 MCA は断念しました。局所的 MCA はspm-image 2というライブラリを使用すると実施可能です。KSVDアルゴリズムで画像から辞書を取得します。
# ksvdのパラメータ
patch_size = (8, 8)
n_components = 8*8
transform_n_nonzero_coefs = 3
max_iter = 30

辞書のそれぞれの画像に対しアクティビティと呼ばれる、エッジっぽいかテクスチャっぽいかを表す量を計算します。閾値を決めて、テクスチャの辞書を取り除き、エッジの辞書のみで画像を再構成しました。閾値はk-meansで決定しました。

細かいノイズが除去される一方でブロックノイズが乗ってしまいました。また、スケールが大きいテクスチャを分離できていません。また、画像が大きすぎると計算量が大きくなり、処理に時間がかかるため、MCAは断念しました。
ちなみに画層は疑似カラー化しています。
# 疑似カラー化
img = cv2.applyColorMap(img, cmapy.cmap('ocean'))
領域選択
今回の画像は川も写っているため、陸地内にある川も海と同じと分類されてしまいます。

そこで、かなり楽観的なのですが、画像を占める領域で最大の領域が海だと考え、最大面積部分を海として抽出しました。汎用的な手法ではないですが、コンペなので与えられたデータに対して処理できればひとまず良いと考えて試しています。
contours = cv2.findContours(
ret, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
# 一番面積が大きい輪郭を選択する。
max_cnt = max(contours, key=lambda x: cv2.contourArea(x))
# 黒い画像に一番大きい輪郭だけ塗りつぶして描画する。
out = np.zeros_like(ret)
out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=-1)
out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=1)
正解の海岸線にかなり近い境界になったと思います。

境界線の取得
二値化に成功したあと、境界線を取得しなければならないのですが、これが意外とよくわからなかったです。初めはCanny法でエッジを取得しました。
# エッジを取得する
edges = cv2.Canny(img, 100, 100)
ただCanny法では斜めの線の部分の線が連結していない場合があり、線にポツポツと穴が空いてしまうという問題がありました。
そこでエッジ検出ではなく、輪郭検出に変えました。ただし、輪郭検出は白の領域の周囲全体を検出してしまうため、画像の端にも線を引いてしまいます。そこで、輪郭検出後、画像の端を改めて0で埋めています。
def extract_edge(y, h, w):
y_ = np.zeros_like(y)
contours = cv2.findContours(
y, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[0]
# 一番面積が大きい輪郭を選択する。
max_cnt = max(contours, key=lambda x: cv2.contourArea(x))
# 輪郭線画像を生成
img = cv2.drawContours(y_, [max_cnt], 0, 255, 1)
# 画像の端の線を削除
img[0, :] = 0
img[h-1, :] = 0
img[:, 0] = 0
img[:, w-1] = 0
return img
結論
以上の方法で画像処理を出来ないか模索したのですが、決定的な問題があり、この方向性は断念しました。
- 海と陸の画素分布にほとんど差がない場合は二値化不可能。
- 海側に欠損がある場合は「欠損とその他」の二値分類になってしまう。
例えばフォーラム掲載の画像のtrain19などは、画像全体が白っぽくなり、海と陸の画素の分布が別れておらず、ヒストグラムで可視化すると一つの山になってしまっています。このような画像に対しては大津の二値化が使用できません。
また、train09のように、海側に海側に欠損がある場合、「海と陸」で分布が別れず、「海+陸と欠損部分」で二値化されてしまうこともわかりました。インプレーティングで欠損部分と近接している画素で埋めるといった方法も試したましたが、あまりうまくいきませんでした。
dst = cv2.inpaint(img, mask, 3, cv2.INPAINT_NS)
もっと欠損部分の処理を丁寧に行えば回避できたかもしれませんが、全画像に対して共通処理はできそうにありませんでしたので、画像処理による手法は断念しました。
おまけ
ちなみに、海と陸を二値化するにあたってはGrabCutも試してみました。ただしOpenCVに実装されている GrabCut は、前景を囲むように長方形の領域を選択しなければならず、海岸線が画像の対角線上を走るような場合は海だけを囲むようにすることが出来ません。自分で実装3すれば、比較的自由に領域を選択出来るのですが、画像が大きい場合は計算量が莫大になることがわかり、実装はしませんでした。面白そうなアルゴリズムなので、いつか実装してみたいです。
ディープラーニングによる手法
海のセグメンテーション再び
はじめに、セグメンテーションを使用して海をセグメンテーションしました。海のセグメンテーションをするにあたってはlabelmeを使用しました。正解の境界をなぞるように境界線を引き、境界線がないところは自分の感覚で引いてしまいました。海側を1としてアノテーションしています。
コンペの参考資料に、過去のコンペでは画像の縮小がキーになっているという話があり、また、解像度が高い状態で海岸線付近をうまくクロップする方法が思いつかなかったため、画像全体を$(224, 224)$にリサイズしてモデリングしました。Augmentationは下記の設定で行いました。モデルはPSPNetです。
smp.PSPNet('resnet34', encoder_weights='imagenet', activation='sigmoid')
def get_transforms(is_train=True):
list_transforms = []
if is_train:
list_transforms.extend(
[
A.RandomResizedCrop(
224, 224,
scale=(0.4, 1.0),
ratio=(0.75, 1.3333333333333333),
interpolation=1,
always_apply=False,
p=1.0),
A.Rotate(
limit=90,
interpolation=1,
border_mode=4,
value=None,
mask_value=None,
always_apply=False,
p=1.0),
A.Flip(
p=0.5),
A.RandomBrightnessContrast(
brightness_limit=0.2,
contrast_limit=0.2,
brightness_by_max=True,
always_apply=False,
p=1.0),
])
else:
list_transforms.extend([
A.Resize(224, 224, interpolation=1, always_apply=False, p=1.0)
])
list_transforms.extend([
# A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], p=1),
A.pytorch.ToTensor(),
])
list_trfms = A.Compose(list_transforms)
return list_trfms
このモデルだと、川も海として検出してしまいました。画像全体に推論をかける以上、川の誤認識は避けられません。
境界線のセグメンテーション
フォーラム で境界線を直接セグメンテーションできないかというスレッドが立っていました。Petr (CZ)さんが、ポジティブな回答をしていたので、線を直接予測できるか試してみました。正直懐疑的でしたが、これを試してみることにしました。
フォーラムにあったアドバイス通り、BCEWithLogitsLossに重みをかけて学習させました。画像サイズは(448, 448)とし、モデルはUnetを使用しました。重みはピクセルの比だと、重みはおよそ1:400ですが、何度か試して1:1000くらいが良さそうでした。
このモデルだと、光のノイズなどが大きい画像だとノイズに対して予測を出してしまいました。なんとかパラメータを微調整して、このモデルで最終提出としました。
class WeightedBCEWithLogitsLoss(nn.Module):
def __init__(self, weights=None):
super().__init__()
assert len(weights) == 2
self.weights = weights
def forward(self, output, target):
output = torch.clamp(output,min=1e-8,max=1-1e-8)
if self.weights is not None:
loss = self.weights[1] * (target * torch.log(output)) + \
self.weights[0] * ((1 - target) * torch.log(1 - output))
else:
loss = target * torch.log(output) + (1 - target) * torch.log(1 - output)
return torch.neg(torch.mean(loss))
criterion = WeightedBCEWithLogitsLoss(weights=torch.Tensor([1, 1000]))
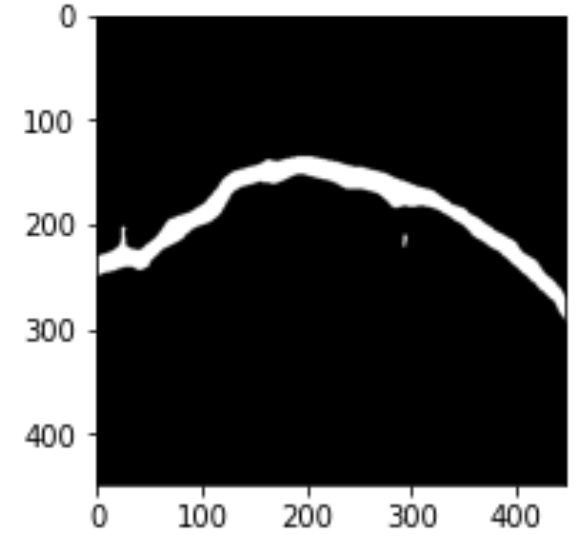
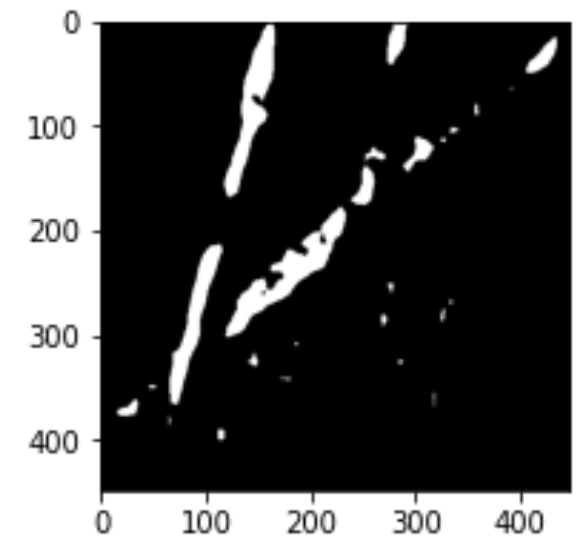
検出した海岸線は太すぎるので細くする必要があります。細線化アルゴリズムはZhang-Suenを使用して、こちらのコードを使用しました。
おまけ
以下は、使用したけど紹介しなかった諸々のコードです。汚いですが(汗)
import datetime
import gc
import glob
import json
import math
import os
import pdb
import pickle
import random
import shutil
import time
import uuid
import warnings
from datetime import timedelta
from pathlib import Path
from typing import Dict, List, Sequence, Tuple, Union
import albumentations as A
import cmapy
import cv2
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import segmentation_models_pytorch as smp
import skimage
import tifffile
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
import torchvision
from catalyst.callbacks.checkpoint import CheckpointCallback
from catalyst.callbacks.early_stop import EarlyStoppingCallback
from catalyst.dl import SupervisedRunner
from catalyst.utils import metrics
from labelme.utils import shape_to_mask
from skimage.future import graph
from sklearn.feature_extraction.image import (extract_patches_2d,
reconstruct_from_patches_2d)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from torch.autograd import Variable
from torch.nn import functional as F
from torch.nn.modules.utils import _pair, _single
from torch.optim import lr_scheduler
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torch.utils.data import DataLoader, Dataset, sampler
from torchsummary import summary
from tqdm import tqdm_notebook as tqdm
from tqdm.auto import tqdm
%matplotlib inline
warnings.filterwarnings("ignore")
def seed_everything(seed):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
# seed setting
seed = 69
seed_everything(seed)
pd.set_option('display.max_columns', 50)
pd.set_option('display.max_rows', 50)
def get_image(idx, is_train=True):
"""画像読み込み.
Parameters
----------
idx : int
画像のインデックス.
is_train : bool, default True
trainのときはTrue.
Returns
-------
img : np.ndarray
画像.
"""
if is_train:
img = cv2.imread(str(INPUT_PATH / 'train_images' / f'train_{idx:02d}.png'))
else:
img = cv2.imread(str(INPUT_PATH / 'test_images' / f'test_{idx:02d}.png'))
if img is None:
raise ValueError("File path is incorrect.")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return img
def normalize(img):
"""min-maxスケーリング.
Parameters
----------
img : np.ndarray
画像.
Returns
-------
img_ : np.ndarray
0-255にスケーリングされた画像.
"""
img_ = (img - img.min()) / (img.max() - img.min())
img_ = (img_*255).astype(np.uint8)
return img_
def get_annotaion(idx):
"""アノテーション読み込み.
Parameters
----------
idx : int
画像のインデックス.
train : bool, default True
trainのときはTrue.
Returns
-------
annotation : dict
正解アノテーション.
"""
with open( INPUT_PATH / 'train_annotations' / f'train_{idx:02d}.json', 'r') as fp:
annotation = json.load(fp)
return annotation
def create_mask2(mask, annotaion):
"""
線のアノテーション
"""
for cols, rows in np.array(annotaion['coastline_points']):
mask[rows, cols] = 1
mask_img = mask.astype(np.int)
return mask_img
class CoastlineDataset(Dataset):
def __init__(self, df, is_train=True, force=False):
self.df = df
self.transforms = get_transforms(is_train=is_train)
self.is_train = is_train
self.force = force
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
file = str(self.df.loc[idx]['data'])
img = cv2.imread(file)
if img is None:
raise ValueError("File path is incorrect.")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
mask = np.zeros(img.shape[0:2])
if self.is_train or self.force:
file = str(self.df.loc[idx]['annotation'])
with open(file, 'r') as fp:
annotation = json.load(fp)
mask = create_mask2(mask, annotation)
if self.transforms:
augmented = self.transforms(image=img, mask=mask)
img = augmented['image']
mask = augmented['mask']
return img, mask
## データの一覧を作成
def get_resolution(filepath):
img = cv2.imread(filepath)
# 画像ファイルの読み込みに失敗したらエラー終了
if img is None:
print("Failed to load image file.")
sys.exit(1)
# カラーとグレースケールで場合分け
if len(img.shape) == 3:
height, width, channels = img.shape[:3]
else:
height, width = img.shape[:2]
channels = 1
return width, height, channels
def get_train():
train_files = sorted(list((INPUT_PATH / 'train_images').iterdir()))
train_annotations = sorted(list((INPUT_PATH / 'train_annotations').iterdir()))
df_train = pd.DataFrame({'data': train_files, 'annotation': train_annotations})
height_list, width_list = [], []
for f in train_files:
width, height, channels = get_resolution(str(f))
height_list.append(height)
width_list.append(width)
df_train['height'] = height_list
df_train['width'] = width_list
return df_train
def get_test():
test_files = sorted(list((INPUT_PATH / 'test_images').iterdir()))
df_test = pd.DataFrame({'data': test_files})
height_list, width_list = [], []
for f in test_files:
width, height, channels = get_resolution(str(f))
height_list.append(height)
width_list.append(width)
df_test['height'] = height_list
df_test['width'] = width_list
return df_test
def get_model():
return smp.Unet('resnet50', encoder_weights='imagenet', activation='sigmoid')
def get_data_loader(df_train, df_test, batch_size):
train_dataset = CoastlineDataset(df_train)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
valid_dataset = CoastlineDataset(df_train[16:].reset_index(drop=True))
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
return train_loader, valid_loader
def get_optimizer(net, epochs):
optimizer = optim.Adam(net.parameters(), lr=0.0005, betas=(0.9, 0.999))
# scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[int(epochs/2), int(epochs/4*3)], gamma=0.1)
return optimizer, None #scheduler
def get_transforms(is_train=True):
list_transforms = []
if is_train:
list_transforms.extend([
A.RandomResizedCrop(448, 448,
scale=(0.4, 1.0),
ratio=(0.75, 1.3333333333333333),
interpolation=1,
always_apply=False,
p=1.0),
# A.Rotate(limit=90, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=1.0),
A.Flip(p=0.5),
A.RandomBrightnessContrast(brightness_limit=(-0.2, 0.4),
contrast_limit=0.2,
brightness_by_max=True,
always_apply=False,
p=1.0),
])
else:
list_transforms.extend([
A.Resize(448, 448, interpolation=1, always_apply=False, p=1.0)
])
list_transforms.extend([
# A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], p=1),
A.pytorch.ToTensor(),
])
list_trfms = A.Compose(list_transforms)
return list_trfms
class DfFactory():
df_train = None
df_test = None
@classmethod
def create(cls, force=False):
if force or cls.df_train is None:
cls.df_train = get_train()
cls.df_test = get_test()
return cls.df_train, cls.df_test
# Set experiment id
exp_id = str(uuid.uuid4())[:8]
print(f'Experiment Id: {exp_id}', flush=True)
# Config gpu
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# Prepare data
factory = DfFactory()
df_train, df_test = factory.create()
train_loader, valid_loader = get_data_loader(df_train, df_test, c.train_batch_size)
loaders = {"train": train_loader, "valid": train_loader}
model = get_model().to(device)
optimizer, _ = get_optimizer(model, c.epochs)
# criterion = nn.BCEWithLogitsLoss()
criterion = WeightedBCEWithLogitsLoss(weights=torch.Tensor([1, 1000]))
runner = SupervisedRunner(device=device)
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
# scheduler=scheduler,
loaders=loaders,
# model will be saved to {logdir}/checkpoints
logdir=os.path.join(c.log_dir, exp_id),
callbacks=[
CheckpointCallback(save_n_best=c.n_saved),
# EarlyStoppingCallback(
# patience=c.es_patience,
# metric="loss",
# minimize=True,
# )
],
num_epochs=c.epochs,
main_metric="loss",
minimize_metric=True,
fp16=None,
verbose=True
)
class Predictor():
def __init__(self, model, threshold, device):
self.model = model
self.threshold = threshold
self.device = device
def predict(self, img):
self.model.eval()
self.model.to(self.device)
img = img.to(self.device)
with torch.no_grad():
y = self.model(img[None, ...]).cpu().detach().numpy()
y = y.reshape(448, 448)
y = ((y > self.threshold)*255).astype('uint8')
return y
def select_max_area(mask):
contours = cv2.findContours(
mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
# 一番面積が大きい輪郭を選択する。
max_cnt = max(contours, key=lambda x: cv2.contourArea(x))
# 黒い画像に一番大きい輪郭だけ塗りつぶして描画する。
out = np.zeros_like(mask)
out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=-1)
out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=1)
return out
def predict_1file(df, ds, predictor, idx, debug=False):
img, _ = ds[idx]
y = predictor.predict(img)
# デバッグ
if debug:
plt.imshow(y, 'gray')
# 細線化
y = ZhangSuen(y).astype('uint8')*255
# 元の画像の大きさにリサイズする
row = df.iloc[idx]
h = row['height']
w = row['width']
y = cv2.resize(y, (w, h), interpolation=cv2.INTER_NEAREST)
# 細線化
y = ZhangSuen(y).astype('uint8')*255
# 図示チェック
if debug:
plt.figure(figsize=(15, 15))
plt.imshow(255-y, 'gray')
# 線の点数が30000を超えるとエラー
num_point = (y==255).sum()
print(idx, ":", num_point)
assert num_point < 30_000
ih, iw = np.where(y==255)
return list(zip(iw.tolist(), ih.tolist()))
predictor = Predictor(model, 0.5, device)
ds = CoastlineDataset(df_test, is_train=False)
dict_sub = {}
for idx in range(30):
dict_sub[f'test_{idx:02d}.tif'] = predict_1file(df_test, ds, predictor, idx)
with open('submission.json', 'w') as file:
file.write(json.dumps(dict_sub))
おわりに
以上がThe 4th Tellus Satellite Challenge:海岸線の抽出」で試した手法でした。他の方がやっていたような高解像度でクロップして予測、結合といった手法は上手いなと思いました。海と陸を含むようにどのように画像を取り出すかが鍵だったように思えます。また、解像度が高いと逆に、海と陸の境界がよくわからないように思えたのですが、ディープラーニングだと上手く拾えたということでしょうか。このあたりは上位の方の話を聞いてみたいです。