はじめに
一般に分析対象となるデータは、欠損やフォーマットの違いなどがあり、そのまま使用することができません。そこで分析の前にはデータを分析可能なデータに変換するクレンジング作業が必要となります。以下のブログでは、クレンジング作業が工数の9割を占めるとの意見もあります。
「前処理」のフォーマット共通化やOSS化はできないんだろうか
Zansaの会で話した内容は冒頭のslideshareの通りなんですが、改めてその中で口を酸っぱくして訴えたかったポイントの一つに
「データサイエンティスト=マエショリスト」
という現実を見なきゃダメだよねー、というのがありまして。これは冗談でも何でもなくて、冒頭の>slideshareでも書いてるようにうっかりすると全工数の9割が前処理*1、なんてこともあったりします。
そこで今回はこちらの参考サイトのクレンジング作業を実践してみたいと思います。
Rによるデータクリーニング実践――政府統計からのグラフ作成を例として
環境
- MacBook Pro High Sierra 10.13.6
- R 3.5.0
- RStudio Version 1.1.453 – © 2009-2018 RStudio, Inc.
- readxl 1.1.0
- tidyverse 1.2.1
- magrittr 1.5
- stringr 1.3.1
参考文献
手順
データの抽出
まず、e-Statからデータを入手します。e-Statにアクセスし、トップページの「分野から探す」をクリック、「学校基本調査」をクリックします。検索窓があるので、「男女別学校数」と入力し、検索を実行します。検索結果を「調査年月」でソートします。
ダウンロードした2017年のデータは以下のような形式になっています。ところどころ空列などが入っており、人間は見やすいのですが、機械に読み込ませるにはあまり良い形ではありません。またファイル名もsy0127.xlsxと、中身がわからない命名になっています。

また、1987年のデータを見ればわかりますが、フォーマットがファイルごとに異なります!

このようなデータをクレンジングしていきます。
手動で全てのファイルをダウンロードしても良いのですが、参考サイトの方でダウンロードしたものがまとめられていましたので、そちらを利用させていただきました。
https://github.com/fnshr/high-school-jp/tree/master/original-data
1986年から2016年のデータを使用します。
クレンジング
Rでデータを読み込みます。
> library(readxl)
> data <- read_excel("/filepath/2016.xlsx",col_names = FALSE)
> data
# A tibble: 13 x 13
X__1 X__2 X__3 X__4 X__5 X__6 X__7 X__8 X__9 X__10 X__11 X__12 X__13
<chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 79 男 女 別 学 校 数 NA NA NA NA NA NA NA NA NA NA NA NA
2 NA NA NA NA NA NA NA NA NA NA NA NA NA
3 NA 区分 NA 計 NA NA 国立 公 … NA NA 私 … NA NA
4 NA NA NA 計 本校 分校 本校 計 本校 分校 計 本校 分校
5 NA NA NA NA NA NA NA NA NA NA NA NA NA
6 NA 計 NA 4963 4872 91 15 3628 3539 89 1320 1318 2
7 NA NA NA NA NA NA NA NA NA NA NA NA NA
8 NA 男女ともにいる学校 NA 4509 4420 89 13 3570 3483 87 926 924 2
9 NA 男のみの学校 NA 125 123 2 1 19 17 2 105 105 0
10 NA 女のみの学校 NA 320 320 0 1 38 38 0 281 281 0
11 NA 生徒のいない学校 NA 9 9 0 0 1 1 0 8 8 0
12 NA NA NA NA NA NA NA NA NA NA NA NA NA
13 NA NA 1 この表は,男子校あるいは女子校という分類で… NA NA NA NA NA NA NA NA NA
空のセルだったところにはNAが入ります。
まずは、要らない行を削除しましょう。データを操作するのに便利なパッケージtidyverseを読み込みます。
> library(tidyverse)
─ Attaching packages ─────────────────────────────────────────────────────────────────────────────────────── tidyverse 1.2.1 ─
✔ ggplot2 2.2.1 ✔ purrr 0.2.5
✔ tibble 1.4.2 ✔ dplyr 0.7.6
✔ tidyr 0.8.1 ✔ stringr 1.3.1
✔ readr 1.1.1 ✔ forcats 0.3.0
─ Conflicts ───────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ─
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
警告メッセージ:
パッケージ ‘dplyr’ はバージョン 3.5.1 の R の下で造られました
tidyverseを読み込むとfilterやselect_ifといったデータを操作する関数を使えるようになります。tidyverseは様々な操作を統一的なインターフェースで利用できるように「tidy(整然とした)なツール群」を目指してパッケージを集めたもので、下記のようなパッケージを読み込みます。
- ggplot2: グラフ描画パッケージ
- dplyr: データ操作パッケージ
- tidyr: tidy dataを作るためのパッケージ
- readr: データファイル読み込みパッケージ
- purrr: 繰り返し計算を行うためのツール
- tibble: tidyverseの世界で使うデータ形式。データフレームの一種
- stringr: 文字列操作ライブラリ
- forcats: ファクタ(因子)操作ライブラリ
この他にもありますが、詳細は下記などを参考にしてください。
また、読み込み時に名前空間が衝突してコンフリクトが発生しています。filter()は元々のRのbase関数と同じ名前なので、マスクされてしまいます。filterを呼び出すと、dplyr::filter()が呼び出されます。Rのbase関数の方を呼び出す場合はstats::filter()とすれば良いです。
まずはタイトル行、注釈行および空行を削除します。表は13列あるのに対し、削除対称の行は2列しかデータが入っていません。そこで行内のNAの個数が、列数から2を引いたものより多くなるような行を削除します。
> data.result = filter(data, rowSums(is.na(data)) < ncol(data)-2)
> data.result
# A tibble: 7 x 13
X__1 X__2 X__3 X__4 X__5 X__6 X__7 X__8 X__9 X__10 X__11 X__12 X__13
<chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 NA 区分 NA 計 NA NA 国立 公 立 NA NA 私 立 NA NA
2 NA NA NA 計 本校 分校 本校 計 本校 分校 計 本校 分校
3 NA 計 NA 4963 4872 91 15 3628 3539 89 1320 1318 2
4 NA 男女ともにいる学校 NA 4509 4420 89 13 3570 3483 87 926 924 2
5 NA 男のみの学校 NA 125 123 2 1 19 17 2 105 105 0
6 NA 女のみの学校 NA 320 320 0 1 38 38 0 281 281 0
7 NA 生徒のいない学校 NA 9 9 0 0 1 1 0 8 8 0
さらに空の列を削除します。1個もデータが入っていない列を削除します。すなわち、行数とNAの数を比べて、一致しない列を削除します。
> data.result = select_if(data.result, colSums(is.na(data.result)) != nrow(data.result))
> data.result
# A tibble: 7 x 11
X__2 X__4 X__5 X__6 X__7 X__8 X__9 X__10 X__11 X__12 X__13
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 区分 計 NA NA 国立 公 立 NA NA 私 立 NA NA
2 NA 計 本校 分校 本校 計 本校 分校 計 本校 分校
3 計 4963 4872 91 15 3628 3539 89 1320 1318 2
4 男女ともにいる学校 4509 4420 89 13 3570 3483 87 926 924 2
5 男のみの学校 125 123 2 1 19 17 2 105 105 0
6 女のみの学校 320 320 0 1 38 38 0 281 281 0
7 生徒のいない学校 9 9 0 0 1 1 0 8 8 0
1、2行目の意味はそれぞれ設置者と本校分校区分ですが、データを見ると区分、NAになっています。そこでラベルを変更します。パッケージmagrittrを読み込みます。
> library(magrittr)
次のパッケージを付け加えます: ‘magrittr’
以下のオブジェクトは ‘package:purrr’ からマスクされています:
set_names
以下のオブジェクトは ‘package:tidyr’ からマスクされています:
extract
magrittrの関数inset()を使用してデータフレームのセルを書き換えます。inset()は第一引数に変更したいオブジェクトを指定し、第二、第三、、、引数にオブジェクトの位置を指定する値を、最後の引数に変更先の値を入れます。
> data.result = inset(data.result, 1, 1, value="設置者")
> data.result = inset(data.result, 2, 1, value="本校分校")
> data.result
# A tibble: 7 x 11
X__2 X__4 X__5 X__6 X__7 X__8 X__9 X__10 X__11 X__12 X__13
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 設置者 計 NA NA 国立 公 立 NA NA 私 立 NA NA
2 本校分校 計 本校 分校 本校 計 本校 分校 計 本校 分校
3 計 4963 4872 91 15 3628 3539 89 1320 1318 2
4 男女ともにいる学校 4509 4420 89 13 3570 3483 87 926 924 2
5 男のみの学校 125 123 2 1 19 17 2 105 105 0
6 女のみの学校 320 320 0 1 38 38 0 281 281 0
7 生徒のいない学校 9 9 0 0 1 1 0 8 8 0
ちなみに、magrittrのドキュメントを読むとわかりますが、inset()は"[<-"のエイリアスです。したがってmagrittrを読み込まずに下記のようにも書けます。
> data.result = "[<-"(data.result, 1, 1, value="設置者")
> data.result = "[<-"(data.result, 2, 1, value="本校分校")
また、magrittrはコマンドを連結して書くことができるパイプ演算子%>%を使えるようにするパッケージです。tidyverseを読み込んだときに、magrittrの一部を読み込んでいるので、パイプ演算子自体は使用可能ですが、magrittrを読み込むと更に強力なパイプ演算子が使えるようになります。
ところで、データはかなり整理されてきましたが、この表は列方向に変数が並んでいません。そこで転置を行います。
> data.result = t(data.result)
> data.result
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
X__2 "設置者" "本校分校" "計" "男女ともにいる学校" "男のみの学校" "女のみの学校" "生徒のいない学校"
X__4 "計" "計" "4963" "4509" "125" "320" "9"
X__5 NA "本校" "4872" "4420" "123" "320" "9"
X__6 NA "分校" "91" "89" "2" "0" "0"
X__7 "国立" "本校" "15" "13" "1" "1" "0"
X__8 "公 立" "計" "3628" "3570" "19" "38" "1"
X__9 NA "本校" "3539" "3483" "17" "38" "1"
X__10 NA "分校" "89" "87" "2" "0" "0"
X__11 "私 立" "計" "1320" "926" "105" "281" "8"
X__12 NA "本校" "1318" "924" "105" "281" "8"
X__13 NA "分校" "2" "2" "0" "0" "0"
Rでは転置を行うと、データがmatrixクラスになってしまいます。データフレームに変換します。
> data.result = as_data_frame(data.result)
> data.result
# A tibble: 11 x 7
V1 V2 V3 V4 V5 V6 V7
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 設置者 本校分校 計 男女ともにいる学校 男のみの学校 女のみの学校 生徒のいない学校
2 計 計 4963 4509 125 320 9
3 NA 本校 4872 4420 123 320 9
4 NA 分校 91 89 2 0 0
5 国立 本校 15 13 1 1 0
6 公 立 計 3628 3570 19 38 1
7 NA 本校 3539 3483 17 38 1
8 NA 分校 89 87 2 0 0
9 私 立 計 1320 926 105 281 8
10 NA 本校 1318 924 105 281 8
11 NA 分校 2 2 0 0 0
データの列名がV1,...になっていますので、正しい列名をつけます。データの1行目が列名として使えそうなので、データの1行目を列名として設定します。
※R version3までは列名を日本語のまま扱えましたが、version4から使用できないようです。その場合は次のコマンドの代わりに列名をアルファベットの文字列に変換するコマンドを実行し、以降の手順も適宜読み替えてください。参考に記事最後にスクリプト全体も掲載しています。
colnames(data.result) <- c("Establisher", "MainOrBranch", "Total", "Coeducation", "Boys", "Girls", "NoStudent")
> data.result = set_colnames(data.result, data.result[1,])
> data.result
# A tibble: 11 x 7
設置者 本校分校 計 男女ともにいる学校 男のみの学校 女のみの学校 生徒のいない学校
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 設置者 本校分校 計 男女ともにいる学校 男のみの学校 女のみの学校 生徒のいない学校
2 計 計 4963 4509 125 320 9
3 NA 本校 4872 4420 123 320 9
4 NA 分校 91 89 2 0 0
5 国立 本校 15 13 1 1 0
6 公 立 計 3628 3570 19 38 1
7 NA 本校 3539 3483 17 38 1
8 NA 分校 89 87 2 0 0
9 私 立 計 1320 926 105 281 8
10 NA 本校 1318 924 105 281 8
11 NA 分校 2 2 0 0 0
データの1行目は不要なので、削除します。
> data.result = slice(data.result, -1)
> data.result
# A tibble: 10 x 7
設置者 本校分校 計 男女ともにいる学校 男のみの学校 女のみの学校 生徒のいない学校
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 計 計 4963 4509 125 320 9
2 NA 本校 4872 4420 123 320 9
3 NA 分校 91 89 2 0 0
4 国立 本校 15 13 1 1 0
5 公 立 計 3628 3570 19 38 1
6 NA 本校 3539 3483 17 38 1
7 NA 分校 89 87 2 0 0
8 私 立 計 1320 926 105 281 8
9 NA 本校 1318 924 105 281 8
10 NA 分校 2 2 0 0 0
設置者列の文字間に不要な空白が入っているので、正規表現で削除します。
> data.result = mutate(data.result, 設置者 = str_replace_all(設置者, "\\s+", ""))
> data.result
# A tibble: 10 x 7
設置者 本校分校 計 男女ともにいる学校 男のみの学校 女のみの学校 生徒のいない学校
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 計 計 4963 4509 125 320 9
2 NA 本校 4872 4420 123 320 9
3 NA 分校 91 89 2 0 0
4 国立 本校 15 13 1 1 0
5 公立 計 3628 3570 19 38 1
6 NA 本校 3539 3483 17 38 1
7 NA 分校 89 87 2 0 0
8 私立 計 1320 926 105 281 8
9 NA 本校 1318 924 105 281 8
10 NA 分校 2 2 0 0 0
設置者列のNAに正しい値を代入します。元のエクセルデータを見てみると、設置者列の2、3行目には「計」が入ります。なぜNAになっているのかというと、元のエクセルデータではセルが結合されていますが、Rで読み込んだ際、結合が解除され、1つ目のセルにのみ値が入るからです。これを想定しているのか、便利な関数fill()があります。これはNAの部分に上の行の値を入れるという関数です。
> data.result = fill(data.result, "設置者")
> data.result
# A tibble: 10 x 7
設置者 本校分校 計 男女ともにいる学校 男のみの学校 女のみの学校 生徒のいない学校
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 計 計 4963 4509 125 320 9
2 計 本校 4872 4420 123 320 9
3 計 分校 91 89 2 0 0
4 国立 本校 15 13 1 1 0
5 公立 計 3628 3570 19 38 1
6 公立 本校 3539 3483 17 38 1
7 公立 分校 89 87 2 0 0
8 私立 計 1320 926 105 281 8
9 私立 本校 1318 924 105 281 8
10 私立 分校 2 2 0 0 0
学校の男女の区分が行で表されているので、これを列に変換します。新たに男女という列を作成し、その列の値は「計」、「男女ともにいる学校」、「男のみの学校」、「女のみの学校」、「生徒のいない学校」とします。それぞれの学校数は「学校数」という列に代入します。
> data.result = gather(data.result,key = 男女, value = 学校数,-one_of("設置者", "本校分校"))
> data.result
# A tibble: 50 x 4
設置者 本校分校 男女 学校数
<chr> <chr> <chr> <chr>
1 計 計 計 4963
2 計 本校 計 4872
3 計 分校 計 91
4 国立 本校 計 15
5 公立 計 計 3628
6 公立 本校 計 3539
7 公立 分校 計 89
8 私立 計 計 1320
9 私立 本校 計 1318
10 私立 分校 計 2
# ... with 40 more rows
合計を表すデータは、計算で出すことができるので、削除しておいたほうがむしろ扱いやすいです。「計」を含む行を削除します。
> data.result = filter_all(data.result, all_vars(!str_detect(., "計")))
> data.result
# A tibble: 20 x 4
設置者 本校分校 男女 学校数
<chr> <chr> <chr> <chr>
1 国立 本校 男女ともにいる学校 13
2 公立 本校 男女ともにいる学校 3483
3 公立 分校 男女ともにいる学校 87
4 私立 本校 男女ともにいる学校 924
5 私立 分校 男女ともにいる学校 2
6 国立 本校 男のみの学校 1
7 公立 本校 男のみの学校 17
8 公立 分校 男のみの学校 2
9 私立 本校 男のみの学校 105
10 私立 分校 男のみの学校 0
11 国立 本校 女のみの学校 1
12 公立 本校 女のみの学校 38
13 公立 分校 女のみの学校 0
14 私立 本校 女のみの学校 281
15 私立 分校 女のみの学校 0
16 国立 本校 生徒のいない学校 0
17 公立 本校 生徒のいない学校 1
18 公立 分校 生徒のいない学校 0
19 私立 本校 生徒のいない学校 8
20 私立 分校 生徒のいない学校 0
学校数の列が文字型になっているので、数値型に変換します。
> data.result = mutate(data.result, 学校数 = as.integer(学校数))
> data.result
# A tibble: 20 x 4
設置者 本校分校 男女 学校数
<chr> <chr> <chr> <int>
1 国立 本校 男女ともにいる学校 13
2 公立 本校 男女ともにいる学校 3483
3 公立 分校 男女ともにいる学校 87
4 私立 本校 男女ともにいる学校 924
5 私立 分校 男女ともにいる学校 2
6 国立 本校 男のみの学校 1
7 公立 本校 男のみの学校 17
8 公立 分校 男のみの学校 2
9 私立 本校 男のみの学校 105
10 私立 分校 男のみの学校 0
11 国立 本校 女のみの学校 1
12 公立 本校 女のみの学校 38
13 公立 分校 女のみの学校 0
14 私立 本校 女のみの学校 281
15 私立 分校 女のみの学校 0
16 国立 本校 生徒のいない学校 0
17 公立 本校 生徒のいない学校 1
18 公立 分校 生徒のいない学校 0
19 私立 本校 生徒のいない学校 8
20 私立 分校 生徒のいない学校 0
最後にこのデータが何年のものなのかを表す列を加えます。
> data.result = mutate(data.result, 年 = 2016)
> data.result
# A tibble: 20 x 5
設置者 本校分校 男女 学校数 年
<chr> <chr> <chr> <int> <dbl>
1 国立 本校 男女ともにいる学校 13 2016
2 公立 本校 男女ともにいる学校 3483 2016
3 公立 分校 男女ともにいる学校 87 2016
4 私立 本校 男女ともにいる学校 924 2016
5 私立 分校 男女ともにいる学校 2 2016
6 国立 本校 男のみの学校 1 2016
7 公立 本校 男のみの学校 17 2016
8 公立 分校 男のみの学校 2 2016
9 私立 本校 男のみの学校 105 2016
10 私立 分校 男のみの学校 0 2016
11 国立 本校 女のみの学校 1 2016
12 公立 本校 女のみの学校 38 2016
13 公立 分校 女のみの学校 0 2016
14 私立 本校 女のみの学校 281 2016
15 私立 分校 女のみの学校 0 2016
16 国立 本校 生徒のいない学校 0 2016
17 公立 本校 生徒のいない学校 1 2016
18 公立 分校 生徒のいない学校 0 2016
19 私立 本校 生徒のいない学校 8 2016
20 私立 分校 生徒のいない学校 0 2016
以上で1ファイルのクレンジングは完了です。
2016年のデータにはありませんでしたが、他の年のデータには、ハイフンおよびダッシュが含まれます。そこでそれらを0に置換します。
> data.result = mutate(data.result, 学校数 = str_replace_all(学校数, "[―-]", "0"))
スクリプト化
すべてのファイルに対し、同じ処理を行います。
エクセルのファイル名を2016.xlsxのように、西暦の値とします。フォルダ内のファイル名を取得して、ベクトルfnamesを生成します。クレンジングを行う関数extract_school_num()を用意し、ベクトルの値を一つずつ渡し、ファイルを処理してきます。処理結果をschool_numに格納します。
original-dataというフォルダにエクセルファイルを格納しているとします。まず、ファイル名を取得します。original-dataディレクトリの親ディレクトリに移動し、以下のコマンドを実行します。
xls_path <- "./original-data/"
fnames <- dir(pattern = "\\.xlsx?$", path = xls_path)
fnamesにファイル名がベクトルとして格納されました。
fnamesから要素を一つずつ抜き出しfnameに格納したとします。fnameの先頭4文字は西暦なので、変数に格納し、年の列を追加するときに使用します。
extract_school_num <- function(fname){
year <- as.integer(str_sub(fname, 1, 4))
# Excelファイルの読み込み
data <- read_excel(paste0(xls_path, fname), col_names = FALSE)
# データクリーニングの実行
data %>%
# データに対する注釈的要素の除去、空行の除去
filter(rowSums(is.na(.)) < ncol(.)-2) %>%
# 空列の除去
select_if(colSums(is.na(.)) != nrow(.)) %>%
# 変数に見出しをつける
inset(1, 1, value="設置者") %>%
inset(2, 1, value="本校分校") %>%
# 転置による行と列の入れ替え
t() %>%
as_data_frame() %>%
# 列名の設定
set_colnames(.[1,]) %>%
slice(-1) %>%
# 文字列内の余計な空白の除去
mutate(設置者 = str_replace_all(設置者, "\\s+", "")) %>%
fill("設置者") %>%
# 残った変数を列で表現する
gather(key = 男女, value = 学校数, -one_of("設置者", "本校分校")) %>%
# 合計を示すデータの削除
filter_all(all_vars(!str_detect(., "計"))) %>%
# 学校数ゼロを示すものの処理
mutate(学校数 = str_replace_all(学校数, "[―-]", "0")) %>%
mutate(学校数 = as.integer(学校数)) %>%
# 年を示すデータの追加
mutate(年 = year) -> data
return(data)
}
必要なライブラリは以下です。
# ライブラリの読み込み
library("readxl") # Excelファイルの読み込み
library("tidyverse") # データ分析
library("stringr") # 文字列処理
library("magrittr") # パイプ処理
エクセルファイルを読み込む関数read_excel()を使用するためにreadxlを読み込みます。
filterやselect_ifといった分析用関数を使用するためにtidyverseを読み込みます。
str_replace_all()などの文字列操作をする関数を使用するためにstringrを読み込みます。
また、パイプ処理を行うためにmagrittrを読み込みます。
ここで、パイプ処理について説明します。今までコンソールで処理を行ってきた際に、次のような書き方をしてきました。
data.result = select_if(data.result, colSums(is.na(data.result)) != nrow(data.result))
data.resultに処理をし再度代入しています。このように書いても良いのですが少々冗長です。そこで、パイプという演算子を使用します。
%>%
パイプの左側の値をパイプの右側の引数に渡すことができます。
x %>% f %>% g %>% h
これはxをf()に代入し、f(x)をg()に代入し、...としていく処理で、つまりh(g(f(x)))を表しています。第一引数以外でパイプの左側の値を使用する場合はドット.を使用します。すると次のように書き換えられます。
%>% select_if(colSums(is.na(.)) != nrow(.))
スクリプトでは最後に処理結果をdata変数に格納してreturnしています。
各ファイルを処理するには次のように書きます。
school_num <- map_df(fnames, extract_school_num)
map_dfは第一引数のリストの各要素を第二引数の関数に代入し、処理を走らせます。その結果をschool_numにまとめます。
可視化
以上でschool_numにクレンジングされたデータが格納されました。ここでは分析として、可視化を行います。
まず、可視化の前の準備を行います。年ごとに「女のみの学校」、「男のみの学校」それぞれの学校数を出すための処理を行います。
school_num %>%
# 下準備
group_by(男女, 年) %>%
summarise(学校数 = sum(学校数)) %>%
ungroup() %>%
filter(男女 == "女のみの学校" | 男女 == "男のみの学校") %>%
group_by()の効果を見てみましょう。コマンドラインで実行してみると、一見なにも変わっていないように見えます。
> school_num = group_by(school_num, 男女, 年)
> school_num
# A tibble: 620 x 5
# Groups: 男女, 年 [124]
設置者 本校分校 男女 学校数 年
<chr> <chr> <chr> <int> <int>
1 国立 本校 男女ともにいる学校 15 1986
2 公立 本校 男女ともにいる学校 3695 1986
3 公立 分校 男女ともにいる学校 170 1986
4 私立 本校 男女ともにいる学校 478 1986
5 私立 分校 男女ともにいる学校 4 1986
6 国立 本校 男のみの学校 1 1986
7 公立 本校 男のみの学校 120 1986
8 公立 分校 男のみの学校 4 1986
9 私立 本校 男のみの学校 272 1986
10 私立 分校 男のみの学校 3 1986
# ... with 610 more rows
しかし、# Groups: 男女, 年 [124]が表示され、グループ情報が付加されていることがわかります。このグループ情報が付加されていると、summarise()などの集計の関数を使用したときにグループごとの集計になります。
> school_num = summarise(school_num, 学校数 = sum(学校数))
>school_num
# A tibble: 124 x 3
# Groups: 男女 [?]
男女 年 学校数
<chr> <int> <int>
1 女のみの学校 1986 708
2 女のみの学校 1987 696
3 女のみの学校 1988 690
4 女のみの学校 1989 689
5 女のみの学校 1990 680
6 女のみの学校 1991 676
7 女のみの学校 1992 666
8 女のみの学校 1993 655
9 女のみの学校 1994 643
10 女のみの学校 1995 627
# ... with 114 more rows
ungroup()を実行すると、グループ情報が削除されます。summarise()後はグループ情報が冬であることと、グループ情報が付加されていると、処理が重くなることから削除を行っています。
最後に、「男女 == "女のみの学校"」または「男女 == "男のみの学校"」の絞り込みを行っています。
次にグラフを作成します。
# ggplot でグラフを描く
ggplot(aes(x = 年, y = 学校数, colour = 男女)) +
geom_line() + geom_point() +
scale_x_continuous(breaks = seq(1990, 2015, by=5), minor_breaks = 1986:2016) +
scale_y_continuous(breaks = seq(0, 900, by=100),
minor_breaks = seq(0, 900, by=10)) +
theme_bw(base_family = "HiraKakuProN-W3") +
ggtitle("日本における男子のみ・女子のみの高校(通信制除く)の数")
-
aes(x = 年, y = 学校数, colour = 男女)は軸名と、グループごとの色付けを行っています。 -
geom_line()は折れ線の追加、geom_point()は散布図の追加、scale_〜は軸の範囲の設定をしています。 -
theme_bw()は白背景に灰色のグリッドという外観を設定します。私の環境ではただのtheme_bw()ではグラフが文字化けを起こしたので、theme_bw(base_family = "HiraKakuProN-W3")として文字化けを回避しました。 -
ggtitle()はグラフのタイトルを設定します。
以上すべてをまとめると下記のスクリプトになります。
# ライブラリの読み込み
library("readxl") # Excelファイルの読み込み
library("tidyverse") # データ分析
library("magrittr") # パイプ処理
library("stringr") # 文字列処理
setwd("~/「./original-data/の親ディレクトリ」") # 初期ディレクトリの設定
xls_path <- "./original-data/" #パスの設定
fnames <- dir(pattern = "\\.xlsx?$", path = xls_path) # ファイル名の取得
extract_school_num <- function(fname){
year <- as.integer(str_sub(fname, 1, 4))
# Excelファイルの読み込み
data <- read_excel(paste0(xls_path, fname), col_names = FALSE)
# データクリーニングの実行
data %>%
# データに対する注釈的要素の除去、空行の除去
filter(rowSums(is.na(.)) < ncol(.)-2) %>%
# 空列の除去
select_if(colSums(is.na(.)) != nrow(.)) %>%
# 変数に見出しをつける
inset(1, 1, value="設置者") %>%
inset(2, 1, value="本校分校") %>%
# 転置による行と列の入れ替え
t() %>%
as_data_frame() %>%
# 列名の設定
set_colnames(.[1,]) %>%
slice(-1) %>%
# 文字列内の余計な空白の除去
mutate(設置者 = str_replace_all(設置者, "\\s+", "")) %>%
fill("設置者") %>%
# 残った変数を列で表現する
gather(key = 男女, value = 学校数, -one_of("設置者", "本校分校")) %>%
# 合計を示すデータの削除
filter_all(all_vars(!str_detect(., "計"))) %>%
# 学校数ゼロを示すものの処理
mutate(学校数 = str_replace_all(学校数, "[―-]", "0")) %>%
mutate(学校数 = as.integer(学校数)) %>%
# 年を示すデータの追加
mutate(年 = year) -> data
return(data)
}
school_num <- map_df(fnames, extract_school_num) # 全ファイルの処理結果を格納
school_num %>%
# 下準備
group_by(男女, 年) %>%
summarise(学校数 = sum(学校数)) %>%
ungroup() %>%
filter(男女 == "女のみの学校" | 男女 == "男のみの学校") %>%
# ggplot でグラフを描く
ggplot(aes(x = 年, y = 学校数, colour = 男女)) +
geom_line() + geom_point() +
scale_x_continuous(breaks = seq(1990, 2015, by=5), minor_breaks = 1986:2016) +
scale_y_continuous(breaks = seq(0, 900, by=100),
minor_breaks = seq(0, 900, by=10)) +
theme_bw(base_family = "HiraKakuProN-W3") +
ggtitle("日本における男子のみ・女子のみの高校(通信制除く)の数")
グラフは次のようになります。
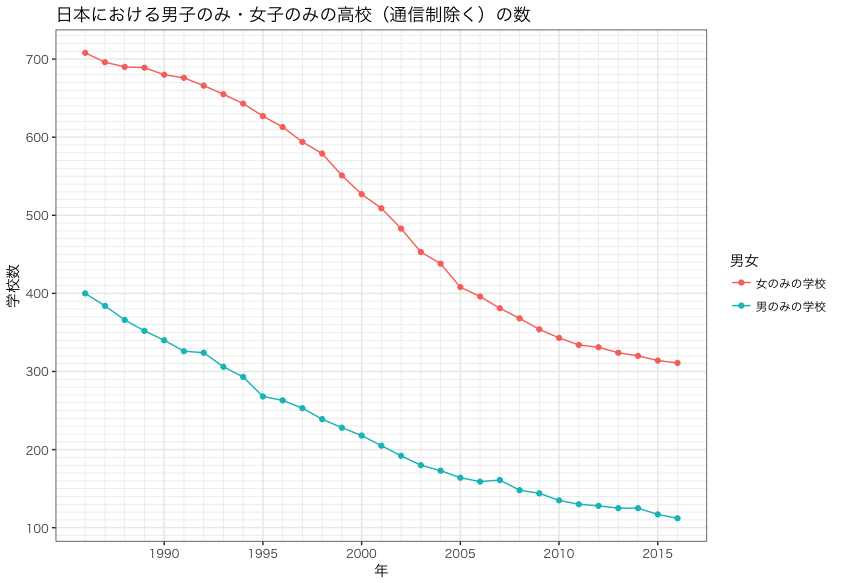
参考サイトのスクリプトは下記にありますので参照してください。
https://github.com/fnshr/high-school-jp/blob/master/high-school-jp.R
※Windows版R version4.0.1対応のスクリプトを下記に示します。破壊的変更がかなりあったようで、全角文字をうまく扱えない?みたいです。
- AWS Microsoft Windows Server 2019 Base - ami-0f1d9d91c16265769
- R 4.0.1
- RStudio 1.3.1056
- readxl 1.3.1
- tidyverse 1.3.0
- magrittr 1.5
- stringr 1.4.0
# ライブラリの読み込み
library("readxl") # Excelファイルの読み込み
library("tidyverse") # データ分析
library("magrittr") # パイプ処理
library("stringr") # 文字列処理
setwd("~/「./original-data/の親ディレクトリ」") # 初期ディレクトリの設定
xls_path <- "./original-data/" #パスの設定
fnames <- dir(pattern = "\\.xlsx?$", path = xls_path) # ファイル名の取得
extract_school_num <- function(fname){
year <- as.integer(str_sub(fname, 1, 4))
# Excelファイルの読み込み
data <- read_excel(paste0(xls_path, fname), col_names = FALSE)
# データクリーニングの実行
data %>%
# データに対する注釈的要素の除去、空行の除去
filter(rowSums(is.na(.)) < ncol(.)-2) %>%
# 空列の除去
select_if(colSums(is.na(.)) != nrow(.)) %>%
# 変数に見出しをつける
inset(1, 1, value="設置者") %>%
inset(2, 1, value="本校分校") %>%
# 転置による行と列の入れ替え
t() %>%
as_data_frame() %>%
# 列名の設定
`colnames<-`(c("Establisher", "MainOrBranch", "Total", "Coeducation", "Boys", "Girls", "NoStudent")) %>%
# set_colnames(.[1,]) %>%
slice(-1) %>%
# 文字列内の余計な空白の除去
mutate(Establisher = str_replace_all(Establisher, "\\s+", "")) %>%
fill("Establisher") %>%
# 残った変数を列で表現する
gather(key = "BoysOrGirls", value = "Total", -one_of("Establisher", "MainOrBranch")) %>%
# 合計を示すデータの削除
filter_all(all_vars(!str_detect(., "計"))) %>%
filter_all(all_vars(!str_detect(., "Total"))) %>%
# 学校数ゼロを示すものの処理
# mutate(Total = str_replace_all(Total, "[―-]", "0")) %>%
mutate(Total = as.integer(Total)) %>%
replace(is.na(.), 0) %>%
# 年を示すデータの追加
mutate(year = year) -> data
return(data)
}
school_num <- map_dfr(fnames, extract_school_num) # 全ファイルの処理結果を格納
school_num %>%
# 下準備
group_by(BoysOrGirls, year) %>%
summarise(Total = sum(Total)) %>%
ungroup() %>%
filter(BoysOrGirls == "Girls" | BoysOrGirls == "Boys") %>%
# ggplot でグラフを描く
ggplot(aes(x = year, y = Total, colour = BoysOrGirls)) +
geom_line() + geom_point() +
scale_x_continuous(breaks = seq(1990, 2015, by=5), minor_breaks = 1986:2016) +
scale_y_continuous(breaks = seq(0, 900, by=100),
minor_breaks = seq(0, 900, by=10)) +
theme_bw(base_family = "HiraKakuProN-W3") +
ggtitle("日本における男子のみ・女子のみの高校(通信制除く)の数")
おわりに
今回は参考サイト「Rによるデータクリーニング実践――政府統計からのグラフ作成を例として」のクレンジングを行ってみました。
全ファイル共通で行えるクレンジング処理にするためには、全データの確認をクレンジングのテストを行う必要があるので、実際の現場ではもっと苦労するのだろうな〜という感想です。